











ニュース
NVIDIA,「GeForce GTX 750 Ti&GTX 750」発表。新世代GPUアーキテクチャ「Maxwell」第1弾の詳細をまとめてみた
 |
そのため,「じゃあいいや」と思うかもしれないが,ちょっと待ってほしい。というのも,今回のGTX 750 TiとGTX 750は,NVIDIAの新世代GPUアーキテクチャ「Maxwell」(マクスウェル)を採用した,同社にとってのマイルストーン的な意味を持つGPUだからである。
Maxwellは,Tesla,Fermi,Keplerと続いてきたCUDA対応のGPUアーキテクチャ,第4世代モデル。いつものNVIDIAなら,新世代のGPUアーキテクチャとなれば,ハイエンド市場向けモデルを華々しく市場投入してくるところが,Maxwellはエントリーミドルクラスからスタートを切ってきたのも印象的だ。大きな打ち上げ花火を好むNVIDIAからすると,むしろそちらのほうがビッグニュースかもしれない。
本稿では,GTX 750 TiおよびGTX 750の製品概要と,発表時点で明らかになっているMaxwellアーキテクチャの概要をまとめてお伝えしよう。
150ドル以下の価格帯に投入される
第1世代Maxwell,GTX 750 Ti&GTX 750
というわけで,まずは新製品の概要を押さえておきたい。
NVIDIAのポジショニングによれば,今回のGeForce GTX 750シリーズ2モデルは,「GeForce GTX 650 Ti」(以下,GTX 650 Ti)を置き換える製品となっている。「GeForce GTX 650 Ti BOOST」(以下,GTX 650 TiB)はどこへ消えたのかと思うかもしれないが,GTX 650 TiBは2013年の時点で製造終了になっているため,こういう表現になったとのことである。
 |
 |
さて,そんなGeForce GTX 750シリーズだが,採用されるGPUコアは「GM107」となっている。「GM」は「GeForce Maxwell」の略。GPU上の刻印は,GTX 750 Tiが「GM107-400-A2」,GTX 750が「GM107-300-A2」だった。
製造に用いられたのはTSMCの28nm HP(HP:High Performance)プロセス技術。つまりはKeplerと同じだ。トランジスタ数は18億7000万,ダイサイズは148mm2となっている。
 |
 |
 |
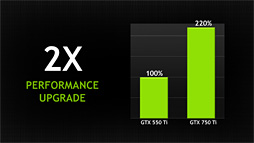
もっとも,GM107という名称からするに,GPUコア的にはKepler世代における「GK107」の後継ともいえる。GK107のフルスペックだとCUDA Core数は384基なので,そちらと比較した場合,GM107ではシェーダプロセッサの規模は約67%増えたともいえるだろう。
GTX 750 TiとGTX 750はいずれも,Kepler世代に引き続き,GPUの自動クロックアップ機能「GPU Boost 2.0」に対応。両製品とも,リファレンスではベースクロック1
 |
 |
 |
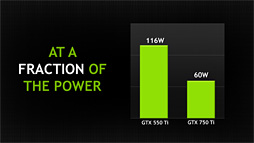
GTX 650 TiBのTDPは134W,GTX 650 Tiは110Wだったので,GTX 750 Tiは置き換え対象の半分以下,GTX 750はきっかり半分にまで,大幅な低消費電力を果たしたことになる。
 |
 |
 |
 |
 |
搭載グラフィックスカードの北米市場におけるメーカー想定売価は,GTX 750 Tiのメモリ2GB版が149ドル,同1GB版が139ドルで,GTX 750が119ドルとのことだ。
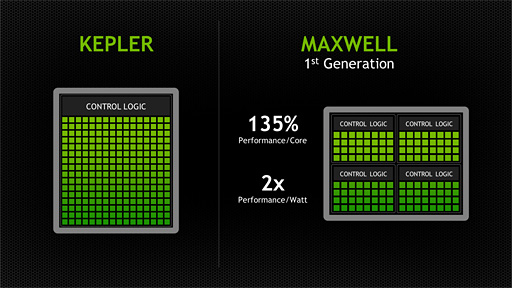
GM107は「第1世代」のMaxwellアーキテクチャを採用
演算ユニット構成の改良によって電力効率の向上を図る
GeForce GTX 750シリーズの2モデルでは,FermiやKepler世代のGPUにおけるローエンド製品向けGPUコアの型番「107」を採用しつつ,エントリーミドルクラス市場を狙ってきたのが大きなポイントとなる。より小さなGPUコアで,より低い消費電力と,より高い性能を実現してきたわけで,これこそがMaxwellアーキテクチャの賜物と言ってよさそうだが,では,Maxwellアーキテクチャとは,いったいどのようなものなのだろうか。
 |
「GPUのリソースを効率良く使うことを念頭に,コントロールロジックに注目してKeplerアーキテクチャに対して変更や改良を加え,大幅な電力効率の向上を計ったのが,第1世代Maxwellだ」。
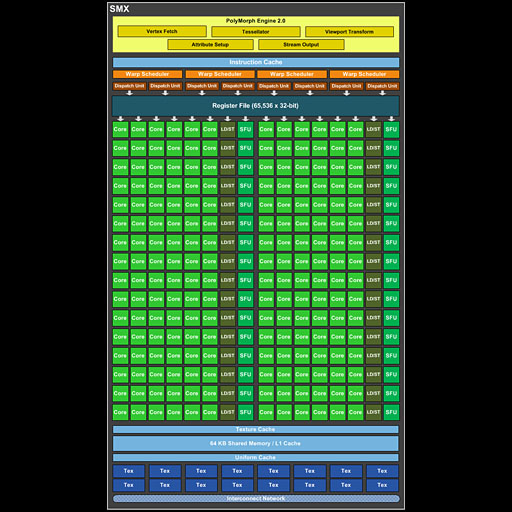
ここで,Keplerアーキテクチャを軽く振り返っておくと,Kepler世代では,「Streaming Multiprocessor eXtreme」(以下,SMX)と呼ばれる演算ユニットが基本単位となっていた。
SMXは,192基のCUDA Coreと32基のロード/ストアユニット,そして超越演算などをサポートする「Special Function Unit」(以下,SFU)32基による演算器クラスタを核として,ジオメトリエンジン「PolyMorph Engine 2.0」や16基のテクスチャユニット,L1キャッシュなどを組み合わせたものである。
 |
3Dグラフィックス処理は,たとえば「大量にある頂点座標を変換する」といったように,多数のデータに対して同じ演算を行う作業の繰り返しになる。そのため大多数のGPUでは,「データの数だけ同じスレッドを生成し,大量のデータに対して同じ処理を行う」手法がとられている。3Dグラフィックスなら,処理すべき頂点の数だけスレッドを作って,一気に処理してしまうといったやり方だ。
NVIDIAのGPUは伝統的に,32個のスレッドからなる「Warp」(ワープ)という単位でスレッドを実行する仕様となっている。そして,Warpの実行は「Warp Scheduler」(以下,Warpスケジューラ)によって制御されるが,Kepler世代においては,Warpスケジューラ1基あたり,最大で64 Warpを同時に管理できるようになった。スレッド数でいえば,Warpスケジューラ1基で最大2048スレッドの実行を司ることができたわけである。
Warpスケジューラは,命令発行を行うユニット「Dispatch Unit」(以下,ディスパッチユニット)を駆動することで,実行されようとしているWarpのうち,その場で実行可能なWarp命令を前出の演算器クラスタに実行させる。Keplerでは1基のWarpスケジューラあたり2基のディスパッチユニットを備えるため,最大で2命令を同時発行可能だ。
Warpスケジューラが実行させる命令のうち,たとえば加算や乗算といった簡単なものであれば,SMX内にあるCUDA Coreから32基を駆動して,32スレッド分あるデータの演算を行う格好となる。
「Warpスケジューラが,192基あるCUDA Coreのうち,どれをどのように選択して駆動させるか」といった詳細情報は公開されていない。ただ,先ほど示したSMXのブロック図からは,なんとなく「6基のCUDA Coreが,ロード/ストアユニットおよびSFU各1基とセットになっている」ようにも見えるので,ディスパッチユニットは,このセットを1基の“ミニプロセッサ”に見立てて,最大2命令を発行しているのではないか,という推測はできそうだ。“ミニプロセッサ”はSMXあたり32基となり,Warpとの兼ね合いからも,理にかなっているように思われる。
いずれにせよイメージとしては,SMXあたり4基用意されるWarpスケジューラが,空いているCUDA Coreやロード/ストアユニット,SFUを駆動して,“手持ち”の64 Warpをバリバリ実行している感じでいいだろう。
……と,以上がKeplerの復習だ。
それが第1世代Maxwellアーキテクチャではどうなったかというと,まず,演算ユニット単位でのアップデートが入っている。Maxwellにおいては,SMXあらため「Maxwell SM」,略して「SMM」――“MSM”にはならなかった――という演算ユニットが採用された。
 |
一見するとSMXによく似ているが,SMXとの間にある最大の違いは,SMMの内部で演算器クラスタを中心とする部分が4つの区画に分かれていることだ。NVIDIAはこの区画を「Partition」(以下,パーティション)と呼んでいる。
 |
1パーティションを構成するのは,命令バッファ(Instruction Buffer)とWarpスケジューラ各1基,ディスパッチユニット2基と,CUDA Core 32基,ロード/ストアユニット8基,SFU 8基。SMMは4パーティションからなるので,SMMあたりのCUDA Core数は128基,ロード/ストアユニットとSFUは各32基となる。つまり,SMXと比べるとCUDA Coreの規模は3分の2に小型化されたわけだ。
 |
負荷の低いときには必要のないパーティションへの電力供給を抑えられるわけで,1つの大きな演算器クラスタを扱っていたSMXと比べて,消費電力の削減を図りやすくなっているというのも,納得できる話といえる。
ただ,Warpスケジューラ1基で駆動できる演算器がCUDA Core 32基とロード/ストアユニット8基,SFU 8基となるので,SMXと比べてWarpの実行効率が低下するのではないかという懸念はある。たとえば,「2基のディスパッチユニットが同時に発行できる命令の組み合わせ制限」が厳しくなっているのではないか,といったものだ。
そういった懸念に対して直接の回答は行っていないNVIDIAだが,「SMMでは,ディスパッチユニットの『時間あたりの命令実行数』が向上した」とは述べている。前述のとおり,NVIDIAはCUDA Coreの駆動法に関する詳細情報を開示していないので,すべては推測するほかないものの,SMXでは演算器クラスタの利用効率が意外に低かったのかもしれない。
そのためSMMにおいてNVIDIAは,演算器クラスタを分割し,Warpスケジューラを簡素化すると同時にスケジューリングのアルゴリズムも見直すことで,CUDA Coreをはじめとする演算器の利用率を向上させてきたという可能性はある。実際NVIDIAも,「SMMのために新規に設計されたWarpスケジューラは,よりインテリジェントになり,ストールが減少した」という紹介を行っている。
ちなみに,レジスタファイル(Register File)は4パーティション分の合計で65536となり,総計はSMXと変わらない。スレッドあたりで利用できるレジスタ数で見たとき,SMMとSMXの間に大きな違いはないと思われ,「レジスタの制限でパフォーマンスが変わる」というようなことはなさそうだ。
2つのパーティションごとにL1を共有
クロスバー構造にも最適化が入る
SMMにはもう1つ,特徴的な部分がある。それは,2つのパーティションでL1キャッシュと4基のテクスチャユニットを共有する形になっているところだ。
L1キャッシュはテクスチャキャッシュも兼ねているとのこと。おそらく,L1キャッシュやテクスチャユニットを演算器により近いところへ置くことで,テクスチャや頂点データのロード/ストアで生じるペナルティを減らそうという意図だろう。
GPUは一般にメモリアクセスのペナルティが極めて大きく,メモリ上のデータへアクセスするには数十クロックから数百クロックといった大きなロスが生じる。そのためGPUではメモリアクセスのペナルティを抑えるため,多階層のキャッシュやメモリバッファを備えるが,第1世代Maxwellではパーティションという新たな階層にキャッシュを配置し直すことで,効率を上げようという意図が窺える。
なお,2つのパーティションごとにL1キャッシュを持つ格好となるため,L1キャッシュは2ブロックに分かれることになるが,L1キャッシュから分離された容量64KBの共有メモリ(Shared Memory)を介することで,2ブロックのL1キャッシュは,4つのパーティションから透過的に扱えるようになっている。
SMMでは以上のような改良により,SMXに対してサイズが90%に縮小されているという。CUDA Coreの数がSMXの192基からSMMで128基へと約33%減っているので,その分だけダイサイズ的には有利になるというのはよく分かるが,ダイサイズが10%減に留まっている以上,CUDA Core以外の部分が拡大しているのではなかろうか。
2ブロックに分かれたL1キャッシュや,さらにコントロールロジックなどの規模が少し大きくなっているのかもしれない。
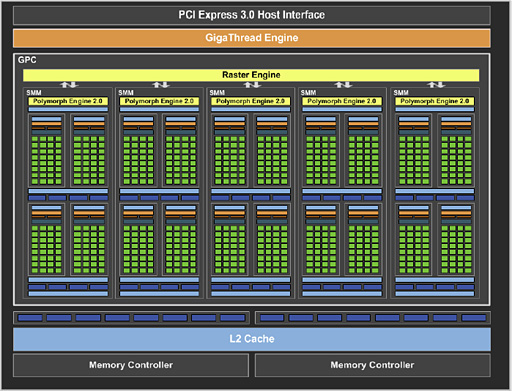 |
NVIDIAは第2世代TeslaアーキテクチャとなるFermiのタイミングで,GeForceにおいて,“ミニGPU”的な概念としての「Graphics Processing Clusters」(以下,GPC)を導入した。Kepler世代においては,1〜3基のSMXで1基のGPCを構成するような構造になっていたのを記憶している読者も多いだろうが,上のブロック図で示したように,GM107では最大5基のSMMをまとめて1基のGPCとしている。
そんなGM107の全体ブロック図で特徴的なのは,容量2048KB(=2MB)という巨大なL2キャッシュだ。Kepler世代だと,GK106で384KB,最上位の「GK110」でも1536KBだったので,GM107のL2キャッシュ容量はKepler世代と比して明らかに多いわけだが,NVIDIAによれば,この巨大なL2キャッシュも,消費電力低減のためだそうだ。
要は,グラフィックスメモリへのアクセスを減らすことで,カード全体での消費電力を下げているというわけである。
8基のROPユニットからなるROPパーティションを採用するというのはKepler世代と変わらず,その規模も16基と,Kepler世代のエントリーミドルクラスGPUから変わっていない。ただし,ROPユニットとメモリコントローラ,GPCに対してスレッド実行の割り振りを行う「GigaThread Engine」,ラスタライザ(Rasterizer,ワイヤーフレーム表示をビットマップ表示するためのプロセッサ)「Raster Engine)といった構成要素を結ぶクロスバー構造が第1世代Maxwellでは再設計されており,データフローの効率,そして電力効率が向上しているとのことだ。
 |
実のところ,この「CUDA Coreあたりの性能が35%向上」という数字はちょっとしたポイントとなっており,前述のとおり,SMMにおけるCUDA Coreの総数はSMX比で約33%少なくなっている。ただし,CUDA Coreあたりの性能が向上しているため,SMMの性能はSMXと比べてわずかながら向上していることになるのだ。
繰り返しになるが,GM107はSMMを5基集積するGPUコアだ。そして,5基という数はKepler世代におけるGK106のフルスペックと同じなので,NVIDIAの主張が正しいのであれば,GM107にはGK106より少し高い程度の性能を期待できる。GeForce GTX 750シリーズの型番が与えられたのも納得といったところか。
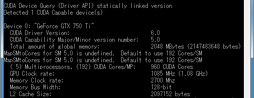
また,CUDA周りにも改善が入っているようだ。Walker氏が「Maxwell世代では,Keplerとは異なるCUDAの最適化が必要になる」と述べていたことを受けて,GTX 750 TiとGTX 750の「Compute Capability」をチェックしてみると,その値が5.0になっているのを確認できたからである。
 |
 |
Compute Capabilityは,CUDAの最適化方法の違いや機能の違いを示すバージョン番号のようなもので,Kepler世代で最も大きな数字は3.5だった(関連記事)。それがGM107で5.0へと大きく上がっているので,何らかの新機能が追加されていると考えるのが自然だ。
現時点でNVIDIAはMaxwell世代におけるCUDAの詳細を開示していないため,詳細は分からないが,新要素はあると期待しておいていいのではなかろうか。
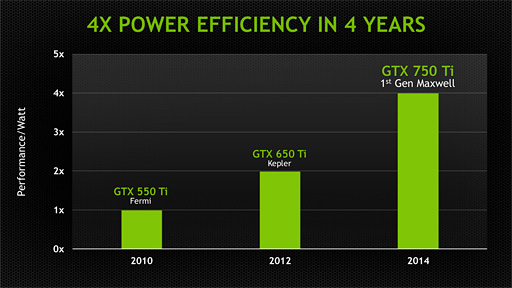
4年で4倍の電力効率を達成した第1世代Maxwell
NVIDIAは第2世代Maxwellも開発中
覚えている読者もいると思うが,NVIDIAはかねてより,Maxwell世代ではKepler世代に対して2倍の電力効率向上を実現すると予告してきた。Walker氏はその点について,「Maxwellアーキテクチャでは実際に,前世代のKeplerに対して2倍の電力効率を実現した。Fermi世代に対してKeplerは2倍の電力効率を実現していたので,4年で4倍の電力効率向上を達成したことになる」と胸を張る。
 |
Walker氏はまた,「一般的な(≒大手メーカー製の標準的な)デスクトップPCは,容量300Wの電源を備えていることが多い」とも語り,そのような,電源容量面の制限を抱え,補助電源も利用できないようなPCでも,GTX 750 TiやGTX 750があれば,十分にゲームPCとして利用できるようになると強調していた。
 |
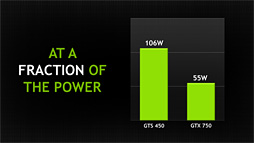
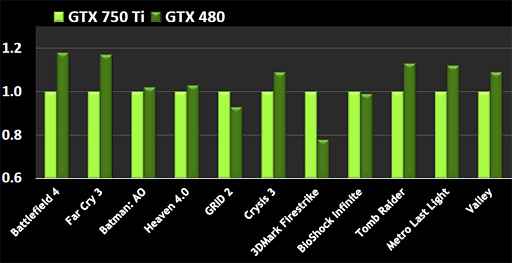
ちなみにWalker氏は,「GTX 750 Tiは,かつての『GeForce GTX 480』に匹敵する性能を持つ」と述べていた。GeForce GTX 480といえば,250Wという,歴代GPUのなかでも突出したTDPを誇る(?)GPUだったわけだが,それに迫る性能をわずか60WのTDPで得られるという話は,なかなかインパクトが大きい。
 |
 |
また,今回はあくまでも小型デスクトップPCの話がメインだったが,NVIDIAは,第1世代Maxwellの重要なターゲットとしてモバイルを挙げているため,ノートPC向けGPUの3D性能底上げにも期待が持てそうだ。
一方で,釈然としない読者もいるだろうと思う。これまで,NVIDIAが新世代のGPUアーキテクチャを導入するときは,必ずハイエンド市場向けグラフィックスカードが登場し,よくも悪くも大きな注目を集めてきた。それだけに,なぜエントリーミドルクラス市場向けGPUからなのかという疑問はどうしても残るところだ。
Walker氏はこの点について「エントリーミドルクラスこそが最も多くのユーザーに受け入れられているためだ」と述べていたりするが,実際のところは,TSMCの次世代プロセス技術である20nmでの量産がまだ始まっていないため,Maxwellアーキテクチャにおける経験値を溜めつつ,アーキテクチャの開発コストを回収すべく,まずは勝手知ったる28nmプロセスで導入した,という可能性のほうが高い。
もちろんNVIDIAはMaxwellアーキテクチャ世代でより高い性能のGPUを計画しており,「第2世代」Maxwellアーキテクチャも開発中であることを明言している。Kepler世代でも,まず3Dゲームアプリケーション向けの「GK104」を投入し,その後,数値演算プロセッサにも利用できるハイエンド市場向けコア「GK110」を投入してきたNVIDIAだけに,おそらく,第2世代Maxwellでは,今回発表された第1世代Maxwellとは多少異なる内部構造になるのだろう。そしてそれは,TSMCの20nmプロセス技術を利用して製造されることになるはずである。
なお,4Gamerでは,GTX 750 TiとGTX 750の発表に合わせて,さっそくレビュー記事を掲載している。3Dゲーム用GPUとしての性能を知りたい人は,ぜひそちらもチェックしてもらえればと思う。
「GeForce GTX 750 Ti」「GeForce GTX 750」をテスト。TDP 60W以下で登場した第1世代Maxwellは速いのか
- 関連タイトル:
 GeForce GTX 700
GeForce GTX 700 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー