













ニュース
NVIDIAの新機軸を理解する(2):DirectXの進化が止まったいま,ゲームグラフィックスはもうGPGPUに頼るしかない!?
Keplerアーキテクチャを採用するGPUの市場投入に合わせて,NVIDIAが打ち出した新基軸の内容を細かくチェックするシリーズ第2回。今回は,CUDA対応GPUの歴史を振り返りつつ,来たる「GK110」,そしてその先に控えるGPUの姿を占ってみたい。
当たり前の話だが,GPUという概念はもともと,3Dグラフィックスをレンダリングするためのものとして誕生した。
ここでいう「3D」は立体視という意味ではなく,x,y,z座標からなる三次元の仮想空間上で管理されるオブジェクトを描画することで作り上げられる映像のことを指す。
3Dグラフィックスの描画は,視線(=カメラ)の向き,描画対象の面(=ポリゴン)あるいはピクセルの向き,これを照らす光源の向きなどを基に計算される。向きはx,y,zの3要素からなる「単位ベクトル」で表すことができ,3Dグラフィックスを実現するための計算はベクトルの同士の内積と外積,あるいは加減算によって行われる。
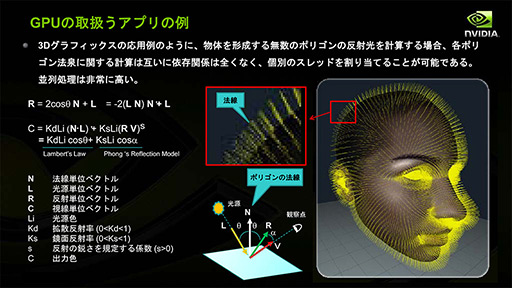 |
グラフィックス描画の最小単位はピクセルになるが,ピクセルごとのライティング計算には基本的に依存関係がないため,並列に実行できる。よって,グラフィックスレンダリングの性能を上げるためには,たくさんの演算器を搭載すればよいことになる。
GPUにおける演算器には,グラフィックス描画にある程度特化した機能が与えられたため,「陰影(shade)処理を行うユニット」という意味の「シェーダユニット」(Shader Unit)という呼び名が与えられた。NVIDIAに限らず,黎明期におけるGPUの進化史は,とにかく,このシェーダユニットの増設の歴史に等しかったのだ。
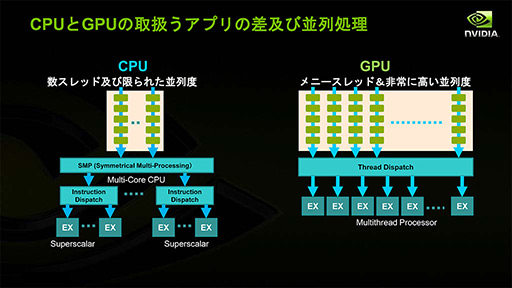
以降,CPUとGPUの対比はよく行われ,「スレッド」という言葉が登場した。「CPUは少ないスレッドを処理するのに適し,GPUは大量のスレッドを処理するのに適する」というのはよく用いられるフレーズである。ただ,これは少々誤解を生みやすい。
CPUで取り扱うスレッドとは,プログラムの流れ(=実行)そのもののことであり,プログラムそのものの並列実行には,物理コアか論理コアかはさておき,基本的にコアの増設で対応する。
一方,GPUで取り扱うスレッドとはデータ処理のことを指す。GPUでは,あるプログラムを複数のデータに適用していく考え方になるためだ。複数のプログラムを実行させるには,GPUでも,ひとかたまりのベクトル演算器を集めたプロセッサコアを増やすことで対応する。NVIDIAのGPUで言えば,「Streaming Multiprocessor」(以下,SM)が「ひとかたまりのベクトル演算器を集めたプロセッサコア」である。
 |
 |
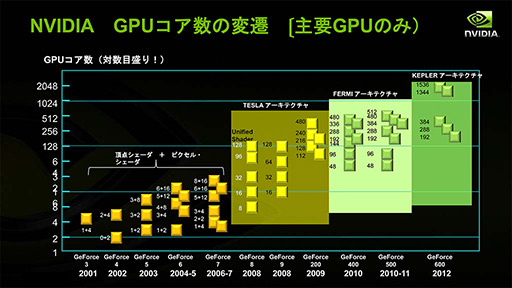
一見しただけだと,時間経過に合わせた線形な増加傾向にある雰囲気だが,縦軸が対数になっていることには注意が必要だ。つまり,GPUのシェーダユニット数は指数関数的に増加してきたのである。
 |
GPGPUプラットフォームとして誕生したCUDAとは何か
こうして指数関数的に増加するGPUのシェーダユニットを,グラフィックスレンダリング用途以外で活用しようとする動きが生まれる。これがGPGPU(General Purpose GPU)の概念だ。
前述したように,GPUの演算の最小単位はベクトル演算器である。これが大量にあるGPUは,いわばスーパーコンピュータと呼ぶに相応しいのではないか……。このように「実はすごいんじゃないか?」という期待のまなざしを向けられて,GPGPUは誕生した次第である。
ただ,最初期のGPGPUは,汎用演算のプログラムを,グラフィックスレンダリングに見立ててGPUに実行させるアプローチを取っていた。
GPUとしては普段通りグラフィックスをレンダリングしているだけのつもりだが,フレームバッファには映像ではなく,「欲しい演算結果」が書き込まれるように仕向けたレンダリングプログラムを動かすという手法だ。GPUをある意味,無理矢理にGPGPUとして使おうとしたわけである。
 |
NVIDIAは,そうした声に応える形で,新しいGPUアーキテクチャ「Tesla」(テスラ)を開発した。4Gamer読者になじみ深いGPU名でいえばGeForce 8000シリーズである。そして,Teslaアーキテクチャとほぼ同じタイミングでリリースされたGPGPUプラットフォームが,「CUDA」(Compute Unified Device Architecture,クーダ)となる。
CUDAの根幹となるプログラミング言語は,一般的なC言語をベースに,ベクトル拡張してC++のエッセンスを導入した「CUDA C」である。下のスライドは,CとCUDA Cの間にある言語体系の違いを示したものだ。
 |
計算対象のデータを参照するためのインデックス変数を増加させつつ,プログラムをループで回すことによって処理するC言語に対し,CUDA Cでは,「計算対象のデータに対してどんな計算をするのか」を「カーネル」として定義するような概念になっている。上のスライドでいえば,修飾子「__global__」がGPUで実行するためのカーネルの宣言に相当する。
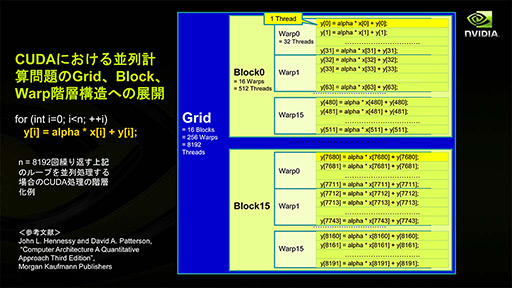
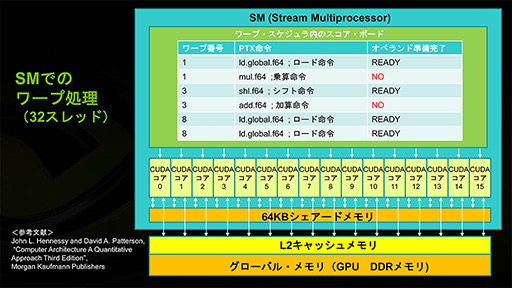
CUDAでは,「データ処理を行う流れ」である「スレッド」を32個まとめて「Warp」と呼ぶ。CUDAの概念だと,Warpは,定義したカーネルが一度に並列実行されるときの最小単位となっている。
またCUDAでは,この32スレッド=1 Warpを複数集めた単位を「Block」として定義している。Compute Capability(※) 1.x(以下,CC1.x)では1 Blockあたり16 Warp(=512スレッド)まで,Compute Capability 2.x(以下,CC2.x)以上では32 Warp(=1024スレッド)をひとまとまりのBlockとすることができる。
なお,Blockサイズ以上のスレッドを並列処理させたい場合には,複数のBlockをひとまとまりにした「Grid」という概念を用いることになる。
CC1.xだとGridに与えられる最大次元数は2(=x,y),CC2.x以上では3(x,y,z)。各Gridに与えられる次元長は,CC1.xだとx,yに対して65535(216-1)のところが,CC2.x以上ではx,y,zに対して2147483647(231-1)へと拡張されている。
 |
GPUに対する「実際の計算」の発注はGrid単位で行われ,GPU内では,この中に含まれる複数BlockのそれぞれをGPU内のSMに割り当てて実行していく。
Blockの数がSMの数を大きく超える場合,各SMは,複数Blockの実行も担当する。要するに,メモリアクセス時などといった大きなストール時における実行対象の切り替えは,Warp単位だけでなく,Block単位でも起こりうるということである。
なので,実行順序はWarp単位だけでなく,Block単位においても順不同の並列処理となる。一方,異なるBlock間の同期処理はサポート対象外だ。これは最新のKepler世代のCompute Capability(以下,CC3.x)になっても変わらない。
※Compute Capabilityとは何か
CUDAは定期的にバージョンアップされている。2012年9月時点における最新版はCUDA 5.0(※βリリース)だ。
ただこれとは別にNVIDIAは,新しいアーキテクチャのGPUを発表するごとに,そのGPUが対応できるGPGPUポテンシャルのバージョン番号をCompute Capability(計算能力)バージョンとして提示している。
ここがややこしいのだが,CUDAとCompute Capabilityのバージョン番号は同期していない。本文でも触れたとおり,Kepler世代のGPUにおけるCompute Capabilityバージョンは3.0だ。
DirectX(=Direct3D)にたとえると,CUDAバージョンがDirectXバージョン,Compute Capabilityバージョンがプログラマブルシェーダ仕様(=Shader Model)バージョンのようなイメージといったところか。
並列処理に条件分岐を持ち込んだ「SIMT」
CUDAに限らず,GPGPUでは,CPUのように「1つ1つの処理を正確に進めていく」というよりむしろ,「大量の計算を一度にやって,不要な計算結果は後で捨てる」という思想がベースにある。
そうはいっても,各計算処理(=カーネル)において,最低限の論理処理は行っておきたいが,同一カーネルを複数スレッドで動かして,異なるデータに処理を適用していくGPGPUの概念において,論理処理の導入は難しいテーマでもある。
「論理処理」というのは何か。グラフィックスレンダリングで喩えて簡単に説明すると,「異なる座標のピクセルごとに,1つのピクセルシェーダプログラムが陰影処理のやり方を微妙に変えていく」ような処理に相当する。
この実現には条件分岐の処理系が欠かせないのだが,ここで,「条件分岐なら,Shader Model 2.0でも頂点シェーダに対して限定的に,3.0なら頂点シェーダででもピクセルシェーダででも処理できたはずでは?」と疑問を持った読者もいるのではないだろうか。
実はそのとおりだ。だがCUDA対応のGPU(=Shader Model 4.0以降に対応したGPU)からは,こうした条件分岐実行の仕組みを一般拡張化してきたという違いがある。
それが「Predication」(プレディケーション,断定・賓述)という概念だ。
Predicationでは命令実行にあたって「実行するか否か」の判断が常になされる。
一般に条件分岐(=ジャンプ)では,条件成立時,あるいは不成立時にプログラムの実行アドレスを変更する。それに対してPredicationでは,条件分岐が起きてもプログラムの実行アドレスは変更されない。条件判断だけを行って,その結果を基に,それ以降の命令実行時に逐一「実行するか否か」の判断を行っていくのだ。
Predicationの利点は並列処理の流れ(=パイプライン)を乱さずに条件分岐が実現できること。一方で,たとえ条件分岐による分岐が成立しても,全スレッドで条件分岐成立時/不成立時,両方の命令を実行する(というか「なぞる」)ことになるため,処理時間が長くなってしまう弱点がある。
プログラムの実行アドレスを変更する条件分岐の実行形態では,分岐成立時に処理を早く終えることができるが,Predicationではこれができない。今日(こんにち)のGPUが,グラフィックスレンダリングにおけるプログラマブルシェーダで「条件分岐を使うと遅くなる」というのはこの理由からだ。
もっとも,大規模な並列処理を行うことが目的となるGPGPUの世界においては,デメリットを補って余りあるほど,CPUで行うよりも圧倒的に高速な処理が行えるので,この仕様は歓迎されている。
そしてNVIDIAは,こうした「条件分岐に対応した並列命令実行形態」を「SIMT」(Single Instruction Multiple Threads) 処理と位置づけている。
 |
CUDAは中間言語「PTX」への変換後に実行される
CUDAの実行は,実は二段階のプロセスを経ている。実際にCUDAプログラミングを行っている人にとっては当たり前の話だが,一般ユーザーにはあまり知られていないかもしれないので,お伝えしておこう。
CUDAプログラムは,コンパイルによって「PTX」(Parallel Thread eXecution)と呼ばれる中間言語へと変換される。実際のGPUが実行するときは,ドライバでPTXをさらにネイティブなGPUコードへ変換するという流れだ。
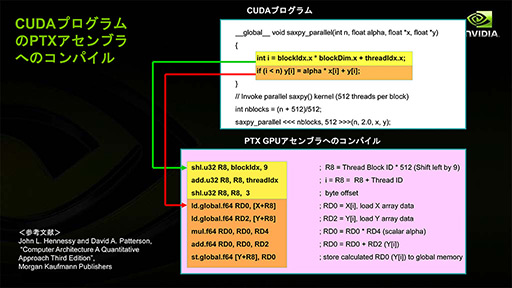 |
CUDAの互換性はPTX上で取られており,GPUネイティブコードはGPU製品ごとに異なっているため,互換性がない。こうした手法は珍しくなく,身近なところではJavaがそうだし,Intelのx86系CPUもいまや実行ファイルに含まれているx86コードを直接実行しているのではなく,x86系CPU世代ごとに異なるRISC風のマイクロコード(μOp)へとCPU内部で変換してから実行している。CUDAだけが特殊というわけではないのである
 |
CUDA対応GPUの進化
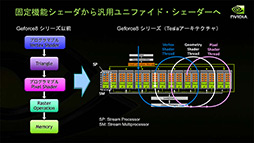 |
このタイミングでDirectXはDirectX 10となり,GPUは統合型シェーダ(Unified Shader)アーキテクチャへと変革のときを迎えた。それまでのGPUは,頂点処理用の頂点シェーダとピクセル処理用のピクセルシェーダという,「用途限定のシェーダユニット」で構成されていたが,統合型シェーダアーキテクチャでは,汎用シェーダユニットを多数揃え,適宜それらを頂点シェーダやピクセルシェーダなどとして起用するようになったのだ。
もちろん,用途を限定しない「汎用シェーダユニット」の形態にしたことと,GPGPUへの対応化は無関係ではない。なお,Tesla世代のCompute CapabilityバージョンはCC1.xとなる。
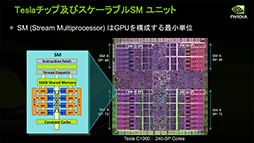 汎用シェーダユニットを複数ひとまとまりとしたSMという概念が確立したのもこのタイミングだ |
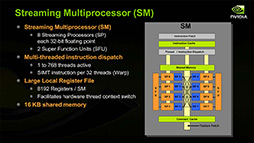 SMが単位時間あたりに処理できるのは1 Warpだが,複数のBlockを処理していく能力がある |
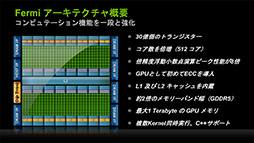 |
なにしろ,リアルタイムグラフィックスレンダリング用途ではもてあまし気味な倍精度浮動小数点演算性能がTeslaコア比で8倍に高められており,メモリシステムはECC(Error Check and Correction,誤り検出訂正)に対応(※GeForceでは利用不可)。アドレス空間は1TBにまで広げられたのである。結果的に,このアーキテクチャ方針が,NVIDIAにスパコン分野での成功をもたらすと同時に,GeForceでは「DirectX 9アプリケーションを前にすると,競合製品より性能面で不利」という結果を生んだので,確かにFermiはGPGPU寄りのGPUコアだったといえるだろう。
 |
なお,Fermiコアは主にGeForce 400〜500で採用されたものだ。GeForce 400の時点でDirectX 11対応を果たし,Compute CapabilityもCC2.xへとバージョンアップしている。
 |
Teslaコアにおいて,各SMは1つのカーネルに対して複数スレッドを処理できたが,FermiコアではSMごとに異なるカーネルを実行しつつの複数スレッド処理ができるようになったのだ。これはCC2.xからの機能であり,同時実行カーネル数は最大16となっている(※もちろん実際には,GPUの搭載するSM数によって上限は異なる)。
 |
しかし,グラフィックスレンダリングとCUDA実行は同時処理できない。動作モードを切り替えねばならないからだ。
モード切り替えを行うコンテキストスイッチの性能はFermiでTesla比約10倍高速化されて,その所要時間は25ms以下となっているが,この値は依然として,リアルタイムアプリケーションにとっては相応に長い時間である。
Kepler「GK110」はさらにGPGPU方向へ進む
そして現行世代,Keplerコア世代では,DirectX 11.1に対応し,Compute CapabilityバージョンもCC3.xとなった。
SMのデザインはさらに拡張され,SMあたりのCUDA Core数はFermi世代比で4〜6倍の192基となった。Fermi世代の複数SMを統合して1基の大きなSMにしたようなものになったことから,NVIDIAはKeplerから,SMを「Streaming Multiprocessor eXtreme」(以下,SMX)と改称している。
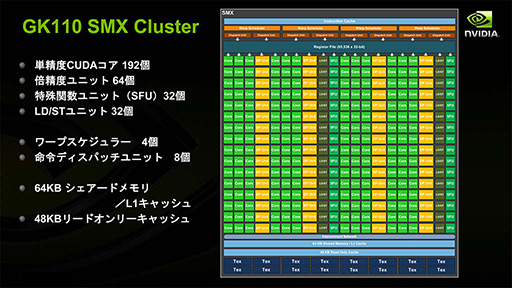 |
 |
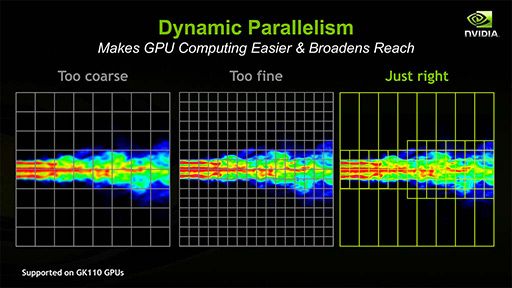
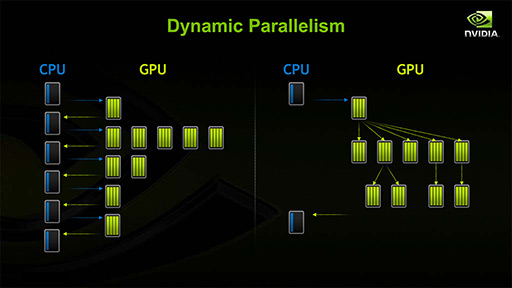
最大で15基のSMX,CUDA Coreにして2880基を統合するため,かなりのビッグチップになると予測されるGK110。NVIDIAはそんなGK110において,GPGPU用途向けの二大機能,「Dynamic Parallelism」「Hyper-Q」を導入する計画になっている。
まずDynamic Parallelism(ダイナミックパラレリズム)は,実行中のスレッドが,子Grid・Block・Warpを再構成して実行できる仕組みのことである。
Dynamic Parallelismを利用すると,現在処理中のスレッドが,処理対象データに適した別の演算粒度の子スレッドを立ち上げて精度の高い処理結果を得たり,再帰的な解析処理などを実現できたりするようになる。ちょっと強引な喩えかもしれないが,GPU内で自在にジオメトリを消滅・生成することが可能なジオメトリシェーダのようなイメージかもしれない。
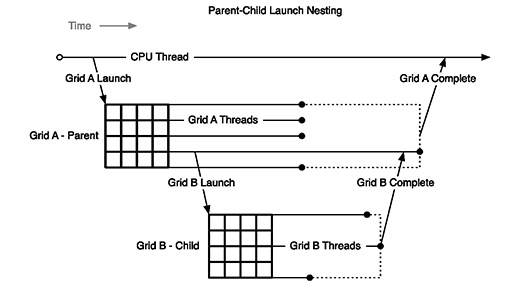 |
Dynamic Parallelismでは,CPU側のプログラムに判断を仰ぐために処理系を戻したり,データのコピーをしたりする必要がなくなることから,従来比で性能向上をもたらす効果も期待できる。
 |
 |
 |
 |
 |
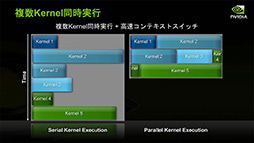
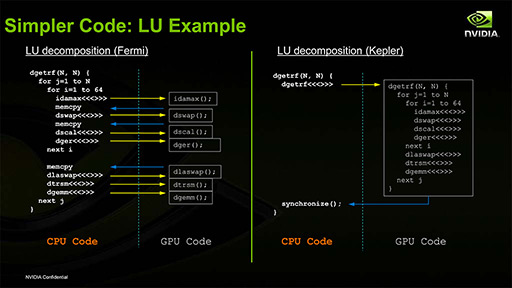
「異なるカーネルをSMごとに実行できる」という基本機能はFermi世代のCKEと同じだが,Fermi世代のCKEだと,CPU側からGPUにたくさんの処理を発注した場合,GPUは発行順に処理するので,その処理の群れに依存関係があったりすると,後ろに控えている別カーネル用の処理がいつになっても始まってくれなかった。
異なるカーネルを同時に動かせるのは,発注された処理系のうち,依存関係が途切れるときに限定されたのだ。
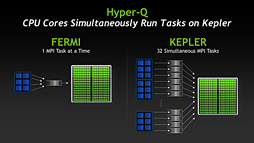
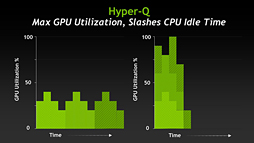
その点,Hyper-Qを搭載するGK110では,CPUから処理が発注されたときに,依存関係がないことを明確にできるようになった。これにより,CKE動作がさらに効率よくなるというわけなのである。
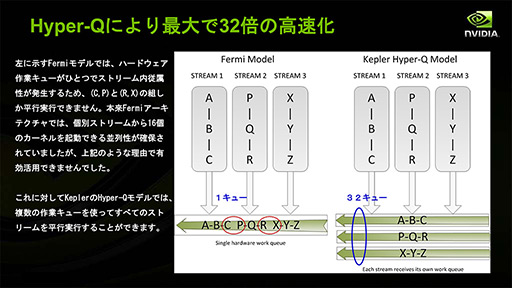 |
この「複数の同時発注された処理系を溜め込んでおくところ」を「キュー」(queue)と呼ぶが,これがGK110では32ある。つまり,ベストケースでは32ストリームを同時に動かせるということになる。
 |
ゲームグラフィックスはGPGPUを前提とした進化の道へ?
 |
スーパーコンピュータの最大性能ランキングである「TOP500や,1WあたりのFLOPS値をランキングした「Green500」などを見ても,上位にNVIDIAのGPUを搭載したスーパーコンピュータが登場し始めており,NVIDIAのGPGPU重視戦略は徐々に結果を出しつつある印象である。
さらに,先の記事でお伝えした,GPUの仮想化技術を応用する「GeForce GRID」などのようなクラウドシステム向けGPUソリューションなどが台頭してきていることも考えると,GPUの「グラフィックス以外の機能の拡張」はさらに広がっていきそうだ。
 |
一方のNVIDIAは,GPUの進化をやめるどころか,増えつつあるGPGPUユーザーのため,近未来に登場するGPUの性能指標を盛り込んだロードマップまで公開している。GPUの進化をさらに推し進めていく姿勢を明確に打ち出しているのである。
となると,グラフィックスは進化せず,GPUはだんだんとGPGPU的な,言うなればCPU的なものになっていくのだろうか。
実は,それがそうでもない。むしろグラフィックスは,GPGPU的な機能を利用し,取り込みつつ,進化していこうという流れが出てきているのだ。
2011年に売されたElectronic Artsの「Battlefield 3」PC版では,GPGPUを活用したディファードシェーディング(Deferred Shading)レンダラーや,GPGPUベースのカリングシステムを実装して注目を集めた。また,E3 2012で公開されたEpic Gamesの「Unreal Engine 4」におけるリアルタイムのグローバルイルミネーション(Global Illumination,大局照明)を実現するために採用されたスパースボクセルオクツリー(Sparse Voxel Octree,関連記事)は,シーンのジオメトリ構造を解析して八分木(octree)化する処理をGPGPU的に行っている。
今後は,GPGPUの機能進化が,新しいゲームグラフィックスの表現までをもたらしてくれるようになるかもしれないのだ。

Unreal Engine 4におけるリアルタイムグローバルイルミネーションエンジンのベースとなった論文「Interactive Indirect Illumination Using Voxel Cone Tracing: An Insight」より。ムービー後半に出てくる空間を,異なる大きさの箱で分割する処理系をGPGPU的に実装。ちなみにムービーでは,この箱単位で各方向からの光の情報を管理し,ライティングに応用している
NVIDIAの新機軸を理解する(1):GeForce GRIDが描く「ゲームスタジオが独自のゲームプラットフォームを描く時代」
- 関連タイトル:
 CUDA
CUDA
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー