













ニュース
David Kirk氏,「3ステップで取り組むGPGPU」を提唱
 |
GPGPUとはGeneral Purpose GPUの略で,簡単にいえば,「GPUの演算性能を3Dグラフィックスだけではなく汎用目的に流用する技術」のこと。そしてGPUコンピューティングは,最近のNVIDIAが好んで使うキーワードで,実質的には「GPUコンピューティング=GPGPU」という理解でOKだ。本稿ではとくに意識せず,同義的に両キーワードを用いる。
――余談ながらに続けると,NVIDIAはかつて,ワークステーション用GPUであるQuadroシリーズにフォーカスした“グラフィックス寄り”のGPGPUソリューションを「ビジュアル・コンピューティング」と呼んでいたが,最近ではあまり用いなくなった。
NVIDIAは,2006年にG80コアの「GeForce 8800 GTX」を発表したとき,それとほぼ同時に,独自のGPGPUプラットフォーム「CUDA」(Compute Unified Device Architecture)を発表しており,以降,このCUDAは,同社が手がけるGPU関連マーケティングにおいて,非常に大きな存在へと昇格した。
NVIDIAは,G80以降,ほぼすべてのGPUにおいてCUDAをサポートし,GPUの世代を新しくするごとに,後方互換性を維持しながらCUDAのユーザビリティや機能も改善させてきた。その努力が報われた形で,今日(こんにち)では,GPGPUプラットフォームの業界でのデファクトスタンダード的な位置を得るまで漕ぎ着けている。
 |
さて,今回のGPUC2010は“日本版GTC”ともいうべきカンファレンスで,その基調講演には「GeForceの父」とも呼ばれるDavid B.Kirk(デビッド・カーク)氏が登壇した。
進むスパコンのGPGPU化〜GPGPUベースのスパコンが
世界第2位の高性能スパコンに認定
 |
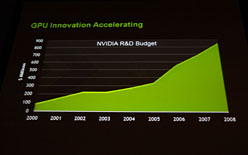
NVIDIAは,GPGPU専用用途のGPUハードウェアとしてTeslaブランドを展開し,2007年より製品をリリースしている。大局的かつ大規模な演算を行うHPC(High Performance Computing)分野において,CPUベースのHPCハードウェアに対し,GPUベースのTeslaは破格に安価だったこともあり,「スーパーコンピュータの価格破壊」「デスクトップ・スーパーコンピュータ」などともてはやされ,とくに,あまり予算を大きく取れない大学の研究室が積極的に導入を行ってきた経緯がある。
以降,大学など研究機関での高い評価に後押しされる格好で企業への導入も進み,現在はさまざまな業務用アプリケーションが開発/提供されるようになった。Furney-Howe氏も,このわずか4年間でのNVIDIAのGPGPU技術の浸透には確かな手応えを感じているのだろう。
 |
リアルタイム3Dグラフィックスの黎明期は,そのレンダリングを本物っぽく見せるため,「自然現象を演算負荷の低い疑似モデルに置き換えること」に明け暮れていた。しかしリアルタイム3Dグラフィックスは,そうした“いんちき”ではななく,まともなシミュレーションベースの,“リアルな”メソッドを実装していくために,その演算パワーを増大していく。
その進化の過程で,その超並列演算パワーをHPC用途にも応用していこうという,前述のようなムーブメントが起こったわけだ。
 |
| 世界第2位の性能を叩き出す中国のスーパーコンピュータ「星雲」はGPGPUベース |
 |
| 世界各国各地でGPGPUベースのスーパーコンピュータが誕生しつつあるとKirk氏 |
かくしてGPGPUはその価値が世界で認められるに至り,HPCハードウェアの革命児的な位置づけとなった。結果,世界の名だたる研究機関に新規導入されるスーパーコンピュータのうちいくつかは,GPGPUベースのものになっているとKirk氏は説明する。
その直近の事例として挙げられたのは,中国の国立スーパーコンピュータセンターに構築された「星雲」(Nebulae,ネビュラ)だ。星雲は,世界で2番目に高性能と認定されたスーパーコンピュータであり,その内部は4640基のTeslaで構成されている。実効性能では世界第2位となっているものの,2.98PFLOPS(ペタフロップス)をマークした理論スペックは世界最高値というのがウリだ。
Kirk氏は「今やCUDAは,300を超える大学において,並列プログラミングの授業で採用されています」と述べ,
というプラスのスパイラルに入っているという見通しを示した。PCゲーム市場は決してなくなっていないが,市場の成長度合いで見れば,今やHPC市場のほうが大きい。直近の2世代で,NVIDIAのGPUコアがGPGPUソリューション向けに傾倒したことも納得のいくところではある。
 |
「NVIDIAが明日この世からなくなったとしても,CUDAがこの世からなくなることはもうないでしょうね(笑)」(Kirk氏)。
CPUとGPUの適材適所を訴えるKirk氏
 |
また,スーパーコンピュータは,それ自体を冷却するための冷房費なども高く付くが,GPGPUベースだと全体の体積が小さいため,37TFLOPSのシステム同士での冷却費用は,GPGPUベースのほうが4.5倍も安く上がるとKirk氏は指摘する。
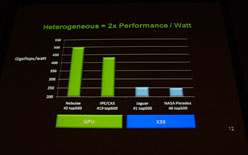 1WあたりのGFLOPS値をGPUベースとCPUベースとで比較 |
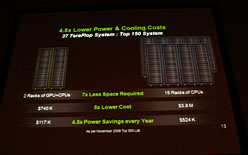 同一性能でCPUベースのスーパーコンピュータと冷却費用を比較 |
 |
Kirk氏も,基調講演のなかで,「CPUはシリアルタスクの実行を得意としているため,複雑な制御系処理を任せる。これに対してGPUはパラレルタスクを得意としていますから,ある処理系を同時多発的に行うことを任せます。CPUとGPUは互いを補い合う関係にあります」という表現を使っていた。
これはCPUとGPUの「適材適所」をアピールしているわけだが,ただ一方で,NVIDIAはCPUを擁護していたり,CPUに気を遣っていたりするわけでもない。むしろNVIDIAの言い分は攻撃的であり,語弊を覚悟で言えば,Kirk氏,そしてNVIDIAは「GPUが得意とするべき分野から,CPUには早く出ていってもらいたい」というメッセージを込めているのである。
 |
 |
 |
GPGPUが命を救う?
「計算の高速化は,結果が早く得られるという直接的な恩恵だけでなく,しばしば,科学技術の在り方を根本的に変えてしまう可能性もあるのです」(Kirk氏)。
GPGPUソリューションは「CPUのX倍処理が速くなる」というのが,直接的かつ短期的に得られる恩恵だが,それ以外にも,「できることは分かっているのに,現実的ではない」とされてきたソリューションが,演算能力の向上で実用化に踏み切れるようになったという事例が,最先端の科学の現場,とくに医学と薬学の現場で生じているという。
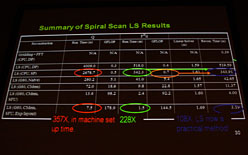 |
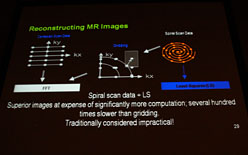
これまで,MRIスキャンで得られた生データは,高速フーリエ変換(FFT)で処理しやすいように,グリッドデータに前処理として近似する手法(※格子状に揃える,一種の量子化に相当する処理)が採用されていた。これは確かに高速にはなるのだが,精度とのトレードオフがある手段だった。
ただ,GPGPUによる超並列計算が高速かつ安価に行える見通しが立つようになってからは,MRIスキャンを行った生データのすべてに対し,FFTを用いず,最小二乗法を直接適用して高精度な結果を得る手法の実用化が可能になったという。これはある意味,GPGPUがもたらした超並列演算の高速化が医学に貢献した好例だといえよう。
 |
 |
 |
 |
薬学シミュレーションの世界でも同じようなことが起きていると,Kirk氏は説明する。
高分子規模の分子シミュレーションをインタラクティブに行うという,これまで困難だったことが現実味を帯びてきたため,新薬の開発速度や,その副作用の予測スピードなどを加速させることができるようになっているという。
極めて近い将来,我々の命が,GPUによって救われている瞬間があるかもしれない。
 |
 |
 |
 |
GPGPUへの取り組み方,3ステップ
講演の最後にKirk氏は,GPGPUソリューションへの取り組み方を3ステップにまとめてみせた。
 |
「第一段階では,既存のソフトウェアをアクセラレーションすることを考えてみてください」。
既存のプログラムを大幅に変えずとも,例えば一部の関数の並列化に取り組んでみたり,あるいは普段何気なく使用しているFFTを,CUDAライブラリ版に変更してみたりするだけでもいい,とKirk氏。まずはここから始まるというわけだ。
「第二段階では,GPGPUに配慮して既存のソフトウェアを再開発したり,新規ソフトウェアを開発したりしてください」。
既存のソフトウェアを並列化したり,あるいはこれからソフトウェアを新規に開発したりするときは,実装段階から並列化を念頭において設計していくイメージだ。ゲーム開発シーンも含めて,現在,多くの開発者がこのフェーズにいると思われる。
「第三段階では,既存の概念にとらわれない,超高速な並列計算だからこそできる新しいアルゴリズムの開拓に挑戦してみてください」。
これが最も難しいが,逆に最も革新的なテーマであり,GPGPU技術を盛り上げることにも貢献することになる。
Kirk氏はこの第三段階こそが,GPUC2010の参加者達が挑戦すべきテーマであると結び,講演を終えた。
会場で見かけたブース展示
なお,会場にはいくつか気になる展示があったので,写真を中心に紹介してみたい。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
- 関連タイトル:
 CUDA
CUDA
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー