













連載
西川善司の3DGE:AMDの超解像技術「FidelityFX Super Resolution」は,DLSSのライバルとなり得るのか
 |
その当日に合わせてAMDは,FSRについての情報を公開している。本稿では,その内容をもとに,FSRの紹介と技術的背景などをレポートしたい。

超解像技術とは何か
解像度変換ではなく解像度を復元する技術
まずは大前提として,超解像技術とは何かを解説しておこう。頭に「超」が付くことで,なんとなくうさんくさいイメージがあるかもしれない,これは立派な学術用語である。
超解像とは,学術的には「画像に含まれる情報のうち,入力画像の標本化周波数で決定されるナイキスト周波数よりも高い周波数成分を復元する技術」と定義されている。ここでいう周波数とは,画像に含まれる模様の細かさと思えばいい。
たとえば,テーブルに置いてある白黒市松模様のチェス盤をカメラで撮影するとしよう。白と黒の市松模様を正確に記録するには1920×1080ピクセルの解像度が必要だった場合,撮像素子の解像度が720×480ドットしかないカメラでこれを撮影すると,白と黒のマス目を正確に記録できずに,灰色となったり白黒の割合が不正確になってしまうだろう。
そこで,白,黒,灰色の大ざっぱな情報になってしまった720×480ピクセルの画像を,1920×1080ピクセルに復元して正しい白黒市松模様で描こうとするのが超解像技術だ。
超解像に似た技術として,高解像度への解像度変換であるアップスケーリング技術がある。写真編集ソフトでもよく用いられるアップスケーリングの手法といえば,バイキュービック法(bicubic interpolation)だろう。
これは,変換後の座標系を基準として4×4の16地点のピクセル値を元画像から取り出して,これら16点のピクセル値に重み付けをして加重平均的な計算を行い,変換後のピクセル値を決定する手法だ。ピクセル値の計算式には,
- f(t)=sin(π・t)÷π・t
を用いるのが一般的だが,映像プロセッサなどではこれを三次多項式で近似した近似式を用いることもある。バイリニア法ではぼけてしまうような輪郭表現でも,バイキュービック法では比較的クリアな輪郭を維持できるのが特徴と言えよう。
 |
 |
こうした解像度変換技術は,主に「解像度を上げても,いかにぼやけさせないで低解像度の画像や映像を表示できるか」という目的で利用するものだ。ただ,アップスケール技術だけでは,変換後の画像や映像の情報量は入力元である画像や映像の原信号から変化しない。
解像度変換技術を発展させて,表示映像の情報量を画像や映像の原信号から増加させつつ,解像度変換を行うのが超解像技術ということになる。
FidelityFXとは,AMDが提供するポストエフェクト処理のシェーダライブラリ
もうひとつ,FidelityFXとは何かも説明しておこう。
FidelityFXは,2019年にAMDが,初代「Navi」世代のRadeon RX 5000シリーズ発表時にアナウンスした技術で,一言で言えば,「ポストエフェクト処理が中心のオープンソースのプログラマブルシェーダのライブラリ」である。
ゲームグラフィックスにおけるポストエフェクト(後処理)でありふれたものといえば,焦点からずれた情景をボカすピンボケ(デフォーカス)効果だろうか。高輝度な反射表現に対して光が溢れ出て見えるようなグレア(Glare)効果やブルーム(Bloom)効果,ディフュージョン(Diffusion)効果もポストエフェクトであるし,PCゲームのグラフィックス設定では「SSAO」の略表記でよく見かけるキーワード「スクリーンスペース・アンビエントオクルージョン」(Screen Space Ambient Occlusion)などもそうだ。
つまり,一度描画した映像に対してお化粧を施すのがポストエフェクトである。
これまでにAMDは,FidelityFXでさまざまな機能を提供している。
数ある中でも採用事例が多いのものには「Contrast Adaptive Sharpening」(CAS)が挙げられよう。カプコンの「バイオハザード・ヴィレッジ」PC版にもこのオプションがあったので,「あれもそうなのか」と思った人も多いのではないだろうか。
 |
FidelityFXで提供しているポストエフェクトは,AMDが運営する開発者向けサイトである「GPUOpen」にて公開中(関連リンク)で,ゲーム開発者はライセンスフリーで自分のゲームに活用できる。
基本的にプログラマブルシェーダで構築されたシェーダプログラムであるため互換性が高く,旧世代のGPUはもちろんのこと,競合であるNVIDIAのGeForce系でも動作する点も特徴である。
 |
ポストエフェクトという仕組みなので,既存のゲームに対して強制的に効かせるようなことは,基本的にはできない。ゲームプログラム(やゲームエンジン)などが実際に組み込まなければその恩恵にはあずかれないと思っていい。
ただ例外もあり,CASは,ドライバソフトである「Radeon Software」の機能として,「Radeon Image Sharpening」という名前で提供されている。
FidelityFX Super Resolutionとは?
前置きが長くなったが,本題のFSRについて説明していこう。
FSRは,FidelityFXのラインナップに加わった超解像ポストエフェクトである。
 |
AMDは,FSRの特徴として以下の3つを上げている。
- クロスプラットフォームである
- ゲームへの統合がしやすい
- 業界標準API(DirectX 11/12,Vulkan)への対応
 |
1つめの特徴であるクロスプラットフォームは,FidelityFXでも触れたように,GPUOpenでソースコードを公開していることと,NVIDIAのGeForceでも動作することをアピールしている。FSRは,GPUで動作する汎用シェーダプログラムであるうえ,GPUドライバソフトが業界標準APIに対応していれば,OSはWindowsでもLinuxでも動作ができる。
2つめの特徴は,プログラマブルシェーダ中のCompute Shaderを活用した独立した単体のポストエフェクトシェーダであり,ゲームグラフィックス側の内部パラメータを参照する必要性がないとAMDはアピールしていた。
3つめは,対応APIがDirectX 11/12とVulkanであり,特別なアドオンソフトウェアやドライバソフトウェアは不要であることをアピールしている。
さてAMDは,FSRを組み込んだグラフィックスパイプラインとして,以下に示すパイプラインを公開しているのだが,FSR自体のアルゴリズムは公開していない。
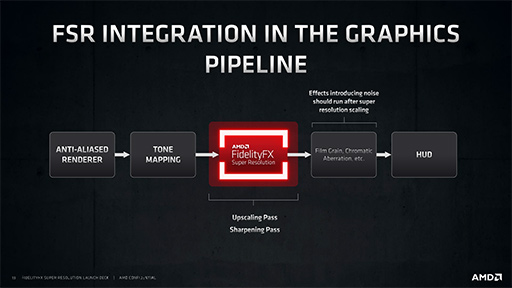 |
筆者は,AMDに「具体的にどのような論文を参照して実装したのか」と質問したものの,公開しないということだった。NVIDIAは,さまざまなフィルターに関してアルゴリズムを明らかにしているだけに残念だ(たとえば,DLSS 2.0のアルゴリズム解説はPDFで公開中)。FSRはソースコードが開示される予定なので,具体的な情報は,そこからアルゴリズムを読み解く必要がありそうである。
それでも,上の簡易パイプラインからいくつかの情報が読み取れる。
まず,FSRに入力すべき画像は,条件として「アンチエイリアス処理が済んでいる」ことと,「トーンマッピング処理が済んでいる」必要があるという。要は,ジャギーの低減とハイダイナミックレンジ(HDR)表現のコントラスト調整は終えていなければならない,ということだ。
もちろん,FSRが処理を終えて出力した画像に対して,さらなるポストエフェクトを与えることは可能だ。その例としてAMDは,「意図的なノイズ付加」や「意図的な色ズレ(色収差)付与」などを挙げている。
 |
再構成法は,2000年代初頭に発表され,2010年前後にはテレビやディスプレイに採用が進んだ超解像アルゴリズムだ。国内企業では,東芝が同社製テレビ「レグザ」シリーズで超解像に対応した最初期のモデルに採用したことで有名になった。その後は国内外で多くのテレビや映像プロセッサで採用されたものの,レグザを含めた最新のテレビが採用している超解像処理エンジンは,再構成法から機械学習ベースの新手法へ移行が進んでいる。
その意味で再構成法は,かなりクラシックな手法と言える。再構成法のアルゴリズムについては,少々専門的な内容になるので,記事の最後でコラムとして説明したい。
話を戻すと,FSRには超解像処理の品質プロファイルが4種類あるそうだ。最も負荷が軽くて高いフレームレートを期待できるのが「Performance」で,品質と速度の折り合いを付けた「Balanced」,負荷は高いが超解像品質を重視する場合の「Quality」と「Ultra Quality」の4種類があり,Ultra Qualityは「かなりネイティブレンダリングに近い品質を実現できている」とAMDはアピールしている。
 |
デフォルト状態のFSRでは,4K(3840×2160ピクセル)解像度と1440p(2560×1440ピクセル)解像度への出力モードが用意されている。AMDによると,ゲーム開発者がFSRをカスタマイズすることで,入力解像度と出力解像度は変更できるそうだ。
FSRの4つの品質モードと,実際のGPUがレンダリングする解像度の対応は,次に示すスライドのようになっている。
 |
AMDは,実際のゲームにおけるFSRの実効性能を公開している。
次のスライドは,Godfallで「Radeon RX 6800 XT」(以下,RX 6800 XT)を用いて,ネイティブ4K,4K FSR Ultra Quality時,ネイティブ1440pで表示したときのフレームレートを示したものだ。
 |
次の「Terminator Resistance」では,Radeonではなく「GeForce GTX 1060」において,ネイティブ1440p時,1440p FSR Ultra Quality時,ネイティブフルHD(1080p)のフレームレートを公開している。
 |
これらの結果で興味深いのは,FSR Ultra Quality時の結果が,ちょうどネイティブ高解像度と,FSRの入力解像度(=実レンダリング解像度)におけるフレームレートの中間くらいになっている点だ。これは,FSRを有効化したときに得られる性能の目安として参考になりそうだ。
さらにAMDは,Godfallと「The Riftbreaker」,Terminator Resistanceにおいて,RX 6800 XTを用いた場合の各品質モードによるフレームレートの違いも明らかにしている。これを見ると,FSR品質をBalancedにしたときのフレームレートは,ネイティブ高解像度時の2倍近くまで,Performance時は2.5倍近くにまで上がることが見て取れよう。
 |
 |
 |
ユーザーが使っているディスプレイの最大リフレッシュレートを超えたフレームレートが得られてもあまり意味がないので,このフレームレート向上率を参考にして,FSRの品質モードを選択するといいだろう。
前述したように,FSRはCompute Shaderベースのシェーダプログラムであるため,さまざまなGPUとの互換性が高い。AMDは,実際にどのGPUでFSRが動作するのかも公表している。それによると,Radeon系はRadeon RX 400シリーズ以降,GeForce系はGeForce GTX 10/16シリーズ以降が対応するとのこと。なかなか幅広い。
 |
FSRは,ゲーム側が対応しないと利用ができないわけだが,AMDは今回のアナウンスで,現状で対応済み,あるいは対応予定のタイトルも発表している。早いものでは,6月22日から利用できるものもあるようだ。
 |
また,具体的な発表タイトルはないものの,FSRに賛同しているゲーム開発スタジオや,ゲームエンジン開発企業も明らかにしている。
 |
FSRの優位点,DLSSの優位点
さて,もともとFSRは,NVIDIAのDLSSに対抗する技術として投入されたものだ。
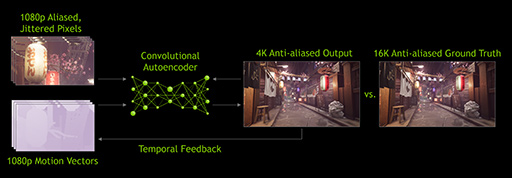
DLSSは,FSRと同じ超解像技術の一種ではあるが,「Deep Learning Super Sampling」の略語からも分かるように,深層学習(機械学習)型AIベースの超解像処理系である。ちなみに,ソニーの「ブラビア」シリーズや,東芝のレグザシリーズといった近年登場したテレビ製品に採用される超解像エンジンは,どちらかといえばDLSSに近い技術を用いているのが実情だ。
だがゲーマーにとって重要なのは,「FSRとDLSSのどちらがいいの?」という点だ。結論から言えば,優劣は付けがたい。どちらにも長所と短所があるからだ。
DLSSは,NVIDIAがGeForce RTXシリーズに搭載している推論アクセラレータ(俗に言うAI処理機能)であるTensor Coreを活用している。詳細は過去記事にあるが,DLSSは,処理系に与える学習データを切り換えることで,超解像処理だけでなくノイズ低減(デノイザ)やアンチエイリアシング(ジャギー低減)にも応用できるという技術だ。ただ最近は,超解像用途に用いる事例が多いようだ。
いずれにせよ,大前提としてDLSSを利用するためには,GeForce RTXシリーズが必要になる。つまり,GeForce GTXシリーズのユーザーはDLSSを利用できない。ここは留意すべき点である。
利点としては,「実処理にTensor Coreを活用するため,グラフィックスレンダリングに余計な負荷をかけない」という点が挙げられる。もともとTensor Coreは,AIベースの処理を高速化する目的で搭載されたものであり,NVIDIAとしては,GPUにTensor Coreが載っていることに価値を見出すために提供したのがDLSSなので,当たり前と言えば当たり前だ。
いずれにせよ,DLSSをオンにしてもオフにしても,グラフィックスレンダリングの負荷には一切の影響がない。ここはDLSSの利点だといえよう。
その一方で,FSRと比較した場合,DLSSのほうが実装難度が若干高めという問題点もある。
ゲームプログラム側に統合されていないと利用はできない点は,DLSSもFSRと同じだが,ゲームグラフィックス側でピクセル単位の動きベクトル情報(Motion Vector)を生成しなければならないのだ。
とはいっても,今どきのゲームグラフィックスでは,モーションブラー表現用に生成する中間バッファである「ベロシティバッファ」(Velocity Buffer)がそれなので,もともとそうした設計になっているゲームグラフィックスであれば,追加の手間はない。ただ,原画像を入力するだけで超解像化してくれるFSRよりも,パイプラインが複雑というのは確かであろう。
 |
それに対してFSRはどうか。
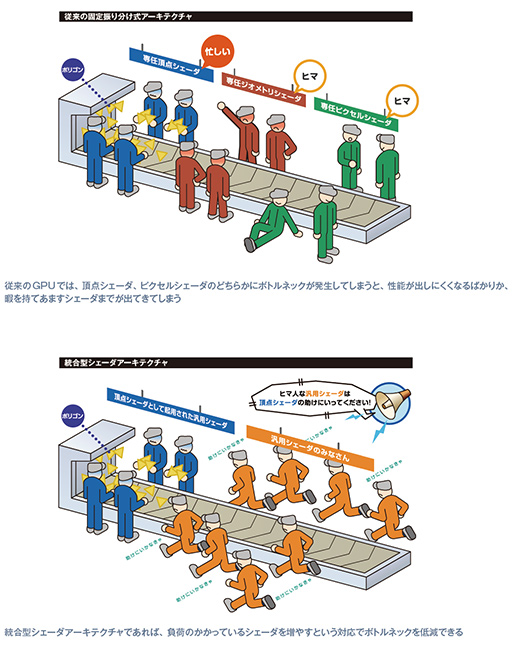
FSRは,Compute Shaderを活用して処理する,つまり,GPUのプログラマブルシェーダ(シェーダプロセッサ)を動員して処理するので,グラフィックスレンダリングに使えるプログラマブルシェーダが,多少は減ってしまうことを意味する。
DirectX 9世代以前のGPU(ゲーム機でいえばPlayStation 3以前)では,GPUのプログラマブルシェーダは,役割が固定化されていた。頂点シェーダは頂点シェーダの仕事しかできないし,ピクセルシェーダはピクセルシェーダの仕事しかできないわけだ。
しかし,DirectX 10世代以降のGPU(ゲーム機でいえばWii U以降)では,GPUに大量の汎用プログラマブルシェーダを実装し,処理の内容や負荷に応じて頂点シェーダやジオメトリシェーダ,ハルシェーダやドメインシェーダ,ピクセルシェーダ,Compute Shaderとして適宜起用する統合型シェーダ(Unified Shader)アーキテクチャとなった。
そのため,プログラマブルシェーダのいくつかはFSRの処理用にCompute Shaderとして使われるので,ほかの処理系に割り当てられる汎用プログラマブルシェーダの数が減ってしまう。FSRを利用した場合,GPUはプログラマブルシェーダのすべてを使ってゲームグラフィックスのレンダリングを行えないわけだ。
ここはちょっとモヤモヤとする部分であろうか。
 |
とはいえ,DLSSにおけるTensor Coreのような,特別な処理ユニットを必要とせず,旧世代も含めた比較的幅広いGPUで解像度が一段高いゲームグラフィックスを楽しめる恩恵は小さくない。
たとえば,フルHD解像度のディスプレイでゲームをプレイしているユーザーが,PCスペックはそのままに,ディスプレイだけを1440p解像度のディスプレイに買い替えたときなどに,FSRはそれなりに嬉しい機能ではあるとは思う。
AMDのFidelityFX Super Resolution解説ページ
コラム 再構成型超解像のアルゴリズム
ここからは,FSRで採用している(と思われる)再構成型超解像処理のアルゴリズムの解説をしようと思う。なお,再構成型超解像処理は,複数フレームを用いて処理する場合もあるのだが,ここで解説するものはテレビの映像エンジンなどでよく使われていた単一フレーム内で処理するアルゴリズムに限定している。
10年以上前では,超解像処理は専用プロセッサ(DSPなど)でなければリアルタイム処理ができなかったが,今ではCompute Shaderでリアルタイム処理ができるようになった。だからこそ,FSRのような技術も誕生したわけだ。
まず,概念を説明するためのたとえ話から入ろう。
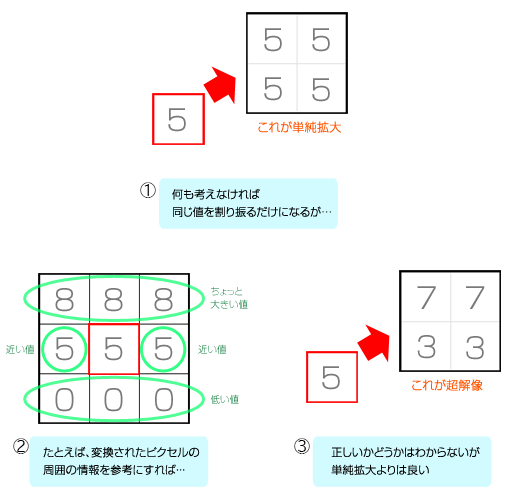
ある映像を縦横半分ずつ,つまりは4分の1解像度に縮小したとする。この場合,元映像の4ピクセルが1ピクセルになってしまう。そして,4分の1解像度になってしまった映像を,なるべく正確に本来の解像度に戻すことを試みるのが超解像度処理である。以降は,話を分かりやすくするために,白黒映像で説明しよう(フルカラーの場合は,たとえば赤緑青の3原色分の処理系に拡張する)。
4分の1解像度への縮小によって,元映像の4ピクセルが平均化されて「5」になった場合,元映像における4ピクセル分の合計値は,「20」であると推測できる。ただ,4ピクセルとも同じ「5/5/5/5」なのか,それとも「2/8/6/4」なのかは分からない。4ピクセルの値の合計が20になる組み合わせはたくさんあるからだ。
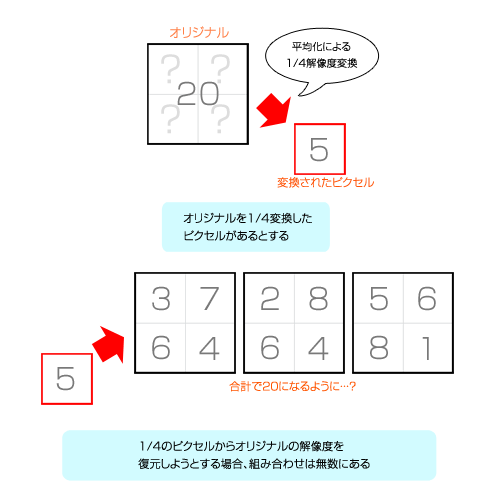 |
しかし,映像はランダムな数値の配列ではなく,近隣ピクセルとの強い相関性を持っている。この相関性を用いれば,正解に近い本来の4ピクセルを算出できるかもしれない。これが超解像処理の考え方の基本だ。
なお,今の例で5/5/5/5と平均化してしまうのが,最も単純な線形補間による解像度変換となる。
 |
では,どのように復元するのか。再構成型超解像を採用していた時代に東芝が使っていた説明資料が分かりやすいので,引用して説明しよう。
次のスライドにある折れ線グラフは,ある映像における横方向の輝度分布(水平走査線)である。グラフ内にある各点の高さは輝度の強弱(高低)を表すものだ。
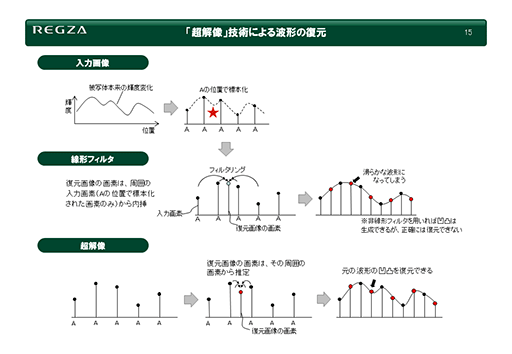 |
本来の画像は,スライド最上段にある「入力画像」左にある波形で表わす輝度変化をしている。それを右側にある「A」のタイミングでそれぞれピクセル化した場合,「★」マークを付けた凹み部分の情報を失ってしまう。ピクセル化した画像に対して,線形補間を行ってごく普通の線形フィルターで拡大すると,失った情報に隣接する2点間に適当な中間値(線形補間値)を差し込むことになる(図中段の「線形フィルター」)。
ただ,この方法では,欠落してしまった凹みの部分はへこまず,むしろ滑らかにつながれてしまう。冒頭で挙げたチェス盤の例でいうと,白マスと黒マスの境界線だったかもしれない部分が,白と黒の中間値の灰色でつながれてしまい,映像としてはぼやけてしまうことになるわけだ。
隣接する2点間を補う値を生成するときに,適当な非線形関数を使うことで凹凸を意図的に生成することもできる。ただ,それが失われた情報を復元している確証はないので,画像の解像度復元における正確性を期待できない。
そこで登場するのが,スライドの下段にある超解像技術だ。超解像技術では,ある画素とある画素の2点間を復元するとき,隣接する複数の画素情報における変化から2点間の情報を推測する。ここでいう隣接とは,図にある隣り合った水平走査線上の画素だけでなく,上下に隣接した走査線も調査対象とするのが一般的だ。
なお,対象のフレームと1つの前のフレームは似ている場合も多いので,DLSSのように過去フレームをバッファリングして,過去フレームも探索対象とするアイデアもある。ただ,FSRでは単一のフレームを処理対象としているとAMDが明言しているので,それはないだろう。
さて,これを踏まえたうえで,どのように解像度を復元するのか。
まず,超解像処理前の原画像に,より高解像度の画像が存在すると仮定した場合,原画像は何らかのフィルターを通って低解像度化されたことにより生成された,と見なせる。そうであれば,どんなフィルターを通ったのだろうか。
たとえば,解像度無限大の現実世界をフルHD解像度相当の撮像素子で撮影すると,その撮像素子がフィルターとなって,フルHD解像度の画像を生成したと考えられる。現実世界を撮影した場合,撮像素子におけるフォトセンサーの配列や電気特性に影響されるので,かなり非線形なフィルターになるはずだ。だが,CG映像の解像度変換であれば,このフィルターをシンプルなものと仮定しても問題ないだろう。
シンプルなフィルターとは,注目しているピクセルに大きな重みを置いたうえで,そこから離れれば離れるほど重みが減っていくボックスフィルターだ。
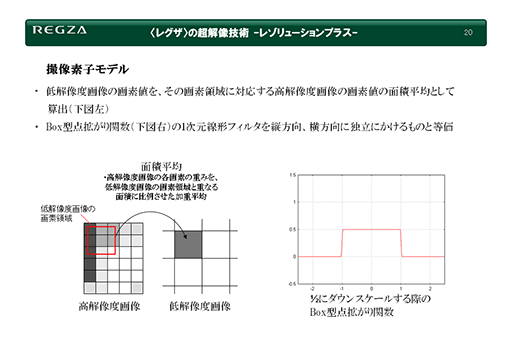 |
スライドの右側にあるボックスフィルターは,注目しているピクセルを中心「0」としたうえで,左右に隣接するピクセルも参照して加重平均を計算するものだ。両隣の重みは「0.25」ずつとし,中央は重み「0.5」とすれば,合計で「1」になる。
当時のレグザでは,このシンプルなボックスフィルターを仮想フィルター(撮像素子モデル)として採用していた。なお,実際の仮想フィルターは,横方向だけでなく縦方向にも効いていると仮定していた。斜め方向にも配慮すれば,さらに超解像の復元精度は上がるかもしれないが,FSRでどこまでやっているか分からない。
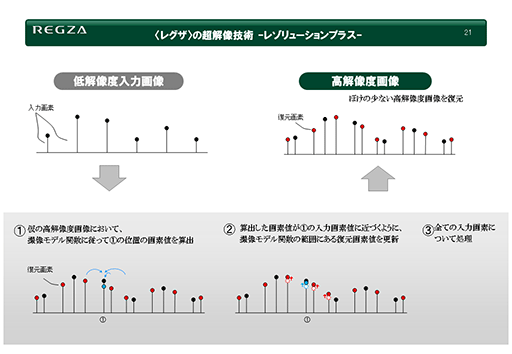
さて,こうした仮想フィルターによって原画像が作られたとすれば,仮想フィルターの処理を逆に行えば,高解像度の映像が生成できる理屈になる。この逆処理もまた,周囲のピクセルによる相関性を反映させることで計算するわけだ。その概念を解説したスライドを以下に示そう。
 |
このスライドでも,映像における横方向の輝度分布(水平走査線)を示したもので,グラフ内にある各点の高さは輝度の強弱(高低)を現す。
まず,入力画像を適当な手法で一段上の「仮の高解像度画像」へと変換する。これは,FSRのパイプラインにおける「Upscaling Pass」に相当するものだ。一段上の解像度へと変換する手法はバイリニア法でもトライリニア法でもいいが,この段階で高品位な手法を採用するほうが,最終的な超解像の品質も高くなる。当時のレグザではバイキュービック法を用いていたので,この説明でもバイキュービック法を用いたとして話を続けよう。
そして,生成した仮の高解像度画像を,仮想フィルターで入力画像と同じ解像度に縮小する。一見無駄なことをしているように思えるだろう。戻した画像の解像度は,当然ながら入力した変換前の原画像と同じになるが,拡大アルゴリズム(=バイキュービック法)と縮小アルゴリズム(=仮想フィルター)が異なるので,2つの画像は一致しないはずだ。
そこで,原画像と仮想フィルターを用いて縮小した画像を,各ピクセル単位で比較して差分を求める。これがスライドにある①の部分となる。
もし,2枚の画像の差分がゼロならば,バイキュービック法で求めた仮の高解像度画像におけるピクセル値は,正しく超解像処理されたと見なすことができ,これを正解のピクセル値として選ぶ。しかし差分があった場合は,2枚の画像が一致するように,バイキュービック法で生成した仮の高解像度画像にある復元した画素を補正する。
たとえば,差分がマイナス値だったら,仮画像側の復元画素にプラスをして,差分がプラス値だったら逆にマイナスするといった具合だ。ここは,FSRのパイプラインにもあった「Sharpening Pass」に相当する。
これらのパイプラインを図にしたのが次のスライドだ。
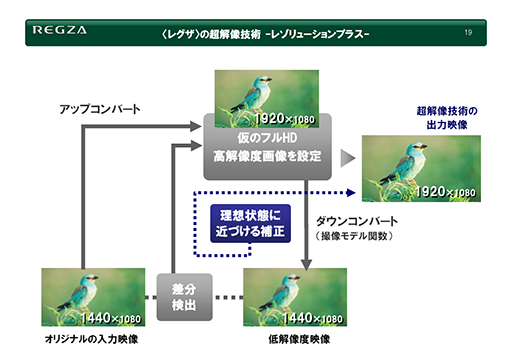 |
改めて大ざっぱにまとめると,当時のレグザが用いていた手法は,
- 入力の画像を仮の高解像度化で正しく超解像化できたなら,それをもう一度仮想フィルターで原画像の解像度に復元しても画像は一致するはず
- 一致しないならば,一致するように算出した復元した画素を修正してつじつまを合わせる
といった仕組みであるわけだ。モンテカルロ法の数値計算を彷彿とさせる「トライ&エラー的な手法」といえよう。
トライ&エラーによる数値計算は,何度も反復処理をすると,より正解に近づくことが知られている。しかし,反復回数分だけ計算量が増えるので,処理時間も増大する。当時のレグザでは,この反復が1ループでも十分なクオリティが得られたので,1ループで済ませる実装だった。FSRが再構成型超解像処理であった場合,おそらく1ループ分の処理系になっていることだろう。
想像するに,こうした局所的な演算が多いポストエフェクト処理は,キャッシュ効率の高い現代のGPUでは,かなり高速に処理できると思われる。とくにRadeon RX 6000シリーズは,Infinity Cacheアーキテクチャによってキャッシュ性能を極限にまで高めたとAMDはアピールしているので,FSRの処理系はかなり高速に行えるのではないだろうか。
- 関連タイトル:
 AMD Software
AMD Software
- この記事のURL:
(C)2019 Advanced Micro Devices Inc.
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー