













連載
西川善司の3DGE:Radeon RX 7900 XTX/XTは何が変わったのか。大幅な性能向上を遂げたNavi 31世代の秘密を探る
 |
RDNA 3アーキテクチャ採用のGPUは,開発コードネーム「Navi 3x」と呼ばれていて,今回発表されたRadeon RX 7900シリーズの開発コードネームは「Navi 31」となっている。
本稿では,事前に行われた技術説明会の情報をもとに,Radeon RX 7900シリーズのアーキテクチャについて考察と解説を行いたい。
 |
関連記事


![[レビュー]AMDの新世代GPU「Radeon RX 7900 XTX&XT」を試す。コストパフォーマンスはGeForce RTX 4090/4080をしのぐ](/games/660/G066019/20221212075/TN/001.jpg)
[レビュー]AMDの新世代GPU「Radeon RX 7900 XTX&XT」を試す。コストパフォーマンスはGeForce RTX 4090/4080をしのぐ
AMDの新世代GPUアーキテクチャ「RDNA 3」を採用した新型GPU「Radeon
チップレットアーキテクチャを採用したNavi 31
まずは,Radeon RX 7900シリーズについての基本情報を振り返っておきたい。
 |
AMDの言うチップレットアーキテクチャとは,プロセッサを単一のチップ(半導体ダイ)で製造するのではなく,要素を複数のチップに分けて製造したうえで,それらを1つのパッケージ上にまとめて相互接続して,ひとつのプロセッサとして仕上げる技術のこと。AMDは,この手法を2019年にリリースしたCPUのRyzen 3000シリーズから採用しているが,この発想をGPUに持ち込んだのは,Navi 31が初めてだ。
なお,チップレットとは,「小さいチップ」を意味する。最先端の半導体製造技術を用いたプロセッサは,クリーンルームで製造される。しかし,やはり一定の割合で不良品が発生するものだ。GPUのように,1チップで数百億個のトランジスタを使う超大規模なプロセッサにおいては,不良品が出たときのコスト的損害が大きい。そこで,機能要素ごとに分けて複数のチップを作ることで,1チップ当たりのトランジスタ数を削減して,不良率を低減しようとするのが,チップレットアーキテクチャの主たる意義である。
Navi 31は,TSMCの5nmプロセスで製造したGPUダイ「GCD」1基と,同じTSMCの6nmプロセスで製造したメモリコントローラとキャッシュメモリのダイ「MCD」6基を1パッケージにまとめたものだ。GCD 1基とMCD 6基からなるNavi 31の総トランジスタ数は約580億個。ちなみに,NVIDIAの最上位GPU「GeForce RTX 4090」(AD102)は約763億個,「GeForce RTX 4080」(AD103)は約459億個であった。
 |
チップレットアーキテクチャ採用の意義は,製造コストの低減にもある。
Navi 31の場合,GCDを比較的新しい5nmプロセスで製造して,MCDは,1世代古い6nmプロセスを用いることで,GPUダイ全体を5nmプロセスで製造するよりも,だいぶコスト削減ができたとAMDは述べている。
ちなみに,5nmと6nmでは大差がないように思えるが,「6nmプロセスは,事実上7nmプロセスのマイナーチェンジ版であるため,5nmプロセスと比較した場合,コストには大きな差がある」とAMDは述べており,実質的にはかなりコスト低減効果があったそうだ。
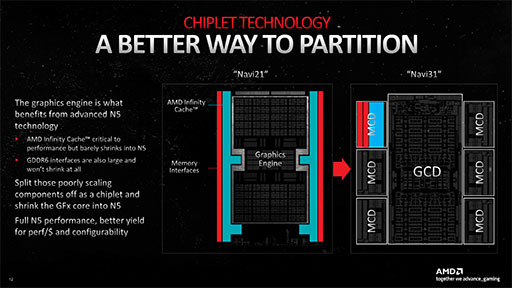 |
なお,チップレットアーキテクチャは,プロセッサ製品の製造コストを抑えるだけでなく,多彩なプロセッサ製品のバリエーション展開を,比較的低コストで実現するのにも貢献する。具体的な製品への応用は明らかにされなかったが,おそらくMCDについては,今後登場するであろうNavi 3系の下位モデルGPUにも使われることだろう。
Ryzenで経験を積んだインターコネクト技術でNavi 31を実現
チップレットアーキテクチャにはさまざまな優位点があるものの,PC向けGPUで,この技術を採用しているのは,今のところAMDだけだ(※CPUでは,Intelも同種のマルチダイ技術を採用済み)。競合他社がチップレット技術を採用していないことについて,AMDは,「ダイ間インターコネクト技術において,我々が圧倒的に先陣を切っているため」と主張する。
たしかに,プロセッサの構成要素をチップレットに分割できたとしても,それで性能が落ちてしまっては意味がない。
チップレットではない普通の単一シリコンダイによるプロセッサでは,内部配線のデータ帯域幅が数TB/sに達する。たとえば,RDNA 2世代の「Navi 2X」における大容量キャッシュメモリ「Infinity Cache」は,1.94GHzで駆動され,メモリバス帯域幅は約1.8TB/sに達していた。これをGPUコアとは別のダイに分けて,ダイ〜ダイ間通信を同等の速度で行うのは,技術的にとても難しいとAMDは主張する。
第一に,膨大な数となるダイ同士の入出力端子をつなぎ合わせなければならず,この配線が難しい。第二に,一度外部に引き出した配線で数TB/sの帯域幅を実現するのも難しい(※「Radeon RX Vega」シリーズや「GH100」は,HBM2を用いて2TB/sのメモリバス帯域幅を実現している)。
どのくらい難しいのかは,半導体製造の専門家ではない我々には想像しにくいが,AMDはすでに,Zen 2以降でCPUダイとI/Oダイをパッケージ上で相互接続する技術を確立している。実際,今回のGPUにおけるチップレットアーキテクチャの採用には,Zen 2〜4の経験が生きたそうである。
しかし,簡単にできることではなかったという。GCDとMCDとの相互接続は,Zen 2系CPUダイとI/Oダイの相互接続と比べて,10倍の帯域幅と配線密度が求められたためだ。GPUは,コア(Radeon用語ではCompute Unit)がCPUコアの10倍近くあり,トータルでの演算器数は1000倍近くにもなる。そうなると,GCDとMCD間のバス帯域幅が10倍くらいになるのも不思議ではない。
 |
試行錯誤の末,Navi 31では,GCDとMCD間の1リンクあたりにおける帯域幅は,9.3Gbpsを達成。このリンクは,Ryzenのダイ同士を結ぶ内部インタフェース「Infinity Fabric」とは異なる新規に設計したものであり,「Infinity Link」という名称が付けられた。結果的に,GCD〜MCD間のInfinity Linkの総帯域幅は,5.3TB/sを実現できたそうだ。
次のスライドは,Navi 31におけるGCD〜MCD間配線を拡大した写真である。
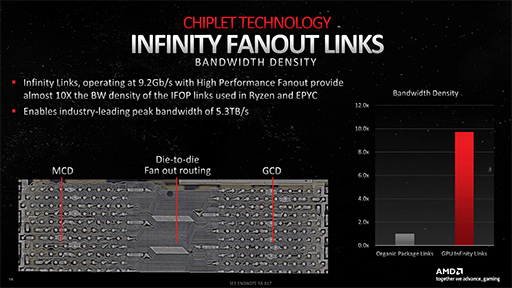 |
これだけでは,その難しさがピンとこない人も多いかもしれないので,AMDは,Zen 2世代のInfinity Fabricと,Navi 31におけるInfinity Linkの顕微鏡写真を比較したスライドを披露した。写真左がZen 2,写真右が同スケールのNavi 31における配線で,たしかにこれは大変そうだ。
 |
ちなみに,AMDによる技術説明会では「Appleが『M1 MAX』で行ったような,ダイとダイを貫通して直接配線するTSV(Through Silicon Via)技術の適用は考えなかったのか」という質問があった。これに対してNaffziger氏は,「写真を見てもらうと分かるが,この密度と数の配線ポイントをTSVでつなぐのは,2022年時点の半導体技術では無理だ」と答えている。
CPUでチップレットアーキテクチャを実用化してきたAMDですら苦労した,GPUのチップレットアーキテクチャ化を,競合他社がすぐに真似るのは難しそうである。
気になるのは,GCD〜MCD間配線による遅延が,単一ダイでGPUを実現したときと比べてどうなのか,というところ。これについてNaffziger氏は,「GPUをまるごと単一ダイで構成するよりは,理論的に遅延は増えている」と認めつつも「Radeon RX 6900シリーズ(Navi 21)と比較して,10%は低遅延になった」と述べている。
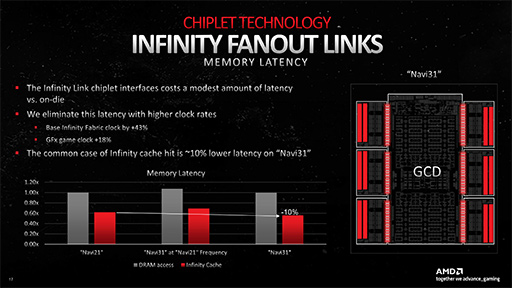 |
その秘密は,Infinity Fabricよりも43%,Navi 31のGPUコアクロックよりも18%も高いクロックでInfinity Linkを動作させているからだとのこと。Infinity Linkを高クロックで動作できたからこそ,GCDとMCDの2種類によるチップレットアーキテクチャを活用して,Navi 31を完成させることができた,ということなのだろう。
RDNA 3でCUを増やずに,SIMD32演算器を増やした理由とは?
AMDは,GPGPU用途向けのGPUアーキテクチャとして「CDNA」を有しており,「Radeon Instinct」ブランドとして製品を展開している。ただCDNAは,実のところRadeon HD 7000シリーズから始まったGCNアーキテクチャの名前を換えたものだ。
一方でAMDは,グラフィックスレンダリング特化型GPUとして,2019年からRDNAアーキテクチャをRadeon RX 5000シリーズからスタートさせている。
 |
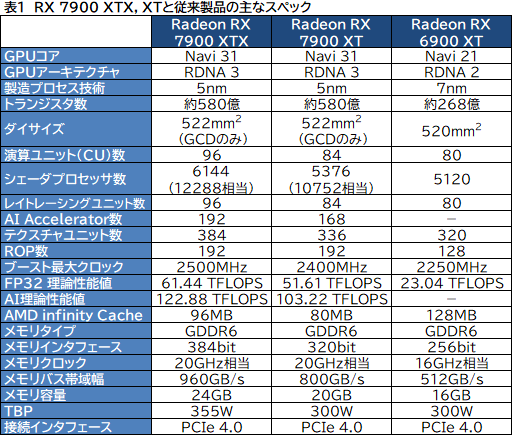
今回発表となったNavi 31は,第3世代のRDNAということで「RDNA 3」というアーキテクチャ名が与えられた。ここからは,Navi 31とRDNA 3の詳細を見ていこう。まずは,いつものスペック表を示しておく。
 |
Navi 31全体のブロック図は以下のとおり。
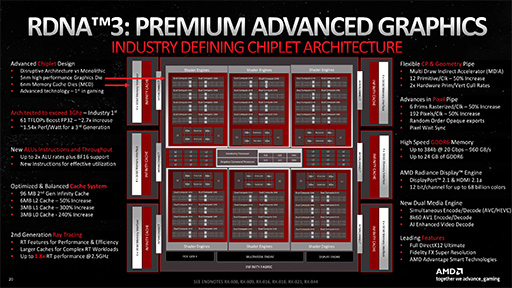 |
参考までに,RDNA 2ベースの最上位GPUであるRadeon RX 6900(Navi 21)系のブロック図も示しておこう。
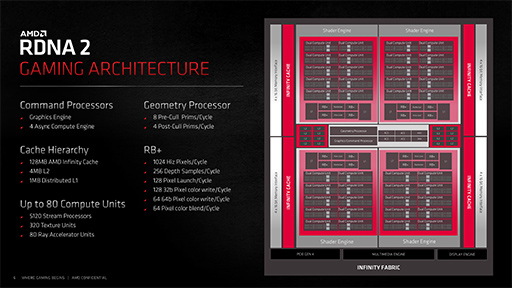 |
こうして見比べると,Navi 31はNavi 21をベースに,一回り巨大化した上位モデルGPUにおけるブロック図を見ているようで,世代が変わったGPUのように見えないかもしれない。
目立つところでは,ミニGPU的なクラスタである「Shader Engine」や,Infinity Cache(≒L3キャッシュ)とメモリコントローラのブロックが,それぞれ4基から6基に増えたところだろうか。スペック表を見ても,Radeon RX 7900 XTXのCU数は,96で,Navi 21世代で最上位のRadeon RX 6900 XT(80基)から,16基しか増えていない。
にもかかわらず,Radeon RX 7900 XTXの理論性能値は,Radeon RX 6900 XTの約2.7倍に達している。ここが,最も根本的なRDNA 3アーキテクチャの進化点だ。
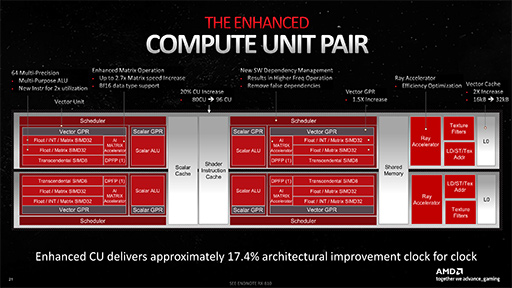
次のスライドは,RDNA 3におけるCUの拡大図である。Radeonのアーキテクチャが,GCNからRDNAに変わったとき,AMDは,2つのCUを1グループとして「Work Group Processor」(WGP)と呼ぶようになった。RDNA 2になると,WGPを「Dual Compute Unit」と呼ぶこともあったのだが,今回は「Compute Unit Pair」(以下,CU Pair)という名称になっている。ただ,今回も全体ブロック図ではDual Compute Unitと書かれているのでややこしい。
 |
 |
いずれにせよ,2つのCUで,命令キャッシュやスカラ命令実行用のデータキャッシュ,スクラッチパッド的な活用ができる共有メモリなどを共有する構造は,RDNA 2の時から変わらない。それを含めて,以下に列挙する部分は,RDNA 2から大きな仕様変更はないと理解していい。
- Shader Instruction Cache:命令キャッシュ
- Scalar Cache:スカラ命令用のデータキャッシュ
- Shared Memory:共有メモリ
- Scalar ALU:スカラ命令実行ユニット
- Scalar GPR:スカラ命令用の汎用レジスタ
- Transcendental SIMD8:超越関数SIMD8命令実行ユニット
- DPFP:倍精度浮動小数点ベクトル命令実行ユニット
- LD/ST/Tex Addr:ロード/ストア/テクスチャアドレス計算命令実行ユニット
- Texture Filter:テクスチャユニット
また,構造に変化はないものの容量が増えたのは,以下の2項目だ。
- Vector GPR:ベクトル命令用の汎用レジスタ,1.5倍増
- L0:ベクトル命令用のL0データキャッシュ,2倍増
なお,レイトレーシング命令実行ユニットである「Ray Accelerator」は機能拡張されているが,ここは重要なので後段で解説しよう。
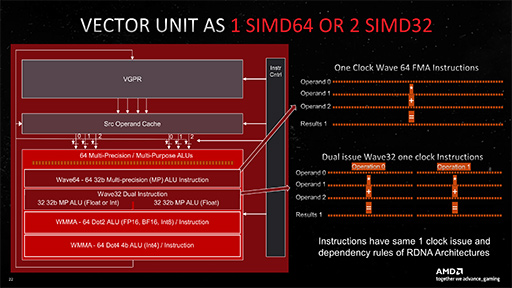
CU Pairで,まず注目すべき点は,SIMD32演算器がCU 1基あたり4基になっていることだ。CU Pair 1基あたり8基と言い換えてもいい。ちなみにSIMD32とは,1命令で32要素のデータに対して,同時に計算できる演算器のことだ。RDNA 2では,SIMD32演算器がCU 1基あたり2基(=CU Pair 1基あたり4基)だった。RDNA 3ではSIMD32演算器が2倍に増えたので,実質的にシェーダプロセッサの演算性能は,2倍になったことになる。
RDNA 3において,Vector GPRとL0キャッシュが増えた理由もここにあり,SIMD32演算器が倍増したので,それに見合ったレジスタ数やキャッシュ容量にしたわけだ。
RDNA 2では,32要素のデータスレッド「Wave32」を,CU 1基が1クロックで2つ処理できる性能を有していた。64要素のデータスレッド「Wave64」は,CU内にある2基のSIMD32演算器で「2セットのWave32」として処理するので,これまた1クロックで処理できていた。
それに対してRDNA 3では,SIMD32演算器が2倍に増えたので,Wave32はCU 1基で1クロックあたり4つ,Wave64は1クロックあたり2つを同時に処理できるようになっている。
スペック表で,CU数が96基なのに理論性能値が爆上がりしていたり,シェーダプロセッサ数にAMD公称値だけでなく2倍のRDNA 2相当値を併記しているのは,そういう理由だ。
 |
なお,追加されたSIMD32演算器は,元々あったSIMD32演算器と完全に同じ機能ではない。元々あったSIMD32演算器は,CUのブロック図で「Float/INT/Matrix SIMD32」と書かれたもので,整数のベクトル演算や行列演算に対応している。一方で,追加されたSIMD32演算器は,ブロック図で「Float/Matrix SIMD32」となっているもので,整数演算には対応しない。
ここまで踏まえたうえで,Navi 31の理論性能値を計算してみよう。
Radeon RX 7900 XTXの総CU数は96基。動作クロック(ブーストクロック)は2.5GHzだ。CU 1基あたりSIMD32演算器が4基あり,各SIMD32演算器は,32個の32bit浮動小数点数(FP32)に対して積和算(2 FLOPS)ができるので,その理論性能値は,
- 96 CU×4基のSIMD32演算器×32基のFP32演算器×積和算×2.5GHz
で計算できる。つまり,以下のとおりだ。
- 96×4×32×2×2.5GHz=61.44 TFLOPS
同様にRadeon RX 7900 XTの性能は以下のとおり。
- 84×4×32×2×2.4GHz=51.61 TFLOPS
 |
筆者が,AMDのアーキテクトであるAndy Pomianowski氏(Radeon Product Architect,AMD)に質問したところ,「たしかに,CU自体を増加させたほうが,GPUとしての性能はさらに向上して,より複雑性の高いレンダリングを実現可能となることは間違いない。しかし,その場合は設計が複雑化して,トランジスタ数の増加率は相当に高くなるので,製品価格に大きく響く。我々は,設計初期段階における実験で,直近のゲームグラフィックスにおけるGPU活用の動向を精査した結果,SIMD32の増加で十分にユーザーを満足させることができるだろうという確信を得た。そうした総合的な判断から,このような設計方針となった」と説明している。
CU数が増加するということは,異なるシェーダプログラム(の命令)を同時に実行できる並列度が上がったり,その実行効率が向上することを意味する。具体的には,さまざまな材質表現シェーダを実行したり,影描画やポストエフェクト処理,Compute Shader(GPGPU)処理など,異なるレンダリングパイプラインを実行したりといったことの効率が上がる。
一方で,CU数は増やさず,CU内の演算器を増やした場合,1つのシェーダプログラムが扱うデータスレッドの実行効率が上がる。具体的にいえば,ジオメトリではポリゴン数の多いシーンの描画効率が上がり,ピクセルでは高い解像度の描画効率が向上するといった具合だ。つまり,AMDはRDNA 3において後者の手段,つまり並列度より実行効率の性能向上を狙ったということになる。
推論アクセラレータ「AI Accelerator」はどう使う?
CU Pairにおける,もうひとつのホットトピックは「AI Accelerator」だ。これは,NVIDIAのGeForce RTXシリーズに搭載する推論アクセラレータ「Tensor Core」に相当するものである。Intelも,単体GPUの「Intel Arc」シリーズに同種の「Xe Matrix Engine」(XMX)を搭載しているので,GPUへの推論アクセラレータ搭載では,AMDが少々出遅れてしまった。
Navi 31が搭載するAI Acceleratorは,CUあたり2基の構成で,1基あたりのAI Acceleratorは,32bit SIMD積和算器である「Wave Matrix Multiply Accumulate」(WMMA)を64基搭載する。32bit演算器であるWMMAは,実際のところ,AI関連処理に特化した行列演算器であり,取り扱える数値形式は以下に限定される。FP32には対応しない。
- 16bit浮動小数点(FP16)
- BF16(bfloat16:符号1bit,指数8bit,仮数7bit)
- 8bit整数(INT8)
- 4bit整数(INT4)
なお,INT8を扱うときも,SIMD並列度はFP16,BF16と変わらない。INT4でようやく並列度が上がる。
それでは,AI Acceleratorの理論性能値を求めてみよう。AI処理分野の事例としては最も一般的なFP16で考えてみる。
AI AcceleratorのWMMAは64基あり,それぞれがFP16における2要素の積和算(2 FLOPS)に対応しているので,1クロックあたりのスループットは以下のとおり。
- 64 WMMA×2要素×2 FLOPS=256 FLOPS
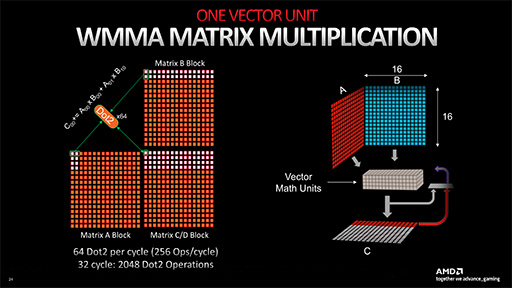 |
CU 1基あたり,AI Acceleratorを2基搭載しており,Navi 31はCU数が96基なので,1クロックあたりのFP16理論性能値は以下のとおり。
- 256 FLOPS×2 AI Accelerator×96 CU =49152 FLOPS
WMMAはGPUコアクロックで駆動されるので,Radeon RX 7900 XTXの2.5GHzをかけてやれば,GPU全体のAI AcceleratorのFP16理論性能値が出てくる。
- 49152 FLOPS×2.5GHz=122.88 TFLOPS
同じようにRadeon RX 7900 XTについて計算してみると,以下のようになる。
- 256 FLOPS×2 AI Accelerator×84 CU×2.4GHz=103.22 TFLOPS
ちなみに,Intelの「Intel Arc A770」(以下,Arc A770)のXMXも,理論性能値を求めてみよう。
Intel Arc系GPUは,XMX 1基あたりの理論性能値がFP16の場合で128 FLOPSだ(関連記事)。Arc A770はXe Coreが32基あり,XMXは,Xe Core1基あたり16基ある。動作クロック2.1GHzのArc A770全体では,XMXのFP16理論性能値は以下のとおり。
- 128 FLOPS×32 Xe Core×16 XMX×2.1GHz=137.63 TFLOPS
これまた参考値だが,GeForce RTX 4090におけるTensor CoreのFP16理論性能値は330.3 TFLOPSで,GeForce RTX 4080が195 TFLOPSだった。
つまりRadeon RX 7900シリーズは,グラフィックス性能のわりに推論アクセラレータの性能はやや低いことが分かる。Arc A770よりも低いことには,ちょっと驚かされた。
それはそれとして,Radeon RX 7900シリーズにおいて,AI Acceleratorは何に活用できるのだろうか。Navi 31の技術説明会において,AMDはAI Acceleratorの活用手法を明確に示していない。筆者が業界関係者に取材した範囲では,どうやら当面は,「Shader Model 6.4」(以下,SM 6.4)からの活用になるようだ(関連リンク)。
SM 6.4では,機械学習向けの組み込み関数が定義されており,推論アクセラレータによって超高効率に演算できる2要素や4要素の行列積和算命令をサポートしているのだ。用途によって変わってくるだろうが,実際の活用は,多くのケースでCompute Shaderから使うことになるだろう。
SM 6.4で推論アクセラレータを活用することによる最大のメリットは,互換性の高さだ。SM 6.4で書かれたシェーダコードは,もし,そのGPUが推論アクセラレータを搭載していなくても,シェーダプロセッサ側を活用して実行できるのであれば,とりあえず動くSM 6.4コードを出力できるのだ。もちろん,実行速度は推論アクセラレータを活用したほうが速いだろうが,とりあえず動かすことはできるので,互換性の面でメリットは大きい。
IntelのXMXは,まさにこの仕組みを実用化している。
IntelがIntel Arc向けに提供している超解像&アンチエリアス技術「XeSS」のAI処理系部分は,SM 6.4ベースのシェーダコードで書かれている。そのためSM 6.4に対応したGPUであれば,Intel Arc GPUでなくてもXeSSが利用できてしまう。
次の画像は,実際にGeForce RTX 4090でPC版「Marvel's Spider-Man Remastered」を実行して,XeSSの有効と無効を切り替えた様子だ。
 |
 |
XeSSは本作だけでなく「DEATH STRANDING」や「Shadow of the Tomb Raider」で,Intel Arc以外のGPUで有効にできることを,筆者は確認している。
Microsoftは,Windowsにおける機械学習向けAPI「DirectML」でも,GPUアクセラレーションを活用する場合は,SM 6.4に対応することを要求している。NVIDIAのCUDAフレームワークの優位性が揺らぐことは,すぐにはないだろう。しかし,「GPUメーカー各社のGPU内推論アクセラレータは,GPUメーカー独自のフレームワークからしか使えない」という状況は,解消されつつあるようだ。
容量が減ったInfinity Cacheだが実効性能に影響なし?
キャッシュメモリも少し詳しく見てみよう。
AMDは,2017年発表の「Radeon RX Vega」シリーズから,「キャッシュ周りの最適化技術こそが,GPUにおける安定的な高性能を引き出すための鍵となる」ことを重点に置いて,GPU開発に取り組んできた。Vega世代では,事実上のグラフィックスメモリとして第2世代High Bandwidth Memoryである「HBM2」を採用。HBM2を,GPUコアから見たキャッシュメモリとして扱う新メモリシステム「High-Bandwidth Cache」システムを導入した(関連記事)。
しかし,その後もHBMの実装コストが下がらなかったこともあってか,AMDは,RDNA世代にて,グラフィックスメモリを一般的なGDDR系に戻している。
具体的には,AMDは初代RDNAでキャッシュ階層構造を最適化して,グラフィックスメモリへの実アクセス頻度を極力低減した。その方向性を進めたRDNA 2では,最大128MBもの大容量ラストレベルキャッシュ(LLC)システム「Infinity Cache」を搭載することで,HBM並みのグラフィックスメモリアクセスが可能になったとアピールしたわけだ。
RDNA 3のキャッシュ構造は,RDNA 2での方針をそのまま継承している。RDNA 3とRDNA 2のキャッシュ階層構造図を示そう。
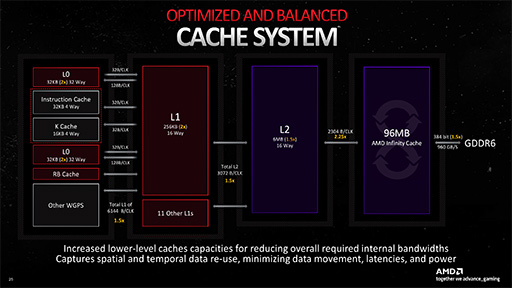 |
 |
まず,L0キャッシュについてだが,CU Pairのところですでに触れたように,各CUに対するSIMD32演算器の倍増にともなって,容量はCU 1基あたり2倍の32KBとなった。そのため,CU 96基仕様のNavi 31では,L0キャッシュ総容量が3MB(=32KB×96)となる。
L1キャッシュは,CU Pairの4基ごと(=CU 8基)ごとに1セットという構成は,RDNA 2から変わらず。ただ,こちらもSIMD32演算器の倍増にともなって,容量256KBへと倍増している。よって,Navi 31でのL1キャッシュ総容量は3MB(=256KB×96÷8)だ。
L2キャッシュの設計思想もRDNA 2と同じで,L1キャッシュと内容が被らない仕組みを採用して,GDDR6メモリインタフェースの1チャネルあたり256KBを割り当てている。Navi 31のブロック図中央付近にある「L2」の個数からも分かるように,24チャネル分あるのでL2キャッシュ総容量は6MB(=256KB×24)となった。ちなみに,RDNA 2のNavi 21では4MB(=256KB×16)だったので,Navi 31で1.5倍に増えたことになる。
さて,Infinity Cacheと呼ばれるL3キャッシュメモリ,事実上のラストレベルキャッシュ(LLC)は,GDDR6メモリインタフェースと対になる形で実装されている。この設計思想も,RDNA 2と変わらない。ただしRDNA 3では,Infinity Cacheと64bit幅のGDDR6メモリコントローラがMCDとしてチップレット化されたのが大きな違いだ。
なお,1基のMCDは,16bit×4チャネル構成で64bit幅のGDDR6インタフェースを備える。RDNA 2のNavi 21では,1チャネルあたり16bitのGDDR6メモリインタフェースが16チャネルという構成だったが,これがRDNA 3のNavi 31になると,1チャネルあたり16bitのGDDR6メモリインタフェースが24チャネルに増えたわけだ。
ここで興味深いのが,RDNA 2では1チャネルあたりのInfinity Cache容量は8MBだったのに対して,RDNA 3では4MBへと半減したことだ。ただ,総チャネル数は増加しているので,Navi 31におけるInfinity Cache総容量は,4MB×24チャネル=96MBになる。
RDNA 2のNavi 21では,8MB×16チャネルの128MBだったので,Infinity Cacheの容量自体は,Navi 31の方が少なくなっているのだ。
この仕様についてPomianowski氏に質問したところ,「たしかに容量は4分の3へと減ったが,L2キャッシュとL3キャッシュ(Infinity Cache)の帯域幅は2.25倍に増加しているので,我々の性能検証において必要十分な容量と判断した」と答えている。
キャッシュ階層構造図を見比べると,Navi 21で1クロックあたり1024byteだったL2〜L3キャッシュ間の帯域幅は,Navi 31で1クロックあたり2304byteへと向上したことが分かる。この「2.25倍」という数値が「1.5×1.5」(1.5の二乗)であることに気がついた人は,値の意味にも気づくだろう。Navi 2x〜3xアーキテクチャにおいて,L2キャッシュとL3キャッシュは,メモリインタフェースのチャネルに紐付けられたキャッシュメモリだ。そのL2/L3キャッシュのどちらも,Navi 31では16チャネルから24チャネルへと1.5倍ずつチャネル数が増えているので(1.5×1.5),その恩恵を受けているわけだ。
さらにPomianowski氏は,「GDDR6の動作クロックは,Navi 2x時の16GHzに対して,Navi 31では20GHzへと上がっており,メモリインタフェースの幅も256bitから384bitへと広がった。つまり,グラフィックスメモリの帯域幅自体がだいぶ向上したので,Infinity Cacheの容量は96MBで十分と判断した」とも述べていた。
Navi 21のメモリ帯域幅は,512GB/s(=256bit×16GHz)である。それに対してNavi 31のメモリ帯域幅は,960GB/s(=384bit×20GHz)となっており,約1.9倍も向上した。RDNA 2では「Infinity Cacheのヒット率が下がるとメモリ性能が足りない」という弱点を抱えていたが,RDNA 3ではそもそもメモリ帯域幅を向上したことで,弱点を大きく改善したというわけである。
第2世代レイトレーシングユニットはどう変わった?
AMDは,RDNA 2世代でリアルタイムレイトレーシングへの対応を実現したわけだが,RDNA 3では,レイトレーシング実行ユニット(以下,レイトレーシングユニット)が第2世代へと進化した。
NVIDIAのGeForce RTX 40シリーズは,ずいぶんと手の込んだ改良をレイトレーシングユニットに施してきただけに(関連記事),RDNA 3における第2世代レイトレーシングユニットの改善は気になるところだ。
■改善点1:Ray Flagのハードウェア処理
ひとつめの改善ポイントは,「Ray Flag」(関連リンク)へのハードウェア対応が挙げられている。結論から言ってしまうと,イメージ的にはNVIDIAが「Ada Lovelace」(以下,Ada)世代のGeForce RTX 40シリーズで実装した「Opacity Micromap Engine」の超簡易版的な機能になる。
レイトレーシングでは,3Dシーンに存在する3Dモデルを形作るポリゴンとの衝突を取る目的を持って,レイを3Dシーンへ放つ。ただ,何も考えずにこれをやると,3Dシーン内に存在する全ポリゴンとレイの総あたり計算になってしまって,とてもではないがリアルタイムなレイトレーシング描画は実現できない。
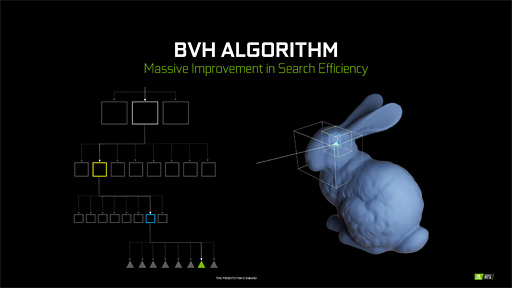
そこで,3Dシーン内に存在する3Dモデルを,3Dモデル全体を覆う最小体積の直方体を3D座標軸に平行,垂直な向きに揃えた「Axis Aligned Bounding Box」(軸平行境界ボックス,以下 AABB)で管理する。そのうえで,AABBの直方体を階層構造にしたような「Bounding Volume Hierarchy」(以下,BVH)と呼ばれる構造体に対してレイを放つ仕組みを採用することで,計算量を減らすのがリアルタイムレイトレーシングの定石だ。
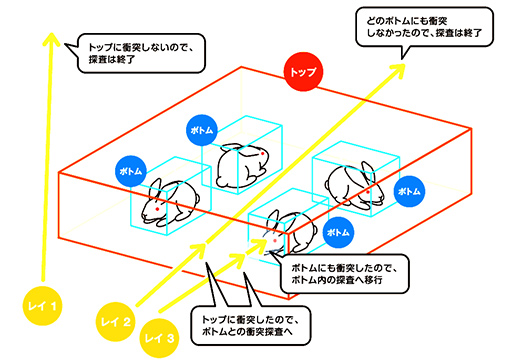 |
具体的には,レイと直方体が衝突したら,衝突の探索範囲をひとつ下の階層にある小さな直方体内に切り替えるという処理を繰り返して,最下層の直方体に含まれるポリゴンを突き止める仕組みを使って,レイとポリゴンの判定を行っている。
この仕組みなら,レイと直方体との判定は単純な座標判定の組み合わせで行えるし,上階層の直方体で衝突しなかったとすれば,その直方体サイズ分だけレイがワープしたかのように先へと進められるので,効率よくレイを処理できるのだ。3Dモデルが何も存在しない空間も,この仕組みで一気にワープできる。
 |
極端な例だが,たとえば,3Dシーンに半透明の「お化け」がいたとする。正確性を重視するならば,お化けもレイトレーシングで正しく描画すべきだ。しかし「お化けの像は,従来のラスタライズ法で描画するし,半透明のキャラクターは,周囲に及ぼす間接光や透過光,遮蔽の影響が少ないから無視しよう。だから,レイトレーシングの描画対象には含めなくていいことにする」と判断したとする。
その場合,Ray Flagを駆使すると,お化けを囲むAABB直方体を無視したり,レイの衝突判定から除外できる。
 |
RDNA 3では,このRay Flagの判定を,ハードウェア的に行えるような拡張を施した。AdaのOpacity Micromap Engineは,ポリゴンに貼り付けたテクスチャの内容も考慮する高度な衝突判定を行う仕組みが搭載されたが,RDNA 3のRay Flagは,そこまで踏み込んだ機能ではない。一方,Adaの新機能は,既存の「DirectX Raytracing」からは使えず,NVIDIA独自の拡張APIを通して使わなければならないのに対して,RDNA 3のRay Flag処理ハードウェアは,既存のレイトレーシング対応ゲームでも使えるところがポイントになる。
■改善点2:ハードウェアによるBVHのソーティング
レイトレーシングユニットにおける2つめの改善ポイントは,レイを放ってからのBVH探索に2種類のバリエーションを追加するものだ。具体的には,レイトレーシングを使って描画するテーマごとに,BVH内にあるAABB直方体の順序を最適な順序に並び替える機能である。
放ったレイが3DシーンにおけるどのAABB直方体に衝突するか,という探索工程は,実際の処理としては,グラフィックスメモリ上に記録されたデータ列に対する検索になる。そこで,データ列(AABB直方体データ)の順番を,レイトレーシングの目的ごとに専用ハードウェアを使って並べ変える仕組みを,RDNA 3の新レイトレーシングユニットで提供するのだ。
次に示すスライドの一番上「Close First」は,通常の探索モードで,中央と下が新設の探索モードになる。
 |
中央の「Largest First」は,放たれたレイが横切ると予想される直方体を,サイズが大きい順に並べ直すというものだ。放たれたレイは,最初に大きなものに衝突するので,影生成に向いた仕組みであるという。
確かに影生成においては,視点から光源に向かってレイを飛ばしたとき,手前に小さいオブジェクトがいくら並ぼうが,結局は大きいオブジェクトが光をすべて遮蔽してしまうので,手前のものすべてを影で飲み込んでしまう。つまり,影生成を目的としたレイトレーシングの場合,大きいオブジェクトとのレイの衝突判定を早く行えるほうが処理を早く終えられる可能性は高くなるのだ。
下段の「Closest Midpoint First」は,放たれたレイが横切る直方体の中心点を求めて,レイの発射元から近い順に並べ替えるというものだ。このモードは,レイの発射元から近いものが一番影響を及ぼす映り込み表現や,間接光表現などに向いているという。ゲームグラフィックスの場合,注目しているピクセル位置(レイの発射元)から遠いオブジェクトは影響が少ないと判断して,無視しても問題ないと判断することも多いため,そういった目的のレイトレーシングには都合がいい。
■改善点3:不要なテクスチャ読み出しを捨てる
3つめのレイトレーシングユニット改善ポイントは,下に示すスライド内にある「青と赤のマス」で書かれた図の機能だ。
ただ,説明会で行われたスライドに対する説明では,まったく理解できなかったので,AMDのChief GPU ArchitectであるMike Mantor氏に直接解説してもらい,ようやく理解できた。
 |
 |
まず,大前提として,レイトレーシング処理においても,ライティングや陰影処理の実処理は,レイトレーシングユニットではなくプログラマブルシェーダが行う。これを踏まえたうえで,レイトレーシングの処理系を考えてみる。
レイが衝突したポリゴンに設定された材質ごとの陰影計算は,呼び出されたプログラマブルシェーダが行う。このときにプログラマブルシェーダは,材質表現に紐付けられているテキスチャを読み出す。テクスチャの読み出しには,テクスチャアドレスの計算が必要であり,そのテクスチャにMIP-MAPが設定されていれば,MIP-MAPレベルの計算も必要だ。そのうえ最終的なテクスチャ読み出しは,1点読み出し(ポイントサンプル)ではなく,MIP-MAPを絡めて複数点を読み出してから,特殊加重平均(異方性フィルタリングなど)をとって最終的な読み出し値とする。
「この処理系が,現在のリアルタイムレイトレーシング技術においては,ボトルネックになりやすい」とMantor氏は述べる。
RDNA 2では,上で説明した処理系を言葉は悪いが馬鹿正直に,プログラマブルシェーダ側からテクスチャユニットを起用して行っていた。馬鹿正直にやることの何が問題かといえば,MIP-MAPレベルの計算段階で,「テクスチャを読んでも読まなくても,結果は同じでしょ?」というレベルのレイに対しても処理が行われてしまうことだ。
それがRDNA 3では,プログラマブルシェーダ側に陰影処理を発注する前に,レイトレーシングユニット側から,対象テスクチャのMIP-MAPレベルの計算を行える機構を導入した。これが最適化の第1段階となる。
最適化の第2段階は,テクスチャを読んでも読まなくても結果は同じと見込まれるリクエストを捨てる処理系の盛り込みだ。これによって,本当に必要な陰影処理だけをプログラマブルシェーダ側で行えるわけだ。
ここでスライドの図を振り返ってみよう。青のマスは,有効な衝突レイによるテクスチャ読み出しリクエストで,赤いマスは読んでも読まなくてもいいリクエストを示す。そして,有効なテクスチャ読み出しだけは有効化して,不要なテクスチャ読み出し(赤いマス)は捨ててしまう,という説明だったわけである。
|
Mantor氏は,「リアルタイムレイトレーシング技術において,テクスチャフィルタリング処理は,非常に重要な処理ポイントになっている。ここの効率を高めることは,レイトレーシングの性能と画質の両方を改善することになる」と,レイトレーシングユニットに対する3つめの改善における意義を述べていた。この改善も,既存のレイトレーシング対応ゲームに対して効くそうなので,即効性が高そうである。
そのほかにも,再帰的なレイトレーシングパイプラインが実行されたときの性能向上のために,スタック管理をハードウェアで処理したり,「Vector GPR」(ベクトル命令用の汎用レジスタ)をRDNA 2比で1.5倍増量などが挙げられるとのことである。
NVIDIAが,Ada世代におけるレイトレーシング機能の拡張ポイントをみっちり時間を割いて説明していたのに比べると,ボリューム的にはあっさりしてはいた。しかし,このパートを解説したMantor氏は「既存のレイトレーシング対応ベンチマークソフトなどは,Navi 21の1.8倍ほどのパフォーマンスを出すほどNavi 31のレイトレーシング性能は向上している」と自信を見せていた。
RDNA 3におけるそのほかの見どころ
RDNA 3におけるそのほかの細かい改善ポイントについて,簡単にまとめて説明しよう。
 |
Navi 31では,ROPユニット(※AMD用語ではRender Backend)は,Navi 21の1.5倍となる192基に増量され,高解像度のグラフィックス描画における実行効率が上がったと,AMDはアピールしていた。
マニアックなところでは,「Multi Draw Indirect Accelerator」(MDIA)という新機能の搭載がある。Draw Indirectは,あらかじめGPUに伝送しておいた3Dモデルなどを,パラメータを変えて反復描画する「インスタンス描画」をGPU主導で発動できる仕組みだ。そしてMDIは,これを複数回行う仕組みになる。RDNA 3では,MDIをハードウェアで処理する仕組みを搭載したことで,RDNA 2時の2.3倍も高速化するという。
新ジオメトリパイプラインのMesh Shaderでは,3Dモデルを複数のドメインに分割して取り扱う「Meshlet」単位で描画するが,そこまで高速化されるのであれば,Meshlet描画(関連リンク)をMDIAで行う用途にも使えそうである。
 |
ビデオプロセッサのデュアル化とは,H.264とH.265のビデオストリームをエンコード/デコードを同時に行えるビデオプロセッサと,AV1コーデックのエンコード/デコードが行えるビデオプロセッサの2種類を搭載することを意味する(表2)。
| Engine 1 | Engine 2 | |
|---|---|---|
| H.264 AVC | Encode | Encode |
| Decode | Decode | |
| H.265 HEVC | Encode | Encode |
| Decode | Decode | |
| AV1 | Encode | |
| Decode | Decode | |
Navi 31の新ビデオプロセッサには,NVIDIAのビデオプロセッサにもない,とてもユニークな機能が搭載された。それは,ゲーム実況配信などに特化した特別なフィルタ機能群で,低ビットレートでゲーム映像を配信しても,視聴者は相対的に美しい映像で楽しめるという機能だ。
具体的には,ゲーム映像をエンコードして配信するときに,GPUが描画した生フレームをそのままビデオプロセッサに入れてエンコードはせずに,特別に用意した映像フィルタを通して人為的に強調することで,低ビットレートに圧縮が行われても情報量の欠落を低減させることを狙うものになる。
たとえば,低ビットレートでのエンコード時に真っ先に犠牲となりやすいのが,ゲーム画面に配置されるユーザーインタフェース部分や,文字情報からなるメッセージ類だ。これらを低ビットレート圧縮時にも,元映像に近い品質を保てるように,生フレームを強調加工してしまうわけである。オンライン対戦ゲームの実況配信では,あまり映像のビットレートを上げられないことが多いが,そうした実況者にはおあつらえ向きの機能というわけである。
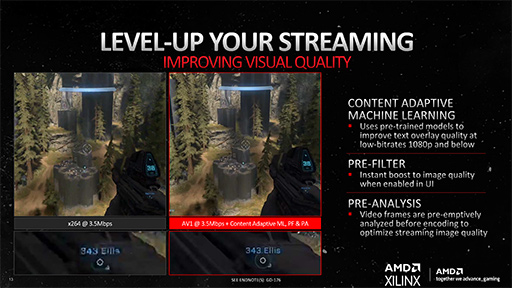 |
なお,この機能は,AMDのビデオプロセッサ向け開発フレームワーク「AMD
 |
映像出力インタフェースは,「HDMI 2.1a」に対応した。
HDMI 2.1aの「a」とは,2022年に策定されたゲーム向けのHDMI 2.1オプション規格(関連記事)に対応することを示しており,ディスプレイ側と協調して自動トーンマップ処理を行ったり,信号増幅機能を備えた長尺なアクティブHDMIケーブルに自動給電を行ったりできる機能拡張に対応していることを表す。
ちなみに,2022年時点でHDMI 2.1a対応製品は市場にはほとんど存在しないが,GPU側としていち早く対応したということのようだ。
DisplayPortについては第一報でも触れたが,Navi 31は,業界初の「DisplayPort 2.1」対応を果たした。
DisplayPort 2.1の規格は,最高速で1レーンあたり20Gbps(Ultra-High Bit Rate,UHBR20モード)を備えており,4レーン接続時なら最大80Gbpsの伝送帯域幅を提供できることになっている。ただ,Navi 31がサポートするのは13.5Gbpsのモードまでなので,4レーン接続時は最大54Gbpsまでとなる。
AMDは,8K/165Hz出力や4K/480Hz出力を可能とすることをアピールしており,これに対応したディスプレイは,2023年以降に発表される見込みとのことだ。
 |
発表はしながら,ほとんど「お口にチャック状態」で,その詳細を教えてくれなかった機能もある。それは,AMDが強く推進するポストエフェクトライブラリ「FidelityFX」シリーズの超解像技術「FidelityFX Super Resolution 3」(以下,FSR3)だ。
概要としては,GeForce RTX 40シリーズがDLSS3で実装した「補間フレーム機能」(Frame Generation)と同等の機能になるそうで,「AMD Fluid Motion Frames Technology」という名前と,そのα版を適用したと思われるUnreal Engine 5上のデモ映像が公開された。
 |
AMDは,FSR3の実装に関する詳細を明らかにしておらず,Navi 3x世代専用なのか,それとも既存のRadeonシリーズでも利用できるのかは不明だ。Navi 31で新搭載したAI Acceleratorを活用するのかどうかも明言されず。AMDは,映像再生向けに「AMD Fluid Motion Video」と呼ばれる機能を,以前からRadeonユーザーに広く提供しているのだが,これのゲーム映像版であれば,過去のRadeonにも対応できそうだが,どうなるだろうか。
GeForce RTX 40シリーズの解説記事でも触れたが,動的な遮蔽物が強く絡むゲーム映像での補間フレーム生成は,モーションベクター(ベロシティ情報)だけで生成すると,かなりのエラーを含んでしまう。NVIDIAは,この問題を打開するために「Optical Flow」の概念を組み合わせる解決策を導入したわけだが,AMDがどう取り組むのかに注目したい。
Microsoftのストレージデバイス向けAPI「DirectStorage 1.1」への対応についても,触れておきたい。
DirectStorageとは,SSDからの読み出し処理をDMA(Direct Memory Access)に任せて,CPUによる処理を最低限とするファイル入出力システムだ。ただ,実装当初のDirectStorageでは,読み出したデータが圧縮されている場合,その展開処理は,基本的にCPUが担う実装となっていた。
これが,2022年11月にリリースされたDirectStorage1.1で,GPUでの圧縮データ展開が可能となった(関連記事)。
AMDもニュースリリースを出して,SM6.0以降の同社製GPUでDirectStorage 1.1のGPUによるデータ展開処理機能が利用できることを明らかにした。DirectX 12対応世代の幅広いGPUで,DirectStorage 1.1を利用できそうだ。
 |
価格性能比の高さで人気を呼びそうなRX 7900シリーズ
近年のAMDは,Radeonシリーズにおいて最高性能だけを追求することはせず,価格対性能比や消費電力あたりの性能を重視したGPUを提供してきた。一方のNVIDIAは,絶対的な高性能を追求する立場をとり続けてきており,GeForce RTX 40シリーズは,まさに性能はモンスター級であった。
GeForce RTX 40シリーズは,圧倒的な高性能を追求するゲーマーからは絶賛される一方で,モンスター級の価格と消費電力の高さから,及び腰になっている人も少なくないように思える。
Navi 31の場合,上位モデルのRadeon RX 7900 XTXは,理論性能値が61 TFLOPSで国内実勢価格が約19万円前後,Radeon RX 7900 XTは,52 TFLOPSで16万7000円前後となっている。理論性能値ベースでは,GeForce RTX 4090(82 TFLOPS)とGeForce RTX 4080(49 TFLOPS)の間に入り込み,価格では競合製品を下回っている。まだ発売されたばかりだが,ゲーマーの間でも,Navi 31採用GPUは,相応に高い評価を得ているようである。この高評価が持続するのかは興味深いところだ。
筆者としては,これらに続いて両社が投入するであろう中堅クラスのGPUにも興味が湧く。それらはいずれ,ノートPCへも採用されるはずで,IntelのArcシリーズとの勝負も含めて楽しみである。
関連記事
[レビュー]AMDの新世代GPU「Radeon RX 7900 XTX&XT」を試す。コストパフォーマンスはGeForce RTX 4090/4080をしのぐ
AMDの新世代GPUアーキテクチャ「RDNA 3」を採用した新型GPU「Radeon
AMDのRadeon RX製品情報ページ
- 関連タイトル:Radeon RX 7000
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー