















ニュース
西川善司の3DGE:Hopper世代のNVIDIA製GPU「GH100」のアーキテクチャを深掘りしてみる
 |
H100については,事前情報をもとに第一報を掲載済みだが,基調講演後に,
H100の詳細仕様が判明
まず,H100がTSMCの4nmプロセスで製造されることと,トランジスタ数が約800億個だということは,基調講演で明らかになっていた。公開された技術資料では,そのあたりもさらに詳しく説明されている。
 |
まず,H100のダイサイズは,814mm2とのことだ。先代であるGPUの「A100」は,TSMC 7nmプロセスで,ダイサイズが826mm2,トランジスタ数は約542億個であった。先々代にあたる「V100」は,TSMC 12nmプロセスでトランジスタ数は約211億個,ダイサイズ815mm2だ。
つまり,近年のNVIDIAが開発するGPUコンピューティング向け(≒GPGPU用途)GPUは,ダイサイズが800mm2程度になるように想定した論理設計や物理設計を行っているのだろう。
GPUの命名ルールは,これまでと同様で,今回,H100として発表されたGPUダイの正式名称は,「GH100」となる。H100と呼ぶ場合,狭義には「GH100採用製品」を意味するようだ。しかし,NVIDIAが作成した資料でも,H100とGH100の使い分けは,けっこう適当な感じが見受けられる。
さて,GH100ダイのフルスペック版は,第一報で推測したとおり,ミニGPUクラスタの「Graphics Processor Cluster」(以下,GPC)が8基の構成だった。
CUDAベースになってからのNVIDIA製GPUは,基本的な実行演算器に相当する32bit浮動小数点(FP32)スカラ演算器の「CUDA Core」を,複数まとめた一塊を「Streaming Multiprocessor」(以下,SM)と呼んでいる。フルスペック版GH100と,GA100の仕様を比較してみよう。
| GH100 | GA100 | |
|---|---|---|
| GPC数 | 8 | 8 |
| GPC 1基あたりのSM数 | 18 | 16 |
| SM 1基あたりのCUDA Core数 | 128 | 64 |
| CUDA Core総数 | 18432 | 8192 |
GH100のフルスペック版におけるCUDA Core総数は,以下のように計算できるわけだ。
- 8 GPC×18 SM×128 CUDA Core=18432
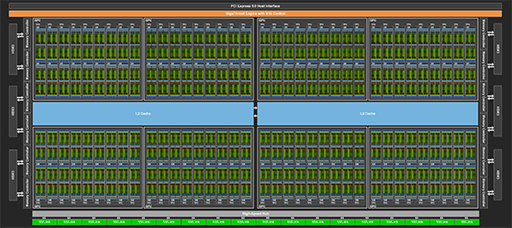
GH100のフルスペック版に相当するブロックダイアグラムと,比較用としてGA100のブロックダイアグラムを示す。
 |
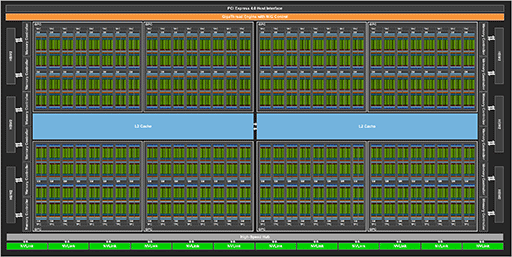 |
パッと見ただけでは,どちらもまったく同じく見えるかもしれない。それこそ間違い探しクイズレベルの類似度だ。だが,細かく見ていくと大きな違いに気付くだろう。
GPC 8基構成は同じであるが,GA100ではGPC 1基あたりのSM数が16基だったのに対して,GH100では18基となっているのだ。つまりGH100の論理設計では,GPC 1基あたりのSM数を2つ増やしたわけだ。
違いはそれだけではない。SM内に組み込んだCUDA Core数を,GA100の2倍となる128基に増量したのだ。NVIDIAが1基のSMに搭載したCUDA Core数の変遷を見てみよう。
| 世代 | GPU名 | CUDA core総数 | SM 1基あたりのCUDA core数 |
|---|---|---|---|
| Tesla | GT200 | 240 | 8 |
| Fermi | GF100 | 512 | 32 |
| Kepler | GK104 | 1536 | 192 |
| Maxwell | GM200 | 3072 | 128 |
| Pascal | GP102 | 3840 | 128 |
| Volta | GV100 | 5120 | 64 |
| Turing | TU102 | 4608 | 64 |
| Ampere | GA100 | 8192 | 64 |
| GA102 | 10752 | 128 | |
| Hopper | GH100 | 18432 | 128 |
テクスチャユニット群を共有するSMグループである「Texture Processing Cluster」(以下,TPC)についても見てみよう。なお,GPGPUモード時には,同じTPCでも「Thread Processing Cluster」という呼び方に変わるが,同じものという理解でいい。
TPC 1基あたりのSM数は,各世代のNVIDIA製GPUで以下のように変化してきた。Pascal世代以降はTPC 1基あたりSM 2基となっており,GH100でもTPCとSM数のバランスに変化はないようだ。
- Tesla GT200:SM 3基
- Fermi GF100:SM 3基
- Kepler GK104:SM 1基
- Maxwell GM200:SM 1基
- Pascal GP102:SM 2基
- Volta GV100:SM 2基
- Turing TU102:SM 2基
- Ampere GA100:SM 2基
- Ampere GA102:SM 2基
- Hopper GH100:SM 2基
なお,公開されたブロックダイアグラムで判明したことに,GH100におけるNVlinkのリンク数がある。
第一報時点では,NVLinkのインタフェース帯域幅は900GB/sと発表されていたが,そのリンク数については非公開だった。ブロックダイアグラムの最下段にある緑のマスは,NVLinkのスイッチインタフェースを表しており,これを数えてみると,GH100は18リンクであることが分かる。
Ampere世代から,NVLinkは,信号線数削減のために伝送レーンを半減する代わりに,1レーンあたりの帯域幅を倍増する改良を行った。NVIDIAによると,Hopper世代でも,この仕様を受け継いでいるとのことだ。
ちなみに,AmpereやHopper世代のNVLinkは,1レーンあたりの帯域幅が「50Gbps×4レーン×2双方向=50GB/s」であるため,12リンク仕様のGA100は「50GB/s×12リンク=600GB/s」だった。18リンク仕様のGH100では「50GB/s×18リンク=900GB/s」となるので,公称値の900GB/sと合致するわけである。
FP32演算器とFP64演算器を倍増したGH100のSM
公開された技術資料によると,GH100におけるSMの構造は,次の図のようになっているそうだ。比較用にGA100のSMも示しておこう。図中の「FP32」が,CUDA Coreに相当する。
 GH100におけるSMのブロックダイアグラム |
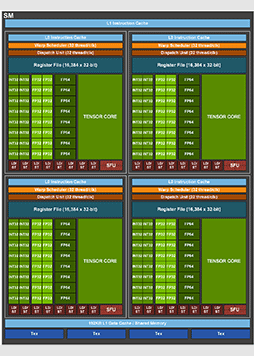 GA100におけるSMのブロックダイアグラム |
こうしてGH100とGA100のSM構造を見比べると,大きく変わったのは,FP32とFP64が,SM 1基あたり64基だったGA100に対して,GH100では128基へと倍増していること,L1 データキャッシュの容量が,GA100の192KBに対して,1.33倍の256KBとなったあたりだろうか。
近年のNVIDIA製GPUにおける,SM 1基あたりのCUDA Core数とテクスチャユニット数の関係を表3にまとめてみよう。
| GPU名 | CUDA core数 | テクスチャ |
CUDA core数: テクスチャユニット数 |
|---|---|---|---|
| Tesla GT200 | 8 | 8 | 1:1 |
| Fermi GF100 | 32 | 4 | 8:1 |
| Kepler GK104 | 192 | 16 | 12:1 |
| Maxwell GM200 | 128 | 8 | 16:1 |
| Pascal GP102 | 128 | 8 | 16:1 |
| Volta GV100 | 64 | 4 | 16:1 |
| Turing TU102 | 64 | 4 | 16:1 |
| Ampere GA100 | 64 | 4 | 16:1 |
| Ampere GA102 | 128 | 4 | 32:1 |
| Hopper GH100 | 128 | 4 | 32:1 |
 |
GA102では,FP32演算器の半分が32bit整数演算器と排他の兼用となっていた。この制限がGH100ではどうなっているのかと,NVIDIAのJonah M.Alben氏(SVP, GPU Engineering, NVIDIA)に質問したところ,「GA102と同じ制限がある」という回答が得られた。つまり,GH100のCUDA Coreの仕様は,GA102から継承していると見ていいだろう。
SMのブロックダイアグラムと,CUDA Core数やテクスチャユニット数のバランス表を見て筆者が感じたのは,演算器がだいぶ拡充されたわりに,ロード/ストアユニット(LD/ST)や超越関数ユニット(SFU),テクスチャユニット(Tex)は4基のままなのが,ちょっと不思議ということだ。このあたりは,グラフィックスレンダリング用途版のHopper世代GPUが出てきたときには変わっている予感もする。
GH100の動作クロックは1.8GHz前後
理論性能値は66 TFLOPSオーバーか?
第一報でも触れたが,GH100を搭載する初期の製品は,フルスペック仕様ではなく,製造歩留まり対策のために,ある程度のSMを削減したものになる。
SMをいくつ削減するのかは,当然ながら製品によって多少異なるが,大きく2パターンに分かれるようだ。
1つは,GH100をGPU-GPU間インターコネクト(インタフェース)「NVSwitch」に直結した「SXM5」タイプの製品「NVIDIA H100 GPU with SXM5 board form-factor」(以下,H100 SXM)である。もう1つは,PCI Express(以下,PCIe)5.0スロットに装着するタイプの製品「NVIDIA H100 GPU with a PCIe Gen 5 board form-factor」(以下,H100 CNX)だ。最も高性能な仕様でGH100を利用できるのは,H100 SXMである。
 |
 |
H100 SXMは,132 SM×128 CUDA Core仕様のCUDA Core総数16896基。PCIe 5.0のH100 CNXは,114 SM×128 CUDA Core仕様のCUDA Core総数14592基とのこと。
ちなみにH100 SXMは,GPCのうち2基がフルスペック(18 SM)で,残りの6基は16 SM仕様といった構成になる(※ほかの構成もあり得る)。
- 2 GPC×18 SM+6 GPC×16 SM=132 SM
一方で,H100 CNXは,けっこうややこしく,GPC 7基のモデルとGPC 8基のモデルがあるそうだ。たとえば,GPC 7基の場合はこうなる。
- 5 GPC×18 SM+2 GPC×12 SM=114 SM
これがGPC 8基仕様の場合は,このような組み合わせがありうる。
- 5 GPC×18 SM+3 GPC×8 SM=114 SM
NVIDIAは明らかにした,H100 SXMとH100 CNXの理論性能値は次のとおり。どの項目もH100 SXMのほうが高性能である。
| H100 SXM | H100 CNX | |
|---|---|---|
| Peak FP64 | 30 TFLOPS | 24 TFLOPS |
| Peak FP64 Tensor Core | 60 TFLOPS | 48 TFLOPS |
| Peak FP32 | 60 TFLOPS | 48 TFLOPS |
| Peak FP16 | 120 TFLOPS | 96 TFLOPS |
| Peak BF16 | 120 TFLOPS | 96 TFLOPS |
| Peak TF32 Tensor Core | 500 TFLOPS |
400 TFLOPS |
| Peak FP16 Tensor Core | 1000 TFLOPS |
800 TFLOPS |
| Peak BF16 Tensor Core | 1000 TFLOPS |
800 TFLOPS |
| Peak FP8 Tensor Core | 2000 TFLOPS |
1600 TFLOPS |
| Peak INT8 Tensor Core | 2000 TOPS |
1600 TOPS |
GH100の技術資料は,かなり詳細な情報まで載っているのだが,残念ながら動作クロックは,「実際の製品リリース時までは非公開」とのことであった。しかし,NVIDIAが今回明らかにした「GH100のFP32理論性能値は60 TFLOPS」から,GH100の動作クロックを逆算できる。
まず,公称値60 TFLOPSなのは,132 SMでCUDA Core数16896基のH100 SXMであるから,
- 60 TFLOPS=16896 CUDA×2 FLOPS×動作クロック(Hz)
の式が成り立つので,動作クロックは「およそ1.8GHz」という数値を導き出せる。Samsung Electronicsの8nmプロセスで製造したGA102が1.7GHz前後くらいだったので,計算で出た動作クロックには,それなりのリアリティはある。
ちなみにだが,GH100のフルスペックである144 SM,18432 CUDA Coreを1.8GHzで駆動した場合の理論性能値を求めてみると,約66 TFLOPSとなった。
FP8に対応したGH100のTensor Core
第一報では,GH100のTensor CoreがFP8へ対応したことと,「なぜ学術界は,FP8対応を望んだのか」といった背景を解説した。第一報でも,FP8はどのようなフォーマットなのかについて考察したが,技術資料には,その詳細が書かれていた。
第一報では,GH100が対応したFP8形式が,仮数重視の「符号1bit,指数4bit,仮数3bit」(E4M3)型なのか,指数重視の「符号1bit,指数5bit,仮数2bit」(E5M2)型なのかは明らかになっていないとしたが,NVIDIAによると,GH100は,その両方に対応するそうだ。
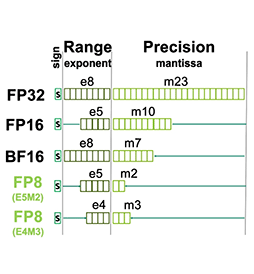 GH100のFP8は,E4M3型とE5M2型の両方に対応する |
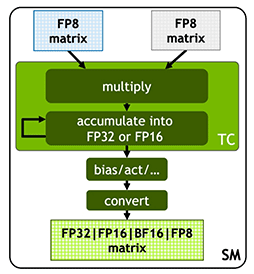 GH100のTensor Coreは,FP8行列同士の畳み込み演算に対応する |
Alben氏に,2タイプのFP8形式を使い分ける方法について質問したところ,「GH100のTensor Coreが,自動で適宜使い分けるので,ユーザーが意識すべきことは何もない」とのことだった。
実は,自動でE4M3型とE5M2型を使い分ける機構こそ,GH100が搭載する「Transformer Engine」の正体だ。つまり,「GH100がFP8対応した」というのは,「GH100にTransformer Engineを搭載した」は,実質,同じ意味だったのである。
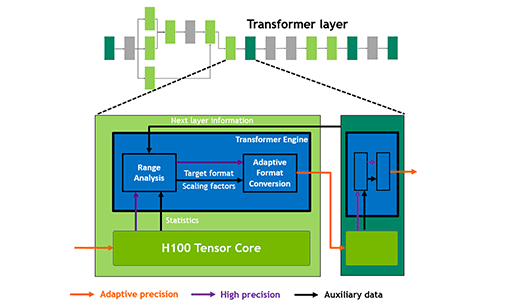 |
上の図を見ると,Transformer Engineの仕組みが分かりやすい。Tensor Coreが演算結果として出力する数値(FP16やFP32など)を,「Range Analysis」で解析してE4M3型,もしくはE5M2型のFP8に変換するわけだ。
つまり,第一報で触れたIBMのXiao Sun氏らによる論文(関連リンク)が提唱した「ハイブリッドFP8システム」を,そのままハードウェアで実装したような構造だったわけである。
Thread Block Clustersという新概念の導入
基調講演では,とくに強く訴求してはいなかったが,GH100には,「Thread Block Cluster」(以下,TBC)と称する機能も搭載されていることが分かった。
GPUを汎用演算に流用する「GPGPU」(General Purpose GPU)という概念は,プログラマブルシェーダ技術が実用化されて間もない2000年代初頭に誕生した。しかし,学術界においてGPUコンピューティング(=GPGPU)として認知と採用が進んだのは,2006年にNVIDIAが,Tesla世代の「GeForce 8800 GTX」と合わせて発表した「CUDA」が浸透してからだ。
CUDAは「NVIDIAのGPUをGPGPUで使うためのプラットフォーム」として,NVIDIAの中核技術として発展していった。登場から16年が経過した現在では,ありとあらゆるコンピューティングパラダイムをCUDAで実装する試みが,世界各地で行われている。「その動向を見ていく中で,TBCが必要と判断した」と,前出のAlben氏は述べていた。
近年のGPUコンピューティングでは,計算対象の問題が大規模化していることに加えて,取り扱うアルゴリズムが複雑化していることを,NVIDIAは重く見ているようだ。
具体的には,大規模な計算対象における計算途中の結果を,単一のSM上で扱う単一スレッドブロックのサイズを超えて,複数のスレッドブロック間で相互にやりとりする処理系が非常に多くなっていることの効果的な対策となるのが,今回のTBCである。
従来のCUDAにおけるプログラミングモデルでも,こうしたデータを扱えないことはなかったが,スレッドブロック間におけるデータのやりとりには,明確な同期プロセスが必要だった。NVIDIAがGH100に盛り込んだTBCは,単一のSM上で扱っている単一スレッドブロックのサイズを超えた大きい粒度で,スレッドブロック同士のデータのやりとりを可能にする仕組みとなる。
具体的に説明しよう。
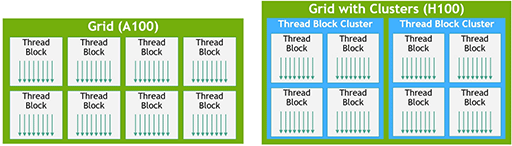 |
まず,上の図における水色の枠が,TBCを示している。Hopper世代以降のCUDAプログラミングモデルでは,CUDA cooperative_groups APIを用いることで,カーネルの起動時に各スレッドブロックをTBCとして定義できるようになった。
TBCを活用することのメリットは,TBCに定義したスレッドグループ内においては,ロード/ストア命令やアトミック命令を駆使して,他のSMにある共有メモリへ直接アクセスできるようになることだ。TBCによって,共有メモリの仮想アドレス空間は,TBC内のスレッドブロック間で横断的に利用できるようになる。この仕組みを,新CUDAプログラミングモデルでは,「Distributed Shared Memory」(DSMEM,分散共有メモリ)と呼ぶ。
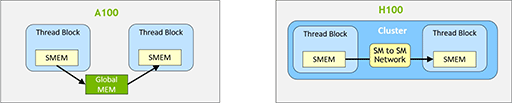 |
上図左のように,Ampere世代以前のCUDAプログラミングモデルでも,スレッドブロック間でのデータのやりとりは行えたが,その場合,グラフィックスメモリ(≒図中のGlobal MEM)を経由しなければならなかった。それに対して,上図右のHopper世代では,これまでの手間が不要となり,各スレッドブロック同士が共有メモリ※1を介して直接的にデータのやりとりできるようになる。これにより,GH100におけるスレッドブロック間のデータのやりとりは,A100と比較して7倍近くも高速になるという。
※1 L1キャッシュから,任意サイズを割り当てることができるSRAMベースの高速共有メモリ。図中のSMEM
なお,TBCでもまとめられないほどの巨大な計算対象で発生するデータのやりとりは,従来通りのやり方を使わざるをえない。細かい改良点ではあるが,比較的小規模な計算対象を取り扱うときに得られる恩恵は大きいようだ。
Async Copyを加速させるTensor Core版DMA「TMA」
今どきのGPUは,演算処理とデータ転送(≒メモリアクセス)をなるべく分離して処理する設計思想で開発されている。メモリアクセスは,演算時間の数十〜数百倍は遅いからだ。メモリアクセスが終わるのを待っている間,演算ユニットを止めていたらもったいないので,待ち時間には異なるスレッドの演算を行うようにして,メモリアクセスの遅延を隠蔽する。たとえるなら,部下に振った仕事(メモリアクセス)が終わるのを待っている間に,上司は別の仕事を進める(スレッド切り替え)といったところか。
GA100のリリースとほぼ同時に提供開始した「CUDA 11」では,「Asynchronous Copy」(非同期コピー,以下 Async Copy)と呼ばれる新しいメモリアクセスモデルを導入したうえで,これに合わせてGPUのメモリアーキテクチャを大幅に変えた(関連記事)。
Async Copyとは,CUDA 11で導入した新しいプログラミングモデルを実現するための技術で,あるデータセットが処理中であっても,その処理終了を待つことなくGPU側がGPGPU処理系に対して,次に流し込むべきデータセットの準備を行える機能のことだ。
GA100において,非同期のデータ転送処理は,SM側に実装されているロード/ストアユニットが担当していた。名前は特別そうだが,実際はソフトウェア処理によるメモリコピーに過ぎない。一方,GH100では,Tensor Core内に非同期データ転送処理専用の機構「Tensor Memory Accelerator」(以下,TMA)を搭載した。つまり,Async CopyをTMAが担当するようにしたわけである。
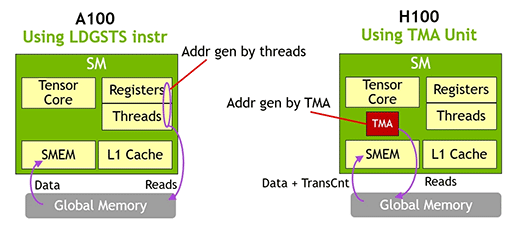 |
「ティーエムエー」という名前からピンと来た人もいそうだが,これはいわゆる「Direct Memory Access」(ディーエムエー,以下 DMA)の役割そのものだ。DMAとは,プロセッサ(CPUやGPUなど)側のメモリアクセス機能とは別に,非同期かつ独立してメモリアクセスやデータ転送を直接行える専用ユニットのこと。とくに新しいものではなく,コンピュータの世界では昔からありふれた機能である。
ちなみに,Alben氏も「TMAは,Tensor Coreに組み込んだDMAのようなものだ」と説明していた。
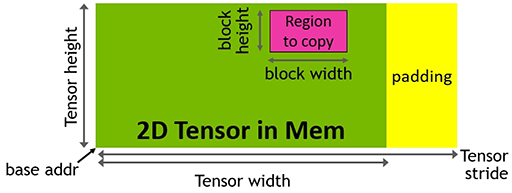
ただ,連続したアドレスに並んだデータの伝送,いわば1次元的なデータ転送を行うタイプのDMAとは異なり,TMAは,Tensor Coreが取り扱う多次元配列のデータ転送を扱えるのだ。Alben氏は,「(TMAは)一次元から五次元の配列データ転送に対応する」と説明していた。
 |
Asynchronous Transaction Barrierで拡張される非同期バリア機構
CPUとは桁違いの,何万という大量のスレッド実行を扱うGPUにおいて,空いているコア(≒演算器)を有効活用するには,ある演算ユニットが「何か別の処理が終わるまで待機させられる」同期待ちを,可能な限りなくす必要がある。ゆえに,非同期処理の新たな選択肢(オプション)を用意することは,GPUというプロセッサの進化には欠かせない。
そんなわけでNVIDIAは,Hopper世代以降に対応するCUDAプログラミングモデルに,「Asynchronous Transaction Barrier」(非同期トランザクションバリア,以下 ATB)という非同期処理の新機能を導入した。
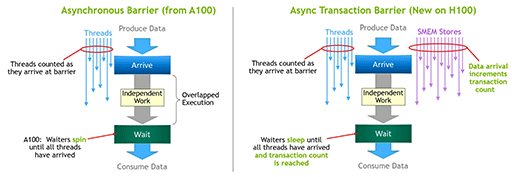 |
図の左は,GA100で実装された「Asynchronous Barrier」の概念を示した図で,たくさんのスレッドが同時に並列実行されていると考えてほしい。処理対象のデータにおける特徴や,条件分岐時における実行経路の違い,そのほかもろもろの理由で,各スレッドの実行時間は変わってくる。各スレッド同士に依存関係がある場合,全スレッドの処理が終わるまでは次の処理系に進められないので,左図下にある「Wait」のところで同期を待つことになる。
同期を待つ間,演算ユニットを待たせておくのはもったいないので,依存関係のない別スレッド実行に,待機中の演算ユニットを割り当てることができる機能が,Asynchronous Barrierだった。
一方,図の右側に描かれたATBは,同期を待つ条件に「データ転送の完了」という条件を含められるようにしたものだ。
すべてのスレッド実行が終わっていたとしても,各スレッドがAsync Copyなどを使って,次の処理に必要なデータ転送を予約していた場合,データ転送が完了しないと次の処理系には進めない。各スレッドのデータ転送が完了するまで,待機を継続させるしかないわけだ。こうした条件を定義できるのがATBである。
説明すると,なんとも地味な機能だが,怠ける演算ユニットをひとつも出さないようにするためには,必要な機能ということなのだろう。
GH100のメモリシステムとキャッシュシステム
GH100に組み合わされたメモリは「HBM3」で,メモリ帯域幅は3TB/sに達することは,第一報でも触れた。しかし,実際にHBM3を採用するのは,先述したH100 SXMだけで,PCIe 5.0接続のH100 CNXは,GA100でも使われた「HBM2」の改良版である「HBM2e」を採用しているとのことだ。メモリ帯域幅は2TB/sになるという。
GH100におけるキャッシュシステムの階層構造は,GA100から大きな変更はない。ただ,キャッシュメモリ容量は,演算器群の増大に合わせて増加している。先述したとおり,L1データキャッシュがGA100比で1.33倍の256KBとなった。なお,256KBのL1データキャッシュのうち,最大228KBまでをSM間共有メモリとして割り当てることも可能だ。
GH100ではL2キャッシュ容量も増えた。GA100の40MBに対して,GH100では50MBとなった。
なお,GH100のL2キャッシュシステムは,GA100で採用されたものと同じく,最大4倍の圧縮率を誇るハードウェアレベルの可逆圧縮システムを備えている。L2キャッシュメモリから読み出したデータは,圧縮されたままの状態でGPU内バスを行き来して,演算器へ入力される段階で初めて展開される。
レイトレーシングには未対応だったGH100
Alben氏は,GH100に関する筆者の細かい質問についても答えてくれたので,最後にまとめて紹介しよう。
まずGH100では,GA100で導入されたGPU仮想化技術「Multi-Instance GPU」(以下,MIG)を受け継いでおり,GPC単位で独立した仮想GPUとして扱える。GA100では,GPC 7基の製品しかなかったため,MIG機能による仮想GPUは7基どまりだった。GH100は,GPC 8基とGPC 7基の製品バリエーションがある。そうなると,GPC 8基のGH100では,MIGベースの仮想GPUを8基生成できるのだろうか。
これについてAlben氏は,「GH100搭載製品におけるMIGベースの仮想GPUは,GPC数とは関係なく最大7基とした。その理由はユーザーを混乱させたくないためだ」とのことだった。
 |
それと,MIGについて1つ,第一報に訂正すべき点があることも分かった。
筆者は,「GH100では,MIG機能で仮想化されたGPUがグラフィックスレンダリングに対応する」と述べたが,Alben氏によると,GH100でも,MIGモードではGPGPU専用になってしまうとのことだ。
ただ,「MIG機能ではない状態でGH100を仮想化した場合には,グラフィックスレンダリングに対応する」(Alben氏)そうだ。その場合でも,GH100全体でわずか2基分のTPCでしかグラフィックスレンダリングを行えないので,仮想GPUのユーザー数が多い場合には性能面での悪影響は避けられないとのことである。
そのほかに,GH100はハードウェアレイトレーシングユニット(RT Core)を搭載しないことも明言された。また,MIG機能で仮想化されたGPUにおいて使えるのはビデオデコーダのみで,エンコーダは利用できないとのこと。つまりGH100は,NVENCも搭載しておらず,NV“DEC”のみを搭載しているわけである。
| HEVCデコード | H.264デコード | VP9デコード | |
|---|---|---|---|
| GH100 | 340 | 170 | 260 |
| GA100 | 157 | 75 | 108 |
| Bit深度 | クロマフォーマット | |
|---|---|---|
| H.264 | 8bit | 4:2:0 |
| HEVC | 8/10/12bit | 4:2:0 |
| VP9 | 8/10/12bit | 4:2:0 |
結局はGH100も,「GPUコンピューティング目的で活用してください」ということなのだろう。
なお,Alben氏に対しては,GeForce版のHopperについての質問が当然投げかけられたものの,笑いながら「何も答えられない」と返すのみであったことを付け加えておく。
NVIDIAのHopperアーキテクチャ情報Webページ(英語)
- 関連タイトル:
 Hopper(開発コードネーム)
Hopper(開発コードネーム) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー