













œ¢∫Ð
¿æ¿Ó¡±ª §Œ3DGE°ßRTX 2080 SUPERƒ∂§®§Œ•þ•…•Î•Ø•È•πGPU°÷GeForce RTX 3060°◊§»•Œ°º•»PC∏˛§±GeForce RTX 30§Œ•ð•§•Û•»§œ§…§≥§À°©
 |
 |
¥ÿœ¢µ≠ªˆ


NVIDIA°§Ampere¿§¬Â§Œ•þ•…•Î•Ø•È•πGPU°÷GeForce RTX 3060°◊§‰°§•Œ°º•»PC∏˛§±°÷GeForce RTX 30°◊•∑•Í°º•∫§Ú»Ø…Ω
°°Àà ∆ª˛¥÷2021«Ø1∑Ó12∆¸°§NVIDIA§œ°§CES 2021§ÀπÁ§Ô§ª§∆≥´∫≈§∑§ø∆»º´•§•Ÿ•Û•»°÷GeForce
- •≠°º•Ô°º•…°ß
- HARDWARE:GeForce RTX 30
- HARDWARE
- GPU
- GeForce
- NVIDIA
- •À•Â°º•π
- ‘Ω∏…Ù:æÆ¿æկÿ
- CES 2021
GA106•≥•¢§Ú∫ŒÕ—§π§ÎGeForce RTX 3060§Œª≈ÕÕ§ÚÕΩ¬¨§π§Î
 |
°°§‚§¡§Ì§Û°§2019«Ø§À§œ•·°º•´°º¡€ƒÍ«‰≤¡349•…•Î° ≈ˆª˛°À§Œ°÷GeForce RTX 2060°◊§¨≈–æϧ∑§∆§§§Î°£§¿§¨°§§≥§»•Í•¢•Î•ø•§•ý•Ï•§•»•Ï°º•∑•Û•∞§À§ƒ§§§∆§œ°÷§ §Û§»§´¬–±˛§∑§Þ§∑§ø°◊§»§§§¶ƒ¯≈Ÿ§«°§ÀÐ≥ ≈™§À•≤°º•ý§«≥ËÕ—§π§Î§À§œ¿≠«Ω≈™§ÀæØ°π ™¬≠§Í§ §§§‚§Œ§¿§√§ø°£
°°∫£≤Û»Ø…Ω§»§ §√§øGeForce RTX 3060§ŒæÏπÁ°§GPU•≥•¢º´¬Œ§œ≥´»Ø•≥°º•…•Õ°º•ý°÷GA106°◊§»§§§¶§‚§Œ§«°§°÷GeForce RTX 3080°◊§Àª»§Ô§Ï§ø•œ•§•®•Û•…•‚•«•Î§«§¢§Î°÷GA102°◊§‰°§°÷GeForce RTX 3070°◊§™§Ë§”°÷GeForce RTX 3060 Ti°◊§ŒGPU•≥•¢§«§¢§Î°÷GA104°◊§»∆±ÕÕ§À°§Samsung Electronics§Œ8nm•◊•Ì•ª•π§«¿Ω¬§§µ§Ï§Î§‚§Œ§¿°£ÀÐπ∆ºπ…ƪ˛≈¿§«•»•È•Û•∏•π•øøÙ§œÃ¿§È§´§À§ §√§∆§§§ §§§¨°§§“§»§ƒæ§ŒGA104§¨174≤Ø∏ƒ§ §Œ§«°§§Ω§Ï§Ë§Í§œæا §§§»ÕΩ¡€§«§≠§Î°£GA102§»GA104§Œ•∑•ß°º•¿•≥•¢° CUDA Core°Àøٻʧ´§È¡€ƒÍ§π§Î§»°§GA106§œ110≤Ø∏ƒ§À∂·§§√Õ§À§ §Í§Ω§¶§¿°£
°°GeForce RTX 3060§À§ƒ§§§∆ÀÐπ∆ºπ…ƪ˛≈¿§«Ã¿§È§´§À§ §√§∆§§§ÎπýÃЧڵۧ≤§Î§»°§CUDA Core¡ÌøÙ§¨3584¥§«°§GPUƒÍ≥ ∆∞∫Ó•Ø•Ì•√•Ø§¨1.32GHz°§GPU∫«¬Á∆∞∫Ó•Ø•Ì•√•Ø§œ1.78GHz§»§ §√§∆§§§Î°£CUDA CoreÕ˝œ¿¿≠«Ω√Õ§œ13 TFLOPS§«°§•Ï•§•»•Ï°º•∑•Û•∞¿≠«Ω√Õ§œ25 RT-TFLOPS°§ø‰œ¿•¢•Ø•ª•È•Ï°º•ø°÷Tensor Core°◊§ŒÕ˝œ¿¿≠«Ω√Õ§œ101 TensorFLOPS§«§¢§Î§»§§§¶°£§Ω§Œ§€§´§À°§•·•‚•Í•§•Û•ø•’•ß°º•π§œ192bit§«°§GDDR6•·•‚•Í§Ú∫«¬Á12GB≈Î∫Чπ§Î§»§§§√§øæ Û§¨Ã¿§È§´§À§ §√§∆§§§Îƒ¯≈Ÿ§¿°£
 |
°°§Ω§Œ§ø§·°§∫£§Œ§»§≥§Ì§œ§≥§Ï§¿§±§Œæ Û§´§È°§§Ω§Ï∞ ≥∞§Œø‰¬¨§π§Î§∑§´§ §§°£§Þ§∫§œSMøÙ§¿§¨°§NVIDIA§ŒAmpere•¢°º•≠•∆•Ø•¡•„§œ°§Streaming Multiprocessor° ∞ ≤º°§SM°À1¥§¢§ø§Í°§128¥§ŒCUDA Core§Ú≈˝πÁ§π§ÎπΩ¿Æ§ §Œ§«°§GeForce RTX 3060§ŒCUDA Core¡ÌøÙ§¨3584¥§»§§§¶§≥§»§œ°§SMøÙ§œ28¥§»§§§¶§≥§»§«¥÷∞„§§§ §§°£
- 128 CUDA Core°þ28 SM°·3584 CUDA Core
°°¬≥§§§∆°§NVIDIA§ŒGPU∆‚§À§¢§Î•þ•ÀGPU•Ø•È•π•ø°÷Graphics Processor Cluster°◊° ∞ ≤º°§GPC°À§¨§§§Ø§ƒ§ §Œ§´§¿§¨°§§≥§Ï§œøÙª˙§´§È§Œø‰¬¨§¨∆Ò§∑§§°£¿Ë¬Â§ŒGeForce RTX 2060° TU106°À∑œ§ŒGPCøÙ§œ3§¿§√§ø§Œ§«°§∫£≤Û§‚∆±§∏§Ø§È§§§«§¢§Î≤ƒ«Ω¿≠§œπ‚§§°£§∑§´§∑°§≤æ§À3§¿§√§ø§»§∑§∆§‚°§SMøÙ§Œ28¥§œ3§«≥‰§Í¿⁄§Ï§ §§√Õ§¿°£
 |
°°§ø§¿°§¿Ë¬ÂTU106§¨§Ω§¶§¿§√§ø§Ë§¶§À°§GPC 1¥§¢§ø§Í§ŒSMøÙ§Ú10§¿§»≤æƒÍ§π§Î§»°§
- 128 CUDA Core°þ10 SM°þ3 GPC°·3840 CUDA Core
§»§§§√§ø∂ÒπÁ§À°§•’•Î•π•⁄•√•Ø»«GA106§Œª—§Ú¡€¡¸§«§≠§Î§Ë§¶§À§ §Î°£§ƒ§Þ§ÍGeForce RTX 3060§œ°§GPC 1¥§´§ÈSM§Ú2¥ ¨§¿§±Ãµ∏˙≤Ω§∑§øGPU§»§§§¶§Ô§±§¿°£•·•‚•Í•§•Û•ø•’•ß°º•π§¨192bit° °·64bit°þ3°À§»§§§¶∏¯≥´æ Û§‰°§¿Ë¬ÂTU106§Œø ≤Ω∑œ§»§§§¶¿∞πÁ¿≠§‚§¢§Î§∑°§∏ÂΩ“§π§Î•Œ°º•»PC»«GeForce RTX 3060§¨°§§Þ§µ§ÀCUDA CoreøÙ3840§«§¢§Í°§•Í•¢•Í•∆•£§Œ§¢§ÎÕΩ¬¨§»∏¿§®§Ω§¶§¿§¨°§¿‰¬–¿µ§∑§§§»§§§¶≥Œæ⁄§œ§ §§°£
°°≤æ§À°§GPC§¨4¥πΩ¿Æ§¿§»§π§Ï§–°§
- 128 CUDA Core°þ8 SM°þ4 GPC°·4096 CUDA Core
§»§§§¶∑◊ªª§¨¿Æ§ÍŒ©§ƒ°£§≥§ŒæÏπÁ°§GeForce RTX 3060§œ≥∆GPC§«SM§Ú1¥§∫§ƒÃµ∏˙≤Ω§∑§øGPU§»§«§¢§Î§»ø‰¬¨§«§≠§Î§Ô§±§¿°£§ø§¿°§§≥§ŒæÏπÁ°§•’•Î•π•⁄•√•Ø»«GA106§Œ•·•‚•Í•§•Û•ø•’•ß°º•π§œ256bit° °·64bit°þ4°À§«§ §§§»…‘º´¡≥§ µ§§‚§π§Î°£§»§œ§§§®°§¿Ë¬ÂTU106§œ°§GPC 3¥πΩ¿Æ§«•·•‚•Í•§•Û•ø•’•ß°º•π§¨256bit§¿§√§ø§Œ§«°§GPCøÙ§»•·•‚•Í•§•Û•ø•’•ß°º•π§Œª≈ÕÕ§œ°§∫«∂·§«§œ¡Í¥ÿ¥ÿ∑∏§À∑Á§±§∆§§§ø§Í§‚§π§Î§Œ§¿§¨°£
°°§§§∫§Ï§À§ª§Ë°§GeForce RTX 3060§œGA106§Œ•’•Î•π•⁄•√•Ø»«§«§œ§ §§≤ƒ«Ω¿≠§¨π‚§§°£§Ω§¶§ §Î§»°§§§§∫§Ï§œ°÷GeForce RTX 3060 SUPER°◊§Œ§Ë§¶§ æÂ∞Õ‚•«•Î§¨Ω–§Î≤ƒ«Ω¿≠§œ§¢§Í§Ω§¶§¿°£
°°§µ§∆°§GeForce RTX 3060§ŒÕ˝œ¿¿≠«Ω√Õ§«§¢§Î13 TFLOPS§œ°§1CUDA Core§¨1•Ø•Ì•√•Ø§«¿—œ¬ªª° Fused Multiply-Add°§FMA°§2 FLOPS°À§Ú±Èªª§«§≠§Î§Œ§«°§∞ ≤º§Œ∑◊ªª§«∆≥§≠Ω–§ª§Î°£
- 3584 CUDA Core°þ1.78GHz°þ2 FLOPS¢‚12.76 TFLOPS
°°∏¯æŒ√Õ§œ°§§‰§‰∑´§Íæ§≤§ø√Õ§»§§§¶§Ô§±§¿°£§ø§¿°§§≥§Ï§«§‚°§Turing¿§¬Â§Œ°÷GeForce RTX 2080 SUPER°◊° 11.15 TFLOPS°À§Úƒ∂§®§∆°§°÷GeForce RTX 2080 Ti°◊° 13.45 TFLOPS°À§À«˜§Î§€§…§¿§´§È§π§¥§§§≥§»§¿°£
°°•Í•¢•Î•ø•§•ý•Ï•§•»•Ï°º•∑•Û•∞¿≠«Ω§Œ°÷25 RT-TFLOPS°◊§À§ƒ§§§∆§‚°§æا∑§¿§±¿‚ÿ§∑§∆§™§≥§¶°£
°°RT-TFLOPS§»§œ°§NVIDIA∆»º´§Œ•Ï•§•»•Ï°º•∑•Û•∞¿≠«Ωªÿ…∏√Õ§«°§∞ ¡∞§œ°÷RTX-OPS°◊§»∏∆§–§Ï§∆§§§ø§‚§Œ§¿°£§≥§Ï§œ°÷GeForce GTX 1080 Ti° Õ˝œ¿¿≠«Ω√Õ11.3 TFLOPS°À§Œ•◊•Ì•∞•È•Þ•÷•Î•∑•ß°º•¿§«RT Core§ŒΩËÕ˝§Ú∫∆∏Ω§∑§øæÏπÁ°§1.1G Rays/s§Œ•Ï•§≈ͺտ≠«Ω§¨∆¿§È§Ï§Î°◊§»§§§¶§´§ §Í∂Ø∞˙§ ≤Úº·§Œ§‚§»§À°§GeForce RTX•∑•Í°º•∫§Œ•Ï•§•»•Ï°º•∑•Û•∞¿≠«Ω§ÚøÙ√Õ≤Ω§∑§ø§‚§Œ§«§¢§Î°£§ §™°§RT-TFLOPS§Œ∑◊ªª ˝À°§À§ƒ§§§∆§œ°§§≥§¡§È§Œµ≠ªˆ§À§¢§Î°÷≤Úÿ!? RTX-OPS§Œ∆Ê°◊§Úª≤滧∑§∆§€§∑§§°£
°°Tensor Core§ŒÕ˝œ¿¿≠«Ω√Õ§«§¢§Î°÷101 TensorFLOPS°◊§»§œ§…§¶§§§¶∞’㧨§¢§Î§Œ§´°£
°°Ampere•¢°º•≠•∆•Ø•¡•„§ŒGPU§«§œ°§ø‰œ¿•¢•Ø•ª•È•Ï°º•ø§«§¢§ÎTensor Core§œ°§SM 1¥§¢§ø§Í4¥§¢§Î§Œ§«°§¡ÌøÙ§œSMøÙ°þ4§»§ §Î°£§ƒ§Þ§Í°§GeForce RTX 3060§«§œTensor Core¡ÌøÙ§¨112¥§À§ §Î°£
°°§Ω§Œ§¶§®§«°§Ampere•¢°º•≠•∆•Ø•¡•„§ŒTensor Core§«§œ°§1¥§¢§ø§Í16bit»æ¿∫≈Ÿ…‚∆∞æÆøÙ≈¿° FP16°ÀøÙ§Œ¿—œ¬ªª§Ú1•Ø•Ì•√•Ø§¢§ø§Í128 ¬ŒÛ§«∑◊ªª≤ƒ«Ω§¿°£§»§§§¶§≥§»§«∑◊ªªº∞§œ§≥§¶§ §Î°£
- 112¥°þ1.78GHz°þ128 ¬ŒÛ°þ2 FLOPS¢‚51.11T TensorFLOPS
°°°÷NVIDIA§Œ∏¯æŒ√Õ§œ°§2«Ð§Œ101T TensorFLOPS§∏§„§ §§§´°©°◊§»§§§¶•ƒ•√•≥•þ§œ§¥§‚§√§»§‚°£§≥§≥§«∑◊ªª§∑§ø√Õ§œ°§π‘ŒÛÕ◊¡«§Œ§π§Ÿ§∆§Àº¬øÙ√Õ§¨§¢§Îπ‘ŒÛ§«§Œ±Èªª¿≠«Ω§Ú…Ω§∑§ø§‚§Œ§¿°£∞Ï ˝°§NVIDIA§Œ∏¯æŒ√Õ§«§¢§Î101T TensorFLOPS§œ°§º¬∏˙¿≠«Ω§¨2«Ð§À§ §Î¡¬π‘ŒÛ° ¢®π‘ŒÛÕ◊¡«§Œ»æ ¨§¨•º•Ì√Õ°À§ŒÕ˝œ¿¿≠«Ω√Õ§Úº®§∑§∆§§§Î§ø§·§¿°£
•·•‚•Í•–•π¬”∞Ë…˝§‰ROP¿≠«Ω§œGeForce RTX 2060 ¬§þ§´
°°±Èªª¿≠«Ω§«GeForce RTX 2080 SUPER§Úƒ∂§®§øGeForce RTX 3060§œ°§≈Î∫Е´°º•…§Œ¡€ƒÍ«‰≤¡§¨329•…•Î§«°§2∑Ó≤ºΩЧÀ»Ø«‰ª˛¥¸§»§ §Î§Ω§¶§¿°£»Ø…Ωª˛§Œ≤¡≥ §¨699•…•Î§¿§√§øGeForce RTX 2080 SUPER§Œ»æ ¨∞ ≤º§»§§§¶≤¡≥ §œ°§§»§∆§‚§™«„§§∆¿§ §Œ§œ¥÷∞„§§§ §§°£§»§œ§§§®°§æÂ∞Õ‚•«•Î§»§ §ÎGeForce RTX 3060 Ti∞ 槻§œ°§•·•‚•Í•–•π¬”∞Ë…˝§À≥ ∫𧨧¢§Î§Œ§¿°£
°°GeForce RTX 3060§œ°§•∞•È•’•£•√•Ø•π•·•‚•Í§»§∑§∆Õ∆ŒÃ12GB§ŒGDDR6§Ú∫ŒÕ—§π§Î°£§≥§Ï§œ°§æÂ∞õ°§«§¢§ÎGeForce RTX 3060 Ti§Œ8GB§œ§™§Ì§´°§GeForce RTX 3080§Œ10GB§Ë§Í§‚¬ø§§°£§∑§´§∑°§GeForce RTX 3060§Œ•·•‚•Í•§•Û•ø•’•ß°º•π§œ192bitªþ§Þ§Í§«°§GeForce RTX 3080§Œ320bit§œ§‚§¡§Ì§Û§Œ§≥§»°§GeForce RTX 3060 Ti§Œ256bit§»»Ê§Ÿ§∆§‚∏´ŒÙ§Í§π§Î°£
°°GeForce RTX 3060§Œ•·•‚•Í¬”∞Ë…˝§œ•·•‚•Í•Ø•Ì•√•Ø14GHz¡Í≈ˆ§ŒGDDR6§Ú∫ŒÕ—§∑§øæÏπÁ§œ336GB/s°§15GHz¡Í≈ˆ§«360GB/s§»§ §Î§ø§·°§§≥§Œ•π•⁄•√•Ø§œ°§¿Ë¬Â§ŒGeForce RTX 2060§» —§Ô§È§ §§°£GeForce RTX 3060§Œ±Èªª¿≠«Ω§œ¿Ë¬Â»Ê§«2«Ð∞ æ§Àπ‚§Þ§√§ø§¨°§•·•‚•Í•–•π¬”∞Ë…˝§œ§€§»§Û§… —§Ô§È§ §§§Œ§¿°£
°°§Þ§ø°§•Ï•Û•¿•Í•Û•∞§∑§ø•∞•È•’•£•√•Ø•π§Ú•·•‚•Í§ÀΩÒ§≠π˛§ýΩËÕ˝§Ú√¥≈ˆ§π§ÎROP° Rendering Output Pipeline°À§À§ƒ§§§∆§‚°§¡ÌøÙ§œÃ¿§È§´§À§ §√§∆§§§ §§°£GeForce RTX 3060 Ti§»∆±≈˘§Œ80¥§»§ §√§∆§§§Ï§–§Ë§§§¨°§GeForce RTX 3060§œ•·•‚•Í•§•Û•ø•’•ß°º•π…˝§¨192bit§ §Œ§«°§192bit…˝§ŒGeForce RTX 2060§»∆±§∏48¥§Œ§Þ§Þ§»§ §Î≤ƒ«Ω¿≠§‚π‚§§°£
°°•∞•È•’•£•√•Ø•π•·•‚•Í§Œ•·•‚•Í•–•π¬”∞Ë…˝§¨∏˛æ§∑§∆§§§ §§§≥§»§‰°§ROPøÙ§¨¬ø§Ø§ §§§≥§»§¨≤ø§À∂¡§Ø§´§»§§§¶§»°§4K≤Ú¡¸≈Ÿ° 3840°þ2160•…•√•»°À§ÿ§Œ¬–±˛§¨∆Ò§∑§Ø§ §Î§≥§»§¿°£º¬∫ð°§NVIDIA§‚°÷GeForce RTX 3060§œ°§•Í•¢•Î•ø•§•ý•Ï•§•»•Ï°º•∑•Û•∞§Ú≥ËÕ—§∑§ø•’•ÎHD•≤°º•þ•Û•∞§À∫«≈¨§«§¢§Î°◊§»•¢•‘°º•Î§∑§∆§§§Î°£
 |
°°§ø§¿°§°÷GeForce RTX 3060§«4K≤Ú¡¸≈Ÿ§«§Œ•≤°º•ý•◊•Ï•§§œ»Û∏Ωº¬≈™§ §Œ§´°◊§»§§§¶§»°§§Ω§¶§«§‚§ §§°£NVIDIA§Œ•¢•Û•¡•®•§•Í•¢•∑•Û•∞°ıƒ∂≤Ú¡¸µªΩ—°÷DLSS°◊° Deep Learning Super Sampling°À§Ú≥ËÕ—§π§ÎºÍ§¨§¢§Î°£
°°DLSS§œ°§GeForce RTX•∑•Í°º•∫§ŒTensor Core§Úª»§√§∆°§•¢•Û•¡•®•§•Í•¢•∑•Û•∞ΩËÕ˝§Úπ‘§√§ø§Í°§•Ï•Û•¿•Í•Û•∞±«¡¸§Œ≤Ú¡¸≈Ÿ§À•¢•√•◊•π•±°º•Î§π§ÎΩËÕ˝∑œ§Œ§≥§»§¿°£æЧ∑§§¿‚ÿ§œ≤·µÓµ≠ªˆ§Úª≤滧∑§∆§€§∑§§§¨°§GPU§»§∑§∆…¡≤˧π§Î≤Ú¡¸≈Ÿ§œ1920°þ1080•…•√•»§‰2560°þ1440•…•√•»§«§¢§√§∆§‚°§…Ωº®ª˛§ÀDLSS§«ƒ∂≤Ú¡¸ΩËÕ˝§Ú𑧶§≥§»§«°§4K≤Ú¡¸≈Ÿ…Ωº®§Ú𑧶§≥§»§¨§«§≠§Î°£•≤°º•ý¬¶§Œ¬–±˛§¨…¨øЧ«§¢§Î§∑°§•Í•¢•Î§ 4K…¡≤˧«§‚§ §§§¨°§§Ω§Œ≈¿§Ú¬≈∂®§π§Ï§–GeForce RTX 3060§«§‚4K•≤°º•þ•Û•∞§œ≥⁄§∑§·§Î§¿§Ì§¶°£
NVIDIA»«°÷Smart Access Memory°◊§¨ªœ∆∞
°°GeForce RTX 3060§¨§È§þ§«°§§‚§¶§“§»§ƒ•€•√•»•»•‘•√•Ø§ §Œ§œ°÷Resizable BAR°◊§¿°£
°°∑Îœ¿§´§È∏¿§√§∆§∑§Þ§¶§»°§§≥§Ï§œ°§AMD§¨Radeon RX 6000•∑•Í°º•∫∏«Õ≠§Œµ°«Ω§»§∑§∆»Ø…Ω§∑§ø°÷Smart Access Memory°◊§»¥∞¡¥§À∆±§∏µ°«Ω§À§ §Î°£æÐ∫Ÿ§œRadeon RX 6000§ŒæÐ Û§Úª≤滧∑§∆§€§∑§§§¨°§ÀÐπ∆§«§‚∑⁄§Ø≤Ú¿‚§∑§∆§™§≥§¶°£
°°CPU§´§È°§GPU§Œ¿©∏Ê≤º§À§¢§Î•∞•È•’•£•√•Ø•π•·•‚•Í§ÿ§Œ•«°º•ø≈桘§œ°§PCI Express° ∞ ≤º°§PCIe°À§Œµ°«Ω§Úª»§√§∆𑧶§Œ§¿§¨°§§≥§Ï§Þ§«CPU§œ°§•∞•È•’•£•√•Ø•π•·•‚•Í§Œ¡¥∞˧À¬–§∑§∆ƒæ¿Ð≈™§ •¢•…•Ï•πªÿƒÍ§À§Ë§Î•·•‚•Í•¢•Ø•ª•π§œ§«§≠§ §´§√§ø°£ £øÙ§Œ•§•Û•«•√•Ø•π§Ú¡»§þπÁ§Ô§ª§∆°§∫«ƒπ4096byte√±∞竧Œ•¢•Ø•ª•π§∑§´§«§≠§ §´§√§ø§Œ§¿°£•§•Û•«•√•Ø•π§Œ¡»§þπÁ§Ô§ª§œ16bitƒπ° 0°¡65535°À§»§ §√§∆§§§Î§ø§·°§CPU§´§È§œ256MB° °·4096byte°þ65536°À•µ•§•∫§Œ»œ∞œ§∑§´•¢•Ø•ª•π§«§≠§ §§§≥§»§À§ §Î°£
°°§ƒ§Þ§Í°§ΩæÕ˧œCPU°¡GPU¥÷§Œ•«°º•ø≈¡¡˜§œ°§∫«¬Á256MB•µ•§•∫§Œ¡Î§ÚƒÃ§∑§∆°§GPU§¨¥…Õ˝§π§Î•∞•È•’•£•√•Ø•π•·•‚•Í∂ı¥÷槌…¨Õ◊§ •¢•…•Ï•π§À•Í•Ï°º≈桘§Úπ‘§√§∆§§§ø§Œ§¿°£
 |
°°§ƒ§Þ§Í°§Smart Access Memory§‰Resizable BAR§Úª»§¶§≥§»§«°§256MB§Œœ»§ÚºË§Í ߧ¶§≥§»§¨≤ƒ«Ω§»§ §Í°§CPU¬¶§´§ÈGPU¥…Õ˝≤º§Œ•∞•È•’•£•√•Ø•π•·•‚•Í∂ı¥÷§À•«°º•ø§Úƒæ¡˜§«§≠§Î§Ë§¶§À§ §Î°£256MB√±∞竧Œ•Í•Ï°º«€¡˜§‚…‘Õ◊§À§ §Î§Œ§¿°£
°°§Ω§≥§«µ§§À§ §Î§Œ§œ°§§…§Û§ §»§≠§ÀResizable BAR§Œ•·•Í•√•»§¨∆¿§È§Ï§Î§´§¿§¨°§¥ÀÐ≈™§À°§CPU§´§ÈGPU§ÿ≤ø§´§∑§È§Œ•«°º•ø§Ú≈¡¡˜§π§Î§»§≠§À§œ§π§Ÿ§∆∏˙§Ø°£•≤°º•ý§‰•¢•◊•Í•±°º•∑•Á•Û¬¶§¨Resizable BAR§À¬–±˛§π§Î…¨Õ◊§‚§ §∑°£DirectX 11§¿§Ì§¶§¨DirectX 12§¿§Ì§¶§¨°§API§Œ∞„§§§‚¥ÿ∑∏§ §§°£§≥§Ï§œ°§CPU§´§ÈGPU§À≤ø§´§∑§È§Œ•«°º•ø§Ú≈¡¡˜§π§Î§»§≠§ÀGPU§Œ•…•È•§•–•Ω•’•»§¨¥ÿ§Ô§ÎΩËÕ˝∑œ§«§¢§Ï§–°§§π§Ÿ§∆§À§™§§§∆Resizable BAR§¨Õ¯Õ—§µ§Ï§Î§ø§·§¿°£§≥§Œ§¢§ø§Í§Œ∆√¿≠§‚Smart Access Memory§»§Þ§√§ø§Ø∆±§∏§«§¢§Î°£
°°§µ§∆°§§…§ŒNVIDIA¿ΩGPU§¨Resizable BAR§À¬–±˛§π§Î§Œ§´§¿§¨°§NVIDIA§œ°÷Resizable BAR§Œª≈¡»§þ§œ°§GeForce RTX 30•∑•Í°º•∫§´§È§Œ¬–±˛§»§ §Î°◊§»¿‚ÿ§∑§∆§§§Î°£∫«ΩȧœGeForce RTX 3060§´§È•π•ø°º•»§∑§∆°§¬≥§§§∆∏ÂΩ“§π§Î•Œ°º•»PC»«GeForce RTX 30•∑•Í°º•∫°§∫«∏§À¥˚¬∏§ŒGeForce RTX 30•∑•Í°º•∫§‚¬–±˛§π§Î§»§§§¶°£¥˚¬∏§ŒGeForce RTX 30≈Î∫Е∞•È•’•£•√•Ø•π•´°º•…§ÚResizable BAR§À¬–±˛§µ§ª§Î§À§œ°§GPU§ŒBIOS° VBIOS°À§Œππø∑§»•Þ•∂°º•Ð°º•…§ŒBIOSππø∑§ŒŒæ ˝§¨…¨øЧ»§Œ§≥§»§ §Œ§«°§æÐ∫Ÿ§œ¬≥ Û§Ú¬‘§ƒ…¨Õ◊§¨§¢§Î°£
°°¬–±˛»«VBIOS§‰BIOS§Œ∂Ò¬Œ≈™§ ƒÛ∂°ª˛¥¸§œÃ¿§È§´§À§ §√§∆§§§ §§§¨°§°÷Coming Soon°◊§¿§Ω§¶§ §Œ§«°§§Ω§Ï§€§…¬‘§ø§µ§Ï§∫§À≈–æϧπ§Î§Ë§¶§¿°£
°°§¡§ §þ§À°§AMD§ŒSmart Access Memory§œ°§CPU§»GPU§¨§»§‚§ÀAMD¿Ω§«§¢§Î…¨Õ◊§¨§¢§√§ø§¨°§NVIDIA§œResizable BAR§¨°§°÷AMD§ŒCPU§»Intel§ŒCPU§ŒŒæ ˝§À¬–±˛§π§Î°◊§»∂؃¥§∑§∆§§§ø°£AMD§œº´º“¿Ω… §«∞œ§§π˛§ý¿ÔŒ¨§ÚºË§√§ø§¨°§NVIDIA§œµ’§À•™°º•◊•Û§ •π•ø•Û•π§ÚºË§Î§Ô§±§¿°£
•Œ°º•»PC»«GeForce RTX 30•∑•Í°º•∫≈–æÏ
Max-Q§œ¬Ë3¿§¬Â§ÿ§»ø ≤Ω
°°¬≥§§§∆§œ°§•Œ°º•»PC∏˛§±GeForce RTX 30•∑•Í°º•∫§Œ»Ø…Ω§Úø∂§Í ÷§√§∆§þ§Ë§¶°£§Þ§∫°§∆±•∑•Í°º•∫≈Î∫ЕŒ°º•»PC§œ°§¡·§§§‚§Œ§¿§»1∑Ó≤ºΩЧ´§È»Ø«‰§»§ §Î§Ω§¶§¿°£
 |
°°∫£≤Û»Ø…Ω§»§ §√§ø§Œ§œ°§°÷GeForce RTX 3080°◊°÷GeForce RTX 3070°◊°÷GeForce RTX 3060°◊§Œ3¿Ω… °£¿Ω… Ã槜•«•π•Ø•»•√•◊PC∏˛§±GPU§»∆±§∏Ãæ¡∞§¿§¨°§ª≈ÕÕ§œ§¿§§§÷∞€§ §√§∆§§§Î°£
 |
°°•Œ°º•»PC∏˛§±§ŒGeForce RTX 3080§œ°§CUDA CoreøÙ§¨6144¥§«°§∆∞∫Ó•Ø•Ì•√•Ø§œ1245MHz°¡1710MHz°§•∞•È•’•£•√•Ø•π•·•‚•Í§œGDDR6§ŒÕ∆ŒÃ8GB°§§‚§∑§Ø§œÕ∆ŒÃ16GB§»§ §√§∆§§§Î°£•«•π•Ø•»•√•◊PC»«° CUDA CoreøÙ8704¥°§1440°¡1710MHz°À§À»Ê§Ÿ§Î§»°§CUDA CoreøÙ§œ§´§ §Íæا §Ø°§∆∞∫Ó•Ø•Ì•√•Ø§‚§‰§‰πµ§®§·§¿°£
°°§ø§¿°§•∞•È•’•£•√•Ø•π•·•‚•ÍÕ∆ŒÃ§œœ√§¨ ç«°§8GB•‚•«•Î§œ•«•π•Ø•»•√•◊PC»«§ŒÕ∆ŒÃ10GB§Ë§Í§‚æا §§§¨°§16GB•‚•«•Î§ŒæÏπÁ§œµ’§À¬ø§§°£Õ˝œ¿¿≠«Ω√Õ§œ21.01TFLOPS§«°§•«•π•Ø•»•√•◊PC»«§Ë§Í§‚≈ˆ¡≥§ §¨§È𵧮§·§¿°£
°°•«•π•Ø•»•√•◊PC»«§ŒGeForce RTX 3080§œ°§GPU•≥•¢§À°÷GA102°◊§Ú∫ŒÕ—§∑§∆§§§ø§¨°§•Œ°º•»PC»«§ŒGeForce RTX 3080§œ°§•«•π•Ø•»•√•◊PC»«GeForce RTX 3070§»∆±§∏°÷GA104°◊§Ú∫ŒÕ—§∑§∆§§§Î§»ª◊§Ô§Ï§Î°£§»§§§¶§Œ§‚°§CUDA CoreøÙ6144¥§œ°§•’•Î•π•⁄•√•Ø»«GA104§Œª≈ÕÕ§»πÁ√◊§π§Î§´§È§¿°£
- 128 CUDA Core°þ12 SM°þ4 GPC°·6144 CUDA Core
°°§™§Ω§È§Ø§¿§¨°§•’•Î•π•⁄•√•Ø»«§»§∑§∆∆∞∫Ó§«§≠§ÎGA104§Ú¡™ ç∑§∆•Œ°º•»PC»«GeForce RTX 3080§»§∑§∆∫ŒÕ—§∑§∆§§§Î§Œ§¿§Ì§¶°£
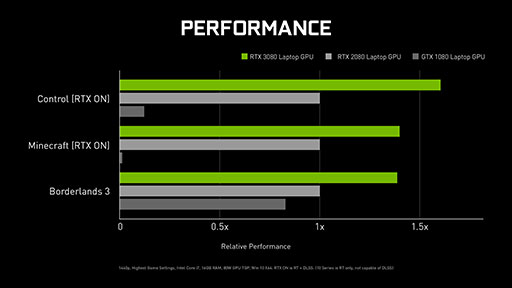 |
°°º°§À°§•Œ°º•»PC∏˛§±§ŒGeForce RTX 3070§œ°§CUDA CoreøÙ§¨5120¥§«°§∆∞∫Ó•Ø•Ì•√•Ø§œ1290MHz°¡1620MHz°§•∞•È•’•£•√•Ø•π•·•‚•Í§œGDDR6§Œ8GB§»§ §√§∆§§§Î°£§≥§¡§È§‚•«•π•Ø•»•√•◊PC»«° 5888¥°§1.5°¡1.73GHz°À§»»Ê§Ÿ§Î§»°§CUDA CoreøÙ§œæا §Ø∆∞∫Ó•Ø•Ì•√•Ø§‚𵧮§·§¿°£§ø§¿°§•∞•È•’•£•√•Ø•π•·•‚•ÍÕ∆ŒÃ§œ∆±≈˘§«§¢§Î°£
°°Õ˝œ¿¿≠«Ω√Õ§œ16.59TFLOPS§«°§§≥§¡§È§‚•«•π•Ø•»•√•◊PC»«§Ë§Íƒ„§§°£§™§Ω§È§ØGPUº´¬Œ§œ°§•«•π•Ø•»•√•◊PC»«§ŒGA104§Ω§Œ§‚§Œ§Ú∫ŒÕ—§∑§∆§§§Î§‚§Œ§»∏´§È§Ï§Î§Œ§«°§GA104§¨ª˝§ƒ12¥§ŒSM§´§È2¥ ¨§Úõ∏˙≤Ω§∑§∆°§
- 128 CUDA Core°þ10 SM°þ4 GPC°·5120 CUDA Core
§À§ §√§∆§§§Î§‚§Œ§»∏´§È§Ï§Î°£
°°∫«∏§Œ•Œ°º•»PC∏˛§±GeForce RTX 3060§œ°§CUDA CoreøÙ§¨3840¥§«°§∆∞∫Ó•Ø•Ì•√•Ø§œ1283MHz°¡1703MHz°§•∞•È•’•£•√•Ø•π•·•‚•Í§œGDDR6§ŒÕ∆ŒÃ6GB§»§ §√§∆§§§Î°£•«•π•Ø•»•√•◊PC»«° 3584¥°§1.32°¡1.78GHz°À§»»Ê§Ÿ§∆°§CUDA CoreøÙ§œµ’§À¬ø§§§Œ§¿§¨°§∆∞∫Ó•Ø•Ì•√•Ø§œπµ§®§·§«°§•∞•È•’•£•√•Ø•π•·•‚•ÍÕ∆ŒÃ§‚»æ ¨§À§ §√§∆§§§Î°£
°°Õ˝œ¿¿≠«Ω√Õ§œ13.01TFLOPS§ §Œ§«°§§Ô§∫§´§À•Œ°º•»PC»«§Œ§€§¶§¨π‚§§§≥§»§À§ §Î§¨°§•Œ°º•»PC§ŒæÏπÁ§œ°§ ¸«Æ¿þ∑◊§À§Ë§√§∆∫«¬Á¿≠«Ω§¨ —§Ô§Î§Œ§«°§º¬∏˙¿≠«Ω§«§œ§…§¶§ §Î§´§œPC§Œ¿þ∑◊º°¬Ë§¿°£§Ω§Ï§À§∑§∆§‚°§CUDA CoreøÙ§¨3840¥§»§§§¶§≥§»§œ°§•«•π•Ø•»•√•◊PC»«§Œ¿‚ÿ§«ø‰¬¨§∑§øGPC 3¥πΩ¿Æ§Œ•’•Î•π•⁄•√•Ø»«GA106§Ω§Œ§‚§Œ§ §Œ§¿§Ì§¶§´°£
 |
°°¥ √±§À¿‚ÿ§π§Î§»°§Max-Q§»§œ°§«ˆ∑ø∑⁄ŒÃ•Œ°º•»PC§À§™§±§ÎTDP° Thermal Design Power°§«Æ¿þ∑◊æ√»Ò≈≈Œœ°À§Œ»œ∞œ∆‚§Àº˝§Þ§Î§Ë§¶§À°§GPU§Œæ√»Ò≈≈Œœ§»»Ø«Æ§ÚÕÞ§®§ §¨§È≤ƒ«Ω§ ∏¬§Íπ‚§§¿≠«Ω§Ú»Ø¥¯§«§≠§Î≈≈∞µ§»∆∞∫Ó•Ø•Ì•√•Ø§«∆∞§´§πµªΩ—§«§¢§Î°£Õ≠§Í¬Œ§À∏¿§®§–°§GPU§¨ª˝§ƒ∫«¬Á¿≠«Ω§Ú∞˙§≠Ω–§π§Œ§œ∫«Ωȧ´§Èƒ¸§·§∆°§«ˆ∑ø∑⁄ŒÃ•Œ°º•»PC§«≤ƒ«Ω§ æ√»Ò≈≈Œœ§Àº˝§Þ§Îœ»∆‚§«æ√»Ò≈≈Œœ¬–ΩËÕ˝¿≠«Ω»Ê§Úπ‚§·§Î§≥§»§Ú¡¿§√§øµªΩ—°§§»§‚∏¿§®§Î°£
°°¬Ë3¿§¬ÂMax-Q§ŒÕ◊¡«µªΩ—§»§∑§∆°§NVIDIA§œ°§°÷Dynamic Boost 2.0°◊§»°÷Whisper Mode 2.0°◊§Úæ“≤§∑§∆§§§Î°£
°°§Þ§∫°÷Dynamic Boost2.0°◊§œ°§ø ≤Ω∑œDynamic Boost§À¡Í≈ˆ§π§Î°£¿Ë¬Â§ŒDynamic Boost§œ°§PC§«∆∞∫Ó§∑§∆§§§Î•¢•◊•Í•±°º•∑•Á•Û§¨CPU§»GPU§Œ§…§¡§È§À…È≤Ÿ§Ú§´§±§Î§´§Ú¥∆ªÎ§∑§∆°§§Ë§Íπ‚§§…È≤Ÿ§¨§´§´§Î•◊•Ì•ª•√•µ§Œ§€§¶§À≈≈ŒœÕΩªª° ¢‚»Ø«ÆÕΩªª°À§Ú≥‰§Í≈ˆ§∆§Î¿©∏ʧÚ𑧶µªΩ—§¿§√§ø°£Dynamic Boost2.0§«§œ°§§Ω§Œ¿©∏ʬ–æð§À•∞•È•’•£•√•Ø•π•·•‚•Í§Ú¡»§þ∆˛§Ï§ø§‚§Œ§«§¢§Î°£§ §™°§•·•§•Û•·•‚•Í§œ¿©∏ʬ–æ𧫧œ§ §§°£
 |
°°2§ƒ§·§ŒWhisper Mode 2.0§‚°§ø ≤Ω∑œWhisper Mode§«°§•Œ°º•»PC§«•≤°º•ý§Ú∆∞∫Ó§µ§ª§ø§»§≠§Œ¿≠«Ω§Ú°§Œ‰µ—•’•°•Û§Œ¡˚≤ªŒÃ° dB√Õ°À§Ú¥Ωý§»§∑§∆¿©∏ʧπ§Î§‚§Œ§¿°£§ §™°§•Œ°º•»PC¬¶§À¿ÏÕ—§Œ¡˚≤ª•ª•Û•µ°º§ÚºË§Í…’§±§∆§§§Î§»§§§¶§Ô§±§«§œ§ §Ø°§NVIDIA§»•Œ°º•»PC•Ÿ•Û•¿°º§¨°§ªˆ¡∞§À•Œ°º•»PC§Œ¡¥¬ŒŒ‰µ—¿≠«Ω§À∏´πÁ§√§ø≥∆•≤°º•ý§¥§»§Œ∆∞∫Ó¿þƒÍ§Ú•◊•Ì•’•°•§•Î§»§∑§∆ƒÍµ¡§∑§∆§§§Î°£
°°NVIDIA§Œ¿‚ÿ§À§Ë§Î§»°§•◊•Ì•’•°•§•Î§œ°§e•π•ð°º•ƒ∑œ§Œ∂•µª¿≠§Œπ‚§§•≤°º•ý§œ•’•Ï°º•ý•Ï°º•»Ω≈ªÎ§«•∞•È•’•£•√•Ø•π… º¡§œπµ§®§·°§•∑•Û•∞•Î•◊•Ï•§∏˛§±§Œ•∑•Õ•Þ•∆•£•√•Ø§ •≤°º•ý§«§œ•’•Ï°º•ý•Ï°º•»§Ë§Í§‚•∞•È•’•£•√•Ø… º¡§Úπ‚§·§À§π§Î§»§§§¶¿þ∑◊ ˝øÀ§«∫Ó§Íπ˛§Û§«§¢§Î§Ω§¶§¿°£
°°§ §™°§2.0§«ƒ…≤√°§§¢§Î§§§œ —π𧻧 §√§ø…Ù ¨§À§ƒ§§§∆NVIDIA§œ°§°÷CPU§‰GPU§Œ¿≠«Ω°§•∑•π•∆•ý≤π≈Ÿ°§•’•°•Û¬Æ≈Ÿ§»§§§√§ø•—•È•·°º•ø§ÚAI•Ÿ°º•π§ŒµªΩ—§«¿©∏ʧπ§Î§Ë§¶§Àø ≤Ω§∑§ø°◊§»¿‚ÿ§∑§∆§§§Î°£AI•Ÿ°º•π§»§œ§§§®°§Whisper Mode 2.0§Œº¬π‘§ÀTensor Core§¨…¨Õ◊§»§§§¶§≥§»§œ§ §µ§Ω§¶§«°§ªˆ¡∞§Œ•◊•Ì•’•°•§•Î¿þ∑◊§ÀAIµªΩ—§Ú≥ËÕ—§∑§ø§»§§§¶§≥§»§Œ§Ë§¶§¿°£
°°§≥§Œ§€§´§À§‚•§•Ÿ•Û•»§«NVIDIA§œ°§¡ý∫Ó√Ÿ±‰∑◊¬¨µ°«Ω°÷NVIDIA Reflex Latency Analyzer°◊° ∞ ≤º°§RLA°À§Ú≈Î∫Чπ§Îø∑§∑§§•≤°º•Þ°º∏˛§±±’æΩ•«•£•π•◊•Ï•§¿Ω… §¨°§2021«Ø§À§‚≥∆•·°º•´°º§´§È≈–æϧπ§Î§≥§»§‚π√Œ§∑§ø°£
°°RLA§»§œ°§√Ÿ±‰∑◊¬¨•ƒ°º•Î°÷LDAT°◊§À¡Í≈ˆ§π§Îµ°«Ω§Œ§≥§»§¿°£
 |
°°RLAº´¬Œ§œ2020«Ø9∑Ó§À»Ø…Ω§µ§Ï§ø§–§´§Í§¿§¨°§2021«Ø∆‚§À8º“§´§È∑◊9µ°ºÔ§ŒRLA≈Î∫Е≤°º•Þ°º∏˛§±±’æΩ•«•£•π•◊•Ï•§¿Ω… §¨»Ø«‰§µ§Ï§Î∏´π˛§þ§¿§»§§§¶°£»ÛæÔ§À•Þ•À•¢•√•Ø§ ¿Ω… §¿§¨°§∂•µª¿≠§Œπ‚§§•≤°º•ý§Œ•◊•Ï•§§Àøø∑ı§ÀºË§Í¡»§Û§«§§§Î•≤°º•Þ°º§‰•◊•Ì•¡°º•ý§¨¡˝§®§∆§§§Î∫Ú∫£§«§œ°§§≥§¶§∑§ø¿Ω… §ÿ§Œ•À°º•∫§¨π‚§Þ§√§∆§§§Î§Œ§´§‚§∑§Ï§ §§°£
 |
°°∫£≤Û°§NVIDIA§œGPU§Œ•Ì°º•…•Þ•√•◊§À¥ÿ§π§Îœ√¬Í§À∏¿µ⁄§∑§ §´§√§ø§¨°§…ƺ‘§»§∑§∆§œ°§GeForce RTX 3080§‰GeForce RTX 3090§«ª»§Ô§Ï§øGA102§Œ•’•Î•π•⁄•√•Ø»«° CUDA CoreøÙ10752¥°À§¨¿Ω… §»§∑§∆≈–æϧπ§Î§Œ§´§¨µ§§À§ §√§∆§§§Î°£GA104§œ°§•Œ°º•»PC»«GeForce RTX 3080§»§∑§∆•’•Î•π•⁄•√•Ø»«§¨≈–æϧ∑§ø§Œ§«°§∆±§∏GPU§Ú•«•π•Ø•»•√•◊PC∏˛§±§»§∑§∆•Í•Í°º•π§π§Î§≥§»§À§‚¥¸¬‘§¨§´§´§Î°£•Œ°º•»PC»«§ŒGeForce RTX 3060§»§∑§∆≈–æϧ∑§ø•’•Î•π•⁄•√•Ø»«GA106§¨°§•«•π•Ø•»•√•◊PC∏˛§±§ÀƒÛ∂°§µ§Ï§Î§´§…§¶§´§‚µ§§À§ §Î§»§≥§Ì§¿°£
°°GeForce GTX•∑•Í°º•∫§À¬∏∫þ§∑§ø°÷50°◊∑ø»÷§¨°§°÷GA107°◊§»§∑§∆GeForce RTX 30•∑•Í°º•∫§À≈–æϧπ§Î§»§§§¶±Ω§¨ŒÆ§Ï§∆§§§Î§‚§Œ§Œ°§º¬∏Ω§π§Î§¿§Ì§¶§´°£§≥§¡§È§œTU106∑œ° ¢®GeForce RTX 2070§ §…°À§Œ•Í•Õ°º•ý¿Ω… §»§ §Î≤ƒ«Ω¿≠§‚»ðƒÍ§«§≠§ §§§¨°§§§§∫§Ï§À§ª§ËNVIDIA§œ°§AMD§À¿Ë∂Ó§±§∆°§•Í•¢•Î•ø•§•ý•Ï•§•»•Ï°º•∑•Û•∞¬–±˛GPU§Œæ§´§È≤º§Þ§«§Ú¬Ë2¿§¬ÂGeForce RTX§«¬∑§®§∆§Ø§Î§¿§Ì§¶°£
°°¬–§π§ÎAMD§‚°§•Í•¢•Î•ø•§•ý•Ï•§•»•Ï°º•∑•Û•∞¬–±˛§ŒRadeon RX 6000•∑•Í°º•∫§«≤º∞Õ‚•«•Î§Œ≈∏≥´§ÚÕΩƒÍ§∑§∆§§§Î§» π§Ø§Œ§«°§•þ•…•Î•Ø•È•π§«§ŒNVIDIA¬–AMD§Œ¬–∑˧‚Ãëڧا §Í§Ω§¶§«§¢§Î°£
NVIDIA§Œ•«•π•Ø•»•√•◊PC∏˛§±GeForce RTX 3060•∑•Í°º•∫¿Ω… æ Û•⁄°º•∏
NVIDIA§Œ•Œ°º•»PC∏˛§±GeForce¿Ω… æ Û•⁄°º•∏
- ¥ÿœ¢•ø•§•»•Î°ßGeForce RTX 30

- §≥§Œµ≠ªˆ§ŒURL°ß
4Gamer.net∫«ø∑æ Û
•◊•È•√•»•’•©°º•ý Ãø∑√µ≠ªˆ
¡ÌπÁø∑√µ≠ªˆ
¥Î≤˵≠ªˆ
ø∑√Âœ¢∫Ð
ø∑√•ϕ”•Â°º
ø∑√•§•Û•ø•”•Â°º