














ニュース
西川善司の3DGE:次世代GPU「Radeon RX 5700」シリーズの秘密に迫る。レイトレーシング対応は第2世代Naviに持ち越し?
 |
事前説明会のCPUに関する話は別の記事で紹介しているので,本稿ではAMDの次世代GPU「Navi」(開発コードネーム)の話題をレポートしよう。
ようやくスペックが明らかになったRadeon RX 5700
演算性能自体はVega 64におよばず
 |
また,2019年4月には,Sony Interactive
そんなNaviの全貌が,今回明らかとなった。これらについて,可能な範囲で説明していきたい。
 |
 |
Radeon RX 5000シリーズの上位モデルが「Radeon RX 5700 XT」(以下,
 |
なお,今回示されたいくつかの資料に「Navi 10」という記述があったので,AMD内部では,今世代のNaviをNavi 10と呼んでいるようである。
さて,GCNアーキテクチャになって以降のAMD製GPUは,Compute Unit(以下,
RX 5700シリーズでは,GPUのコアアーキテクチャが新しいRDNAになったとAMDはアピールしてきたが,1基のCUあたり,64基の汎用シェーダプロセッサ(以下,
- RX 5700 XT:64 SP×40 CU=2560 SP
- RX 5700:64 SP×36 CU=2304 SP
現行世代のGPUである「Vega 10」の「Radeon RX Vega 64」は,総SP数が4096基だったので,RX 5700シリーズのSPはずいぶん少ないわけだ。
RX 5700 XTの理論性能値は9.75 TFLOPSとなっているが,これは,
- 2560 SP×2 FLOPS×1905MHz=9.75 TFLOPS
という式で計算できる。ちなみに「×2 FLOPS」としているのは,AMD製GPUでは1 SPが1クロックで1つの積和算を行えるためだ。
RX 5700シリーズの場合,RX 5700のブースト最大クロックが1725MHzと動作クロックが高いため,SP数が少なくても,理論性能値は高くなる。それでも,
これはRX 5700シリーズがウルトラハイエンドクラスのGPUではなく,ハイミドルからハイエンドクラスをターゲットにした製品だからだろう。これはCOMPUTEX 2019で,RX 5700シリーズの比較対象がNVIDIAの「GeForce RTX 2070」となっていたことからもうかがえる。
グラフィックスメモリにHBM(High Bandwidth Memory)系ではなく,GDDR6を採用しているのも,RX 5700シリーズがウルトラハイエンドクラスではないことを物語っていよう。
RX 5700シリーズにおけるGDDR6メモリのデータレート(グラフィックスメモリクロック)は14GHzであることと,メモリインタフェースが256bit幅であることが明らかになっているので,メモリバス帯域幅は以下のように計算できる。
- 256bit×1.75GHz×8倍速(GDDR6)=448GB/s
ところで,RX 5700 XTとRX 5700のスペックを示したスライドに,「Game Clock」という気になるキーワードがあったことに気付いただろうか。AMDによると,Game Clockは「ゲームアプリケーションを駆動させるのに適した動作クロック」とのこと。つまりGame Clockは,ベースクロックとブーストクロックの間にくる2速ギアといったイメージだろうか。
RDNAアーキテクチャの利点とは?
それではお待ちかね,ずっと気になっていた意味深キーワードの「RDNA」を見ていきたい。
以下のスライドは,Navi 10におけるRDNAアーキテクチャのブロック図だ。
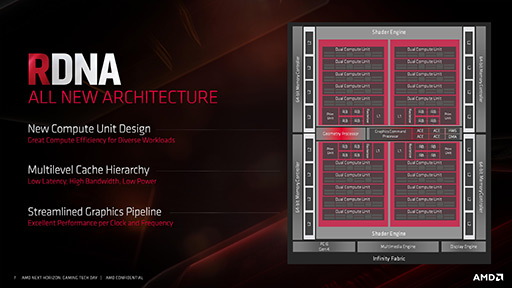 |
GCNアーキテクチャに詳しい人が見ると,何も変わっていないように見えるかもしれないが,実際,アーキテクチャの刷新というほどの大変革は行われていない。結論から言えば,GCNアーキテクチャのビッグマイナーチェンジといった印象だ。あえていうなら,現代的なリアルタイムグラフィックス(≒ゲームグラフィックス)の都合に合わせたテコ入れという印象か。
前述したように,1基のCUが64 SPを内包する構成は変わっていないが,RDNAでは,2基のCUが互いにキャッシュメモリのようなリソースを共有し,1つのCUとして動作できるようになった。これをAMDは「Work Group Processor」と呼んでいる。競合のNVIDIAは,GPU世代が変わるたびに,「SM」こと「Streaming Multiprocessor」の構成を変えることがあったが,あれに相当する構造の組み替えと理解していいだろう。
一方で,レジスタファイルサイズやテクスチャユニット数などは,GCNアーキテクチャから変更はない。
 |
注目すべきポイントはいくつかある。
GCNアーキテクチャでは,GPUに投げ込まれるデータスレッド「Wave」のサイズが64要素で固定されていた。GCNにおけるCUの演算実行ユニットは,SIMD16だったので,1サイクル(クロック)あたりに処理できるデータスレッドは16個。つまり,64要素からなるデータスレッド(Wave64)の処理には,64÷SIMD16=4サイクルの実行時間が必要だった。
RDNAでも,互換性維持のためにこの動作モードは継承するそうだが,別の動作モードとして,32要素からなるWave(Wave32)を容認することとしたのだ。これは,NVIDIAのCUDAアーキテクチャと同じサイズである。
そしてRDNAの場合,32要素の動作モードでは,CUがSIMD16動作からSIMD32動作へと切り替わるのだ。具体的には,2つのSIMD16が1つのSIMD32として動作するイメージとなる。つまり,Wave32からなるデータスレッドの処理は,32÷SIMD32=1サイクルとなるので,実行効率が上がるという理屈だ。
グラフィックスの場合,処理粒度を細かくするほうが都合がいいので,こうしたアーキテクチャへと方針転換をしたということになる。
RDNAにおける粒度の細分化にともなって,スカラ演算ユニットは1基から2基に増えて,増えたスカラ演算ユニットに対応するキャッシュメモリやレジスタファイルも増設された。Wave64ベースによるGPGPU活用時の互換性は維持しているので,RDNAをグラフィックス特化アーキテクチャと見なすのは,正しくないことになる。AMDが,RDNAを「GCNと共存する」と明言しているのは,「GPGPU用途のGPU(=GCNベースのGPU)は,Wave32をサポートしない」ということを意味するのだろう。
 |
RDNAはグラフィックス用途に向けて最適化したアーキテクチャであるというのは,キャッシュメモリ階層構造の変更に最も特徴として現れている。
GCNの場合,演算結果として得られたピクセル単位のデータを実際にグラフィックスメモリへと出力する「Render Back-Ends」は,L2キャッシュと紐付けられていた(関連記事)。一方,RDNAでは,Render Back-EndsがL1キャッシュと紐付けられるようになった。L1キャッシュは容量こそ小さいが,L2キャッシュよりも遅延が少ない。
それに加えてRDNAでは,グラフィックスメモリに書き出すピクセルデータをロスレス圧縮してから書き出す「Lossless Delta Color Compression」(以下 LDCC,関連記事)の仕組みが,Render Back-EndsとL1キャッシュの間だけでなく,すべてのキャッシュメモリ間でも行われるようになり,劇的なメモリ帯域幅の削減を実現しているのだ。
LDCCは,ピクセルの色情報に対して差分量子化圧縮と展開を行う仕組みである。隣接するピクセル同士は色情報が近いので,データとして表現する際には少ないビット数で表現してしまおうという仕組みである。
 |
この仕組みの実装は,Wave32モードと関係が深い。
つまりRDNAでは,粒度の細かくなったWave32構成データは,LDCCによりデータ量が減るのでL1キャッシュに載りやすくなり,演算処理対象のデータアクセスがL1キャッシュ内でヒットやすくなる。しかも,帯域幅のコストを抑えながらグラフィックスメモリへ書き出す構造としたわけだ。
分かりやすく言うと,なるべくGDDR6メモリにはアクセスせず,可能な限りL1キャッシュ内で処理して,最悪でもL2キャッシュ内で処理できるような処理系にしたということだ。
この構造が何をもたらすだろうか。たとえば,Zバッファに対する読み書きを高速化できそうだ。また,複数のレンダリング解像度で中間パラメータを書き出して,パラメータを参照しながらライティングやシェーディングを行う「Deferred Shading」(ディファードシェーディング)を,グラフィックスメモリへのアクセスを極力抑えながら行える可能性もある。
飛躍した推測かもしれないが,RDNAの構造はモバイル端末向けのGPUへの転用にも適しているので,AMDとSamsung Electronicsの協業がRDNAベースのグラフィックスIPを対象としているのにつながってくるとも言えよう。
Naviはリアルタイムレイトレーシングに対応しない
最後に「AMDのハードウェアレイトレーシング(リアルタイムレイトレーシング)に関する取り組み」に触れて本稿を締めくくるとしよう。
 |
Navi 10,すなわち初代RDNAアーキテクチャでは,既存のGCNアーキテクチャと同じく,GPGPU的なアプローチでのソフトウェアレイトレーシングにしか対応しない。AMDには「Radeon ProRender」というOpenCLベースのレイトレーシングエンジンがあるので,Navi 10では,OpenCLベースのRadeon ProRenderでレイトレーシングに対応するというスタンスになる。
では,「次世代PlayStationや次世代Xbox(Project Scarlett)では,NaviベースのGPUを採用してリアルタイムレイトレーシングを実現する」という話はどういうことだろうか。
答えは,どうやら「次世代RDNAで対応する」ということのようである。Vega世代GPUにRadeon RX Vega(Vega 10)シリーズと「Radeon VII」(Vega 20)があるように,おそらくは「Navi 20」的な次世代Naviで対応するのだろう。RDNAのWave32モードや,LDCCと新キャッシュ構造は,データアクセス粒度や頻度の側面から見ても,レイトレーシングとの相性が良さそうである。
 |
RDNAアーキテクチャ自体は,とても面白い「アーキテクチャへのテコ入れ」なのだが,ゲーマーが得られるグラフィックス体験としては,Vega世代と何も変わらないことになる。
この点は,AMDも「なんとかせねば」と思ったようで,今回の発表会でもグラフィックス以外におけるNaviならではの新機能や,Radeonファミリーならではのグラフィックス機能(※Naviでなくても利用できる)をお披露目している。このあたりについての詳細は,追ってレポートすることにしたい。
AMDのE3 2019特設Webページ(英語)
4GamerのE3 2019記事一覧
- 関連タイトル:
 Radeon RX 5000
Radeon RX 5000 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー