















連載
西川善司の3DGE:新設の「プリミティブシェーダ」を搭載し,Radeon RX Vegaはどこへ行く?
北米時間2017年7月30日から8月3日の会期で開催されたSIGGRAPH 2017。それに合わせてAMDのGPU部門であるRadeon Technologies Groupは,全世界の報道関係者を米ロサンゼルスに集め,新世代GPU「Radeon RX Vega」に関して,より深い技術解説を行った。
その内容は,1月の時点で明らかになっていた内容と多くの部分で重複していたが,一部,新しい情報も出てきたため,今回はそれらをまとめて紹介したいと思う。
「1月の話ってどんなのだっけ?」という人は,連載バックナンバー「AMD,次世代GPU『Vega』における4つの技術ポイントを公開。HBM2はキャッシュで使う!?」をチェックしてから,あらためて本稿に戻ってきてもらえれば幸いだ。
Vega世代では,新しいシェーダステージ「プリミティブシェーダ」(Primitive Shader)を採用することとなった。まずはその話から始めよう。
プリミティブシェーダについては1月のタイミングでも概要は出てきたが,今回明らかになったのは,もう少し具体的な情報だ。個人的には,Radeon Technologies Groupによる今回の発表内容で,最も驚いた部分だったりもする。
DirectXの歴史を少し振り返っておくと,DirectX 9までは以下のような構成だった。
DirectX 10時代になると,頂点シェーダ側にジオメトリシェーダ(Geometry Shader)が加わって,以下のようになる。
そしてDirectX 11時代になると,頂点シェーダとジオメトリシェーダの間にテッセレーションステージ(Tessellation Stage)が加わった。テッセレーションステージは「ハルシェーダ」(Hull Shader)と「テッセレータ」(Tessellator),そして「ドメインシェーダ」(Domain Shader)の3ブロックからなるため,構成としては以下のようになる。
こうして並べてみると,頂点シェーダからジオメトリシェーダまでのジオメトリパイプラインが煩雑だと分かる。誤解を招く覚悟で喩(たと)えるならば,「無計画に増改築が行われた違法建築」のようなカオスぶりだ。
実際,ゲーム開発者の間でも,「テッセレーションステージとジオメトリシェーダは使いにくい。性能が出ない」とされ,いまや「いらない子」扱い。結果として,ちょっと高度なジオメトリ処理を行う場合は,汎用性の高い「コンピュートシェーダ」(Cumpute Shader)でジオメトリパイプラインを“外注”する実装のほうが主流になりつつあるほどである。
プログラマブルシェーダアーキテクチャの進化がDirectX 11を境にしてうまくいかなくなっている背景には,煩雑になりすぎてしまったジオメトリパイプラインがあるという話も,開発者の間ではよく出てくる話題になっている。
プリミティブシェーダは,そんな状況に対して,Radeon Technologies Groupが「それなら我々が一肌脱ぎましょうか」と立ち上がり,提唱してきたものだ。「頂点単位の処理を行う頂点シェーダと,頂点の増減(=ポリゴンの増減)を行うジオメトリシェーダを再定義しましょう」といった感じである。
今日(こんにち)のグラフィックスでは,レンダリング後段で使用する多様な属性パラメータを頂点カラーなどに割り当てて,それらを頂点シェーダで処理したりすることが多い。しかも,その後に頂点の増減を行うジオメトリシェーダがきて,さらにそれを細分化させるテッセレーションステージがくる。
さらにテッセレータで分割されて増えた頂点はその後,テッセレーションステージにおける頂点シェーダ的な存在のドメインシェーダで処理を受けることになる。つまり,パイプラインの下流へ行けば行くほど,頂点データとそれに付随する属性パラメータの数が増大していく構造になってしまっているのである。
恐ろしいのは,頂点単位(≒ポリゴン単位)のデータ構造をピクセルに分解するラスタライザの段階で,画面に描かれないポリゴンを破棄する「視界外カリング」の対象となったり,ピクセルシェーダでの処理が終わってピクセルを描き出す段階になって,Zバッファ処理によって「視点から見えないピクセル」として破棄されたりするケースがあるということだ。
上流で処理すればするほどデータ量が増えるにもかかわらず,最下流のところで「それ全部いらないです」というちゃぶ台返しを喰らいやすい構造になっているのである。
プリミティブシェーダはこの問題を解決するアイデアなのだが,なぜそうなのかは,下の図を見ながらだと理解しやすいと思う。
まず,機能面で重複する頂点シェーダとドメインシェーダをプリミティブシェーダに統合し,「ポジションシェーディング」(Position Shading)という機能ブロックとして扱う。
ドメインシェーダは「テッセレータ実行後の頂点シェーダ」みたいなものなので,まとめることには合理性がある。
次に,「ジオメトリパイプラインの後段に行けば行くほど,頂点データと,付随する属性パラメータが爆発的に増えていく」ことを防ぐため,ジオメトリパイプラインの上流で早期カリングを行う機能ブロック「プリミティブカリング」(Primitive Culling)を置く。
加えて,複数ビューポートへ向けた投射のような,ジオメトリシェーダが持つ特殊なジオメトリパイプライン機能は,「アトリビュートシェーディング」(Attribute Shading)という機能ブロックが担当する。
以上の3ブロックが,プリミティブシェーダという新シェーダステージを司るプログラマブルシェーダとなるのだ。
しかも,話はこれで終わらない。
従来はジオメトリパイプライン後段に位置し,ジオメトリシェーダと一部機能がダブる部分もあったテッセレーションステージは,最上流に再配置となり,頂点(≒ポリゴン)分割機構であるテッセレータを制御するハルシェーダとともに,「サーフェスシェーディング」(Surface Shading)という機能ブロックとして再構成を果たした。
全体として,従来の「無計画な違法建築」然としていたジオメトリパイプラインが,リフォームされて美しい構造となった印象を受ける。
なお,Vegaの新しいジオメトリパイプラインでは,既存アプリケーションとの互換性を確保する目的から,従来型のジオメトリパイプラインを使うこともできる。なので,既存のDirectX 11やDirectX 12対応アプリケーションを使う限り,プリミティブシェーダの恩恵を受けることはほとんどない。
しかも,今回大刷新を果たしたこの新世代ジオメトリパイプライン,発表こそなされたものの,この後,どのような形で使えるようにするかは未定なのだそうだ。そのため,具体的な実動デモはなかった。
Radeon Technologies Groupは現在,DirectX規格の総元締めであるMicrosoftや,OpenGLおよびVulkanの規格を策定しているKhronos Groupと,新しいジオメトリパイプラインの取り扱いについて協議を進めていく計画だそうだ。
そういうステータスなので,当面の間,新しいジオメトリパイプラインの全機能を開発者に開放するといったことはせず,「既存のアプリケーションを動作させたときに,コンパイラやドライバソフトウェアレベルで新しいジオメトリパイプラインに当てはめて自動的に最適化する」ようなアプローチでの活用を行っていくとのことだった。
思い返してみると,こうしたアプローチは,かつて非プログラマブルシェーダアーキテクチャだったDirectX 7からプログラマブルシェーダアーキテクチャであるDirectX 8&9への移行期にもあった。あの頃は,DirectX 7標準の固定パイプライン機能を,プログラマブルシェーダアーキテクチャで再現した(=エミュレーションした)固定機能パイプラインに流し込むアイデアが実用化されていたのを憶えている読者もいることだろう。
このような自動最適化は,ぴたりとハマったときの効果が大きい一方,そうでない場合は互換性の面で問題を起こしたりするので,諸刃の剣感はある。
AMDはPlayStationやXboxにGPU――正確にはAPUだが――を提供しているので,ひょっとすると次世代PlayStationやXboxにプリミティブシェーダを標準採用させるような青写真を描き,それに向けて動いているという可能性もありそうだ。
すでに明らかになっているとおり,Graphics Core Next(以下,GCN)アーキテクチャ世代でVegaマクロアーキテクチャを採用するRadeon RX Vegaは,グラフィックスメモリを「GPUから見たシンプルなローカルメモリ」ではなく,キャッシュメモリとして取り扱うというメモリ仕様を採用している。これは,「数十GBから数TBクラスとなる大きなデータセットを,GPUプログラム側からリニアにアドレッシングしてアクセスできるようにする」ためだ。Radeon RX Vegaの場合,最大512TBという,極めて広大な領域を仮想メモリとして取り扱えるようになっている。
この仮想メモリに対するアクセスを司るのが,旧来的なGPUにおけるメモリコントローラに相当する「High-Bandwidth Cache Controller」(以下,HBCC)である。
AMDのRadeon Technologies GroupでGPUアーキテクチャ開発を率いるMike Mantor(マイク・マンター)氏は技術説明会で,Vega世代のGPUすべてがHBCCを採用すると述べていた。つまり,Radeon RX Vegaやワークステーション向けGPUだけでなく,将来のノートPC向けVegaや,次世代APU「Ryzen Mobile」が統合するVegaも同じメモリ仕様だということだ。
Vega世代のグラフィックスカードは,Radeon RX VegaもRadeon Proシリーズも第2世代High Bandwidth Memoryである「HBM2」をキャッシュメモリとして採用している。ではノートPC向けVegaやAPU統合版VegaもHBM2が前提かというと,そういうことでもないという。
Mantor氏いわく「HBCCは,GDDR5などと組み合わせることもできる」。HBM2を組み合わせにくいプラットフォームでは,ほかのメモリを組み合わせて出てくる可能性のほうが高そうである。
HBCCは基本的に自律動作する存在で,利用頻度の高いデータ領域をローカルメモリ(※事実上のグラフィックスメモリで,いま述べたとおり,Radeon RX Vegaの場合はHBM2。以下同)に配置し,そうでもないデータ領域はシステムメモリ(※CPUと共有するメインメモリで,最近のPCならDDR4接続となる。以下同)にスワップアウトしてくれる。もちろん,スワップインも自律動作で対応だ。
これらスワップアウトとスワップインは,「ページサイズ単位」(Mantor)氏とのこと。となると当然,ページサイズがいくつなのかが気になるところだが,氏の口からは「ページサイズは可変」以上の回答は得られず。もっとも,会場で別のGPUエンジニアに話を聞いてみたところ,「ページサイズは64KBが基本」と教えてもらえたので,その点は付記しておきたい。
また,キャッシュメモリの取り扱い法としてはInclusive(インクルーシブ,包括)モードととExclusive(エクスクルーシブ,排他)モードがあり,プログラマブルに切り換えられるとのことだ。
InclusiveとExclusiveの両モードはCPUキャッシュメモリでお馴染みと思われるが,念のため説明しておこう。
Inclusiveモードはローカルメモリとシステムメモリとでデータが“ダブる”モードだ。つまり,ローカルメモリにスワップインさせても,システムメモリ上には同じものが残る管理の仕方だ。
対してExclusiveモードは,ローカルメモリにシステムメモリからスワップインさせるとき,システムメモリ上のデータ領域を開放してしまう。
メモリ利用効率だけ見れば,Exclusiveモードのほうが優秀なのは言うまでもない。Inclusiveモードは冗長性があるものの,データ領域の出し入れ(=スワップアウトおよびスワップイン)を行うときのバス帯域消費や遅延を小さくできるメリットがある。端的に言えばInclusiveモードのほうが速い。
リアルタイム性能が要求されるゲームグラフィックスなどではInclusiveモードが有望である一方,機械学習型AIやオフラインレンダリングのような大規模データセットを取り扱う用途ではExclusiveモードのほうが相性はよかったりもするので,プログラマブルに切り換えられるようになっているわけである。
なお,これらスワップインおよびスワップアウト制御の対象は,システムメモリだけではなく,カード上に容量2TBのNVRAM(≒SSD)を搭載する「Radeon Pro SSG」に対しても透過的に行えるというのがRadeon Technologies Groupの説明だった。ただし,サードパーティのアプリケーション開発者に話を聞いたところ,現状のRadeon Pro SSG用APIだと,容量2TBのNVRAM領域は,GPUプログラム側で管理する設計になっているとのことである。
つまり,このあたりは,ハードウェアアーキテクチャとソフトウェアアーキテクチャ(=API設計)とで一貫性がまだ成立し切っていない可能性が高い。Radeon Technologies Groupとしては,もう少し時間をかけてHBCC周りを成熟させていく計画なのだろう。
GCNアーキテクチャを採用するGPUでは,1クロックあたり16個の32bit単精度浮動小数点(FP32)の積和算を行えるSIMD-16ベクトル演算器を4個ひとかたまりにして,これを1つの単位演算ユニットたる「Compute Unit」として扱っている。
1月の時点で筆者は,VegaのCompute Unitが半精度浮動小数点(以下,FP16)と8bit整数(以下,INT8)の「Packed実行」に対応することをお伝え済みだが,今回は,Radeon Technologies Groupが「Next-Generation Compute Unit」と呼ぶ新世代Compute Unitについて,さらに突っ込んだ話を聞くことができた。
Vegaより前の世代のGPUだと,FP16は,「FP32と比べてサイズが半分だから,レジスタの使用量をFP32比で半分にできる」くらいのメリットしかなかった。それがVegaでは,演算実行効率がFP32時の2倍になる。また,演算精度は「IEEE 754-2008」準拠となり,演算精度の信頼性や,異なるプラットフォームとの間におけるソフトウェア互換性も担保されることとなった。
ゲームエンジンにしろグラフィックスレンダラーにしろ,取り扱う処理内容によってFP16ないしFP32のどちらかを基準にして設計することが多い。というかそもそも,「FP16とFP32を自在に型変換して取り扱う」という発想が,GPUプログラミングにおいては一般的ではなかった。そのため,FP16を効果的に取り扱えるようにするためにはFP16とFP32との間で,柔軟かつ自由度の高い相互型変換が重要になってくる。そこでRadeon Technologies Groupは,そのあたりの命令セットも充実させたという。
「テクスチャユニットのサンプラー(=アクセス機構)は,読み書き対象が32bit幅であっても,16bit幅のPackedでシームレスにアクセスできるようになっている」(Mantor氏)と言うから徹底している。さらに積和算など,利用頻度の高い一部の命令では,FP16とFP32の型混在で直接実行できる柔軟性も取り入れてあるそうだ。
なお,一連の拡張はFP16だけでなく,16bit整数(Int16)でも利用可能とのことである。
この拡張により,32bit幅ではオーバーキル(=精度が過剰)な処理を16bit幅へ落とし込むことができるようになる。よって,グラフィックスなどにおいて,見た目をほとんど変えることなく性能を向上させることが可能だと,Mantor氏は述べていた。
AMDはPolarisマクロアーキテクチャ世代でDisplayPort 1.4およびHDMI 2.0に対応したが,Vega世代ではPolaris世代と比べてディスプレイエンジンが新しくなっていることも明らかになった。
4K 60Hzの6画面出力を行える「Eyefinity」に対応するのはPolarisと同じだが,Vegaでは4K 120Hzの2画面出力にも対応する。これは将来出てくると言われる,片目あたり4K解像度のVR対応ヘッドマウントディスプレイ(以下,VR HMD)への対応をも狙ったものになる。
8K 30Hzの3画面出力もサポート。4K 60Hzおよび4K 120Hz出力時には,YUV12bitおよびRGB各16bitのHDR(High Dynamic Range)にも対応する。現時点ではこの機能を活かせるディスプレイデバイスが存在しないほど先端技術をサポートしたわけだが,このあたりは,過去数年,HDMI 2.0の対応でNVIDIAから圧倒的に遅れていたことのの反省を踏まえた反動なのかもしれない。
そのほかRadeon Technologies Groupは,VegaのレジスタシステムがZenマイクロアーキテクチャ開発チームとのコラボレーションで誕生したことや,GPUの仮想化に関連してVCE(Video Coding Engine)やUVD(Unified Video Decoder)も仮想化に対応したこと,Polaris以前のGPUでは高負荷環境においてクロックダウンせざるを得ない場面があったのをVegaで改善したことなどを,新要素として挙げている。
Radeon RX Vegaシリーズはトピックの豊富なGPUである。絶対性能が上がった,AMDとしては久々のハイエンドクラスのGPUでもある。
ただ,競合するNVIDIAのGPUとしては「GeForce GTX 1080」を挙げているなど(関連記事),やや遠慮した印象もあり,従来どおりの,価格対性能比を重視したスタンスとも言えるだろう。
Ryzenシリーズやサーバー向けCPUのEPYCでIntelに対して真っ向勝負を挑んでいるCPU部門は微妙に立ち位置が異なる印象も受けるが,それは,x86/x64アーキテクチャ的に,行き着くところまで到達しつつあるからだろう。言い換えれば性能競争が主戦場だからこそ,CPU部門はそこに注力しているわけだ。
一方のGPUは,良くも悪くもまだ進化の途上にある。誕生して20年も経って,やっとまともに仮想化や仮想メモリの概念が入りだしたくらいなのだから。
その観点からVegaマクロアーキテクチャをあらためて見てみると,長い時間をかけて少しずつ進化してきたGPUアーキテクチャを,ソフトウェア側から使いやすく刷新していこうという,Radeon Technologies Groupのきまじめな姿勢を感じ取ることができる。
「単なる性能競争だけでGPUの進化を終わらせては業界のためにはならない」と考えているのか,「単なる性能競争だとNVIDIAに勝つのは難しい」と考えているのか。そこまでは分からないものの,Vegaに盛り込まれた,
などは,GPU業界が中長期的に進化するため,いずれ誰かが取り組まなければならなかったポイントだったわけで,その点は業界関係者から評価されそうである。
思えばAMDはこれまでも,こうした「みんなのためになるかも」といったことに幾度となく取り組んできた。x86アーキテクチャの互換性を維持しながら64bit化させたx64は,AMDの「AMD64」がベースであり,また,DirectX 11で標準化されたテッセレーションアーキテクチャは,AMDがXbox 360用のGPU「Xenon」用に開発したものがベースになっている。高性能かつ高効率を目指したグラフィックスAPIであるDirectX 12はAMDの「Mantle」がベースで,Vulkanに至ってはほぼMantleそのものだ。
話は少しずれるが、SIGGRAPH 2017で映像制作業界の注目を一身に集めている,オープンソースかつ無料のAMD製レイトレーシングエンジン「Radeon Pro Render」は,OpenCL 1.2ベースで開発されており,なんと“Radeonロック”がかかっていない。そのため,NVIDIA製GPUでも良好な性能を発揮するとのことで,「GeForceの某製品で動かすと,Radeon RX Vegaより速い」なんていう情報が会場中を駆け巡っていたりもした。NVIDIAのレイトレーシングエンジン「OptiX」はCUDAベースで,同社製GPUでしか動作しないことと比較すると,「業界全体の明日」に向かうAMDおよびRadeon Technologies Groupの姿勢というものが感じられよう。
というわけで、今回のRadeon RX Vegaは,「美しい思想」や,「AMDの清貧さ」(※失礼)の具現化という感想を筆者は抱いている。ただ,それと「売れるか」は別問題というのが,市場競争の厳しいところだ。
Radeon RX VegaがGPUの歴史に名を刻むことは間違いなさそうだが、商業的に成功するかどうかは,蓋を開けてみなければ分からない。巨大なGeForce帝国に対する巻き返しはなるのかどうか,期待して見守りたいと思う。
 |
その内容は,1月の時点で明らかになっていた内容と多くの部分で重複していたが,一部,新しい情報も出てきたため,今回はそれらをまとめて紹介したいと思う。
「1月の話ってどんなのだっけ?」という人は,連載バックナンバー「AMD,次世代GPU『Vega』における4つの技術ポイントを公開。HBM2はキャッシュで使う!?」をチェックしてから,あらためて本稿に戻ってきてもらえれば幸いだ。
西川善司の3DGE:AMD,次世代GPU「Vega」における4つの技術ポイントを公開。HBM2はキャッシュで使う!?
ジオメトリパイプラインを刷新。新設の「プリミティブシェーダ」とは何か?
Vega世代では,新しいシェーダステージ「プリミティブシェーダ」(Primitive Shader)を採用することとなった。まずはその話から始めよう。
プリミティブシェーダについては1月のタイミングでも概要は出てきたが,今回明らかになったのは,もう少し具体的な情報だ。個人的には,Radeon Technologies Groupによる今回の発表内容で,最も驚いた部分だったりもする。
 |
DirectXの歴史を少し振り返っておくと,DirectX 9までは以下のような構成だった。
- 頂点シェーダ(Vertex Shader)→ピクセルシェーダ(Pixel Shader)
DirectX 10時代になると,頂点シェーダ側にジオメトリシェーダ(Geometry Shader)が加わって,以下のようになる。
- (頂点シェーダ→ジオメトリシェーダ)→ピクセルシェーダ
そしてDirectX 11時代になると,頂点シェーダとジオメトリシェーダの間にテッセレーションステージ(Tessellation Stage)が加わった。テッセレーションステージは「ハルシェーダ」(Hull Shader)と「テッセレータ」(Tessellator),そして「ドメインシェーダ」(Domain Shader)の3ブロックからなるため,構成としては以下のようになる。
- (頂点シェーダ→(ハルシェーダ→テッセレータ→ドメインシェーダ)→ジオメトリシェーダ)→ピクセルシェーダ
 |
実際,ゲーム開発者の間でも,「テッセレーションステージとジオメトリシェーダは使いにくい。性能が出ない」とされ,いまや「いらない子」扱い。結果として,ちょっと高度なジオメトリ処理を行う場合は,汎用性の高い「コンピュートシェーダ」(Cumpute Shader)でジオメトリパイプラインを“外注”する実装のほうが主流になりつつあるほどである。
プログラマブルシェーダアーキテクチャの進化がDirectX 11を境にしてうまくいかなくなっている背景には,煩雑になりすぎてしまったジオメトリパイプラインがあるという話も,開発者の間ではよく出てくる話題になっている。
 |
今日(こんにち)のグラフィックスでは,レンダリング後段で使用する多様な属性パラメータを頂点カラーなどに割り当てて,それらを頂点シェーダで処理したりすることが多い。しかも,その後に頂点の増減を行うジオメトリシェーダがきて,さらにそれを細分化させるテッセレーションステージがくる。
さらにテッセレータで分割されて増えた頂点はその後,テッセレーションステージにおける頂点シェーダ的な存在のドメインシェーダで処理を受けることになる。つまり,パイプラインの下流へ行けば行くほど,頂点データとそれに付随する属性パラメータの数が増大していく構造になってしまっているのである。
恐ろしいのは,頂点単位(≒ポリゴン単位)のデータ構造をピクセルに分解するラスタライザの段階で,画面に描かれないポリゴンを破棄する「視界外カリング」の対象となったり,ピクセルシェーダでの処理が終わってピクセルを描き出す段階になって,Zバッファ処理によって「視点から見えないピクセル」として破棄されたりするケースがあるということだ。
上流で処理すればするほどデータ量が増えるにもかかわらず,最下流のところで「それ全部いらないです」というちゃぶ台返しを喰らいやすい構造になっているのである。
プリミティブシェーダはこの問題を解決するアイデアなのだが,なぜそうなのかは,下の図を見ながらだと理解しやすいと思う。
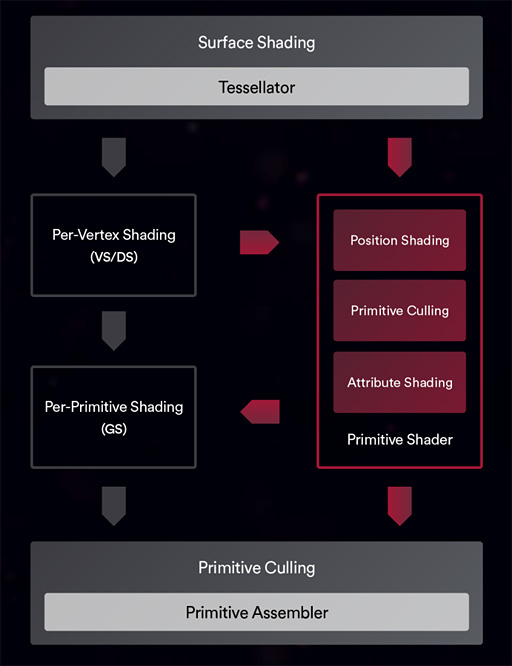 |
まず,機能面で重複する頂点シェーダとドメインシェーダをプリミティブシェーダに統合し,「ポジションシェーディング」(Position Shading)という機能ブロックとして扱う。
ドメインシェーダは「テッセレータ実行後の頂点シェーダ」みたいなものなので,まとめることには合理性がある。
次に,「ジオメトリパイプラインの後段に行けば行くほど,頂点データと,付随する属性パラメータが爆発的に増えていく」ことを防ぐため,ジオメトリパイプラインの上流で早期カリングを行う機能ブロック「プリミティブカリング」(Primitive Culling)を置く。
加えて,複数ビューポートへ向けた投射のような,ジオメトリシェーダが持つ特殊なジオメトリパイプライン機能は,「アトリビュートシェーディング」(Attribute Shading)という機能ブロックが担当する。
以上の3ブロックが,プリミティブシェーダという新シェーダステージを司るプログラマブルシェーダとなるのだ。
しかも,話はこれで終わらない。
従来はジオメトリパイプライン後段に位置し,ジオメトリシェーダと一部機能がダブる部分もあったテッセレーションステージは,最上流に再配置となり,頂点(≒ポリゴン)分割機構であるテッセレータを制御するハルシェーダとともに,「サーフェスシェーディング」(Surface Shading)という機能ブロックとして再構成を果たした。
全体として,従来の「無計画な違法建築」然としていたジオメトリパイプラインが,リフォームされて美しい構造となった印象を受ける。
なお,Vegaの新しいジオメトリパイプラインでは,既存アプリケーションとの互換性を確保する目的から,従来型のジオメトリパイプラインを使うこともできる。なので,既存のDirectX 11やDirectX 12対応アプリケーションを使う限り,プリミティブシェーダの恩恵を受けることはほとんどない。
しかも,今回大刷新を果たしたこの新世代ジオメトリパイプライン,発表こそなされたものの,この後,どのような形で使えるようにするかは未定なのだそうだ。そのため,具体的な実動デモはなかった。
 |
Radeon Technologies Groupは現在,DirectX規格の総元締めであるMicrosoftや,OpenGLおよびVulkanの規格を策定しているKhronos Groupと,新しいジオメトリパイプラインの取り扱いについて協議を進めていく計画だそうだ。
そういうステータスなので,当面の間,新しいジオメトリパイプラインの全機能を開発者に開放するといったことはせず,「既存のアプリケーションを動作させたときに,コンパイラやドライバソフトウェアレベルで新しいジオメトリパイプラインに当てはめて自動的に最適化する」ようなアプローチでの活用を行っていくとのことだった。
思い返してみると,こうしたアプローチは,かつて非プログラマブルシェーダアーキテクチャだったDirectX 7からプログラマブルシェーダアーキテクチャであるDirectX 8&9への移行期にもあった。あの頃は,DirectX 7標準の固定パイプライン機能を,プログラマブルシェーダアーキテクチャで再現した(=エミュレーションした)固定機能パイプラインに流し込むアイデアが実用化されていたのを憶えている読者もいることだろう。
このような自動最適化は,ぴたりとハマったときの効果が大きい一方,そうでない場合は互換性の面で問題を起こしたりするので,諸刃の剣感はある。
AMDはPlayStationやXboxにGPU――正確にはAPUだが――を提供しているので,ひょっとすると次世代PlayStationやXboxにプリミティブシェーダを標準採用させるような青写真を描き,それに向けて動いているという可能性もありそうだ。
より詳細が明らかになった「HBCCの振る舞い」
すでに明らかになっているとおり,Graphics Core Next(以下,GCN)アーキテクチャ世代でVegaマクロアーキテクチャを採用するRadeon RX Vegaは,グラフィックスメモリを「GPUから見たシンプルなローカルメモリ」ではなく,キャッシュメモリとして取り扱うというメモリ仕様を採用している。これは,「数十GBから数TBクラスとなる大きなデータセットを,GPUプログラム側からリニアにアドレッシングしてアクセスできるようにする」ためだ。Radeon RX Vegaの場合,最大512TBという,極めて広大な領域を仮想メモリとして取り扱えるようになっている。
この仮想メモリに対するアクセスを司るのが,旧来的なGPUにおけるメモリコントローラに相当する「High-Bandwidth Cache Controller」(以下,HBCC)である。
 |
 |
Vega世代のグラフィックスカードは,Radeon RX VegaもRadeon Proシリーズも第2世代High Bandwidth Memoryである「HBM2」をキャッシュメモリとして採用している。ではノートPC向けVegaやAPU統合版VegaもHBM2が前提かというと,そういうことでもないという。
Mantor氏いわく「HBCCは,GDDR5などと組み合わせることもできる」。HBM2を組み合わせにくいプラットフォームでは,ほかのメモリを組み合わせて出てくる可能性のほうが高そうである。
HBCCは基本的に自律動作する存在で,利用頻度の高いデータ領域をローカルメモリ(※事実上のグラフィックスメモリで,いま述べたとおり,Radeon RX Vegaの場合はHBM2。以下同)に配置し,そうでもないデータ領域はシステムメモリ(※CPUと共有するメインメモリで,最近のPCならDDR4接続となる。以下同)にスワップアウトしてくれる。もちろん,スワップインも自律動作で対応だ。
これらスワップアウトとスワップインは,「ページサイズ単位」(Mantor)氏とのこと。となると当然,ページサイズがいくつなのかが気になるところだが,氏の口からは「ページサイズは可変」以上の回答は得られず。もっとも,会場で別のGPUエンジニアに話を聞いてみたところ,「ページサイズは64KBが基本」と教えてもらえたので,その点は付記しておきたい。
 |
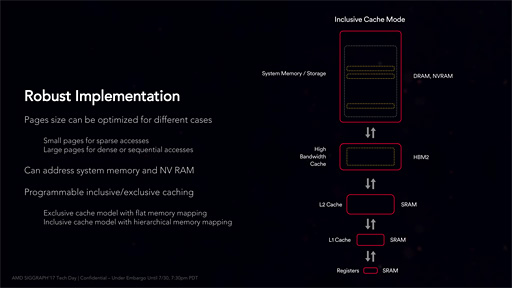
また,キャッシュメモリの取り扱い法としてはInclusive(インクルーシブ,包括)モードととExclusive(エクスクルーシブ,排他)モードがあり,プログラマブルに切り換えられるとのことだ。
InclusiveとExclusiveの両モードはCPUキャッシュメモリでお馴染みと思われるが,念のため説明しておこう。
Inclusiveモードはローカルメモリとシステムメモリとでデータが“ダブる”モードだ。つまり,ローカルメモリにスワップインさせても,システムメモリ上には同じものが残る管理の仕方だ。
 |
対してExclusiveモードは,ローカルメモリにシステムメモリからスワップインさせるとき,システムメモリ上のデータ領域を開放してしまう。
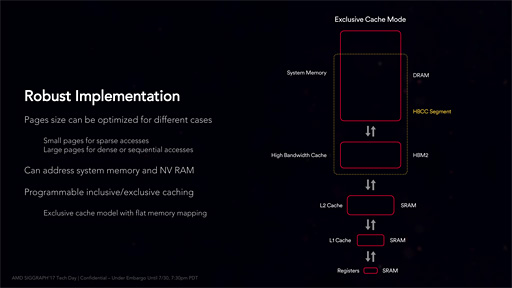 |
メモリ利用効率だけ見れば,Exclusiveモードのほうが優秀なのは言うまでもない。Inclusiveモードは冗長性があるものの,データ領域の出し入れ(=スワップアウトおよびスワップイン)を行うときのバス帯域消費や遅延を小さくできるメリットがある。端的に言えばInclusiveモードのほうが速い。
リアルタイム性能が要求されるゲームグラフィックスなどではInclusiveモードが有望である一方,機械学習型AIやオフラインレンダリングのような大規模データセットを取り扱う用途ではExclusiveモードのほうが相性はよかったりもするので,プログラマブルに切り換えられるようになっているわけである。
なお,これらスワップインおよびスワップアウト制御の対象は,システムメモリだけではなく,カード上に容量2TBのNVRAM(≒SSD)を搭載する「Radeon Pro SSG」に対しても透過的に行えるというのがRadeon Technologies Groupの説明だった。ただし,サードパーティのアプリケーション開発者に話を聞いたところ,現状のRadeon Pro SSG用APIだと,容量2TBのNVRAM領域は,GPUプログラム側で管理する設計になっているとのことである。
つまり,このあたりは,ハードウェアアーキテクチャとソフトウェアアーキテクチャ(=API設計)とで一貫性がまだ成立し切っていない可能性が高い。Radeon Technologies Groupとしては,もう少し時間をかけてHBCC周りを成熟させていく計画なのだろう。
新世代Compute Unitは命令セットが一新
GCNアーキテクチャを採用するGPUでは,1クロックあたり16個の32bit単精度浮動小数点(FP32)の積和算を行えるSIMD-16ベクトル演算器を4個ひとかたまりにして,これを1つの単位演算ユニットたる「Compute Unit」として扱っている。
1月の時点で筆者は,VegaのCompute Unitが半精度浮動小数点(以下,FP16)と8bit整数(以下,INT8)の「Packed実行」に対応することをお伝え済みだが,今回は,Radeon Technologies Groupが「Next-Generation Compute Unit」と呼ぶ新世代Compute Unitについて,さらに突っ込んだ話を聞くことができた。
 |
Vegaより前の世代のGPUだと,FP16は,「FP32と比べてサイズが半分だから,レジスタの使用量をFP32比で半分にできる」くらいのメリットしかなかった。それがVegaでは,演算実行効率がFP32時の2倍になる。また,演算精度は「IEEE 754-2008」準拠となり,演算精度の信頼性や,異なるプラットフォームとの間におけるソフトウェア互換性も担保されることとなった。
 |
ゲームエンジンにしろグラフィックスレンダラーにしろ,取り扱う処理内容によってFP16ないしFP32のどちらかを基準にして設計することが多い。というかそもそも,「FP16とFP32を自在に型変換して取り扱う」という発想が,GPUプログラミングにおいては一般的ではなかった。そのため,FP16を効果的に取り扱えるようにするためにはFP16とFP32との間で,柔軟かつ自由度の高い相互型変換が重要になってくる。そこでRadeon Technologies Groupは,そのあたりの命令セットも充実させたという。
「テクスチャユニットのサンプラー(=アクセス機構)は,読み書き対象が32bit幅であっても,16bit幅のPackedでシームレスにアクセスできるようになっている」(Mantor氏)と言うから徹底している。さらに積和算など,利用頻度の高い一部の命令では,FP16とFP32の型混在で直接実行できる柔軟性も取り入れてあるそうだ。
なお,一連の拡張はFP16だけでなく,16bit整数(Int16)でも利用可能とのことである。
 |
この拡張により,32bit幅ではオーバーキル(=精度が過剰)な処理を16bit幅へ落とし込むことができるようになる。よって,グラフィックスなどにおいて,見た目をほとんど変えることなく性能を向上させることが可能だと,Mantor氏は述べていた。
 |
 |
 |
4K 120Hzの2画面出力に対応し,片目あたり4K解像度のVR HMDにも対応
AMDはPolarisマクロアーキテクチャ世代でDisplayPort 1.4およびHDMI 2.0に対応したが,Vega世代ではPolaris世代と比べてディスプレイエンジンが新しくなっていることも明らかになった。
4K 60Hzの6画面出力を行える「Eyefinity」に対応するのはPolarisと同じだが,Vegaでは4K 120Hzの2画面出力にも対応する。これは将来出てくると言われる,片目あたり4K解像度のVR対応ヘッドマウントディスプレイ(以下,VR HMD)への対応をも狙ったものになる。
8K 30Hzの3画面出力もサポート。4K 60Hzおよび4K 120Hz出力時には,YUV12bitおよびRGB各16bitのHDR(High Dynamic Range)にも対応する。現時点ではこの機能を活かせるディスプレイデバイスが存在しないほど先端技術をサポートしたわけだが,このあたりは,過去数年,HDMI 2.0の対応でNVIDIAから圧倒的に遅れていたことのの反省を踏まえた反動なのかもしれない。
 |
 |
 |
 |
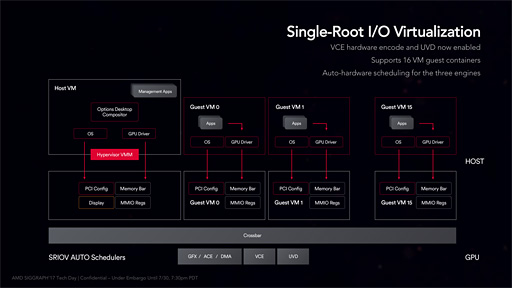
 「Draw Stream Binning Rasterizer」(DSBR)の説明にアップデートはなかった |
 最新の省電力設計を採用したというアピール。詳細は明らかになっていない |
Radeon RX Vegaはどこへ行くのか
Radeon RX Vegaシリーズはトピックの豊富なGPUである。絶対性能が上がった,AMDとしては久々のハイエンドクラスのGPUでもある。
ただ,競合するNVIDIAのGPUとしては「GeForce GTX 1080」を挙げているなど(関連記事),やや遠慮した印象もあり,従来どおりの,価格対性能比を重視したスタンスとも言えるだろう。
Ryzenシリーズやサーバー向けCPUのEPYCでIntelに対して真っ向勝負を挑んでいるCPU部門は微妙に立ち位置が異なる印象も受けるが,それは,x86/x64アーキテクチャ的に,行き着くところまで到達しつつあるからだろう。言い換えれば性能競争が主戦場だからこそ,CPU部門はそこに注力しているわけだ。
一方のGPUは,良くも悪くもまだ進化の途上にある。誕生して20年も経って,やっとまともに仮想化や仮想メモリの概念が入りだしたくらいなのだから。
 |
「単なる性能競争だけでGPUの進化を終わらせては業界のためにはならない」と考えているのか,「単なる性能競争だとNVIDIAに勝つのは難しい」と考えているのか。そこまでは分からないものの,Vegaに盛り込まれた,
- ジオメトリパイプラインの整理整頓
- HBCCをベースにした仮想メモリアーキテクチャへの対応
などは,GPU業界が中長期的に進化するため,いずれ誰かが取り組まなければならなかったポイントだったわけで,その点は業界関係者から評価されそうである。
思えばAMDはこれまでも,こうした「みんなのためになるかも」といったことに幾度となく取り組んできた。x86アーキテクチャの互換性を維持しながら64bit化させたx64は,AMDの「AMD64」がベースであり,また,DirectX 11で標準化されたテッセレーションアーキテクチャは,AMDがXbox 360用のGPU「Xenon」用に開発したものがベースになっている。高性能かつ高効率を目指したグラフィックスAPIであるDirectX 12はAMDの「Mantle」がベースで,Vulkanに至ってはほぼMantleそのものだ。
話は少しずれるが、SIGGRAPH 2017で映像制作業界の注目を一身に集めている,オープンソースかつ無料のAMD製レイトレーシングエンジン「Radeon Pro Render」は,OpenCL 1.2ベースで開発されており,なんと“Radeonロック”がかかっていない。そのため,NVIDIA製GPUでも良好な性能を発揮するとのことで,「GeForceの某製品で動かすと,Radeon RX Vegaより速い」なんていう情報が会場中を駆け巡っていたりもした。NVIDIAのレイトレーシングエンジン「OptiX」はCUDAベースで,同社製GPUでしか動作しないことと比較すると,「業界全体の明日」に向かうAMDおよびRadeon Technologies Groupの姿勢というものが感じられよう。
というわけで、今回のRadeon RX Vegaは,「美しい思想」や,「AMDの清貧さ」(※失礼)の具現化という感想を筆者は抱いている。ただ,それと「売れるか」は別問題というのが,市場競争の厳しいところだ。
Radeon RX VegaがGPUの歴史に名を刻むことは間違いなさそうだが、商業的に成功するかどうかは,蓋を開けてみなければ分からない。巨大なGeForce帝国に対する巻き返しはなるのかどうか,期待して見守りたいと思う。
Radeon公式Webサイト(英語)
- 関連タイトル:
 Radeon RX Vega
Radeon RX Vega - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー