















ニュース
英Imagination,レイトレ対応GPU「PowerVR Wizard」の実動チップによるリアルタイムデモを世界初公開
モバイル向けGPU IPコアであるPowerVRシリーズで知られる英Imagination Technologies(以下,Imagination)は,毎年,駐日英国大使館にて,ごく限られた招待客を対象に,同社の最新技術を先行公開するイベントを実施している。去る11月16日に,2015年のイベントが行われたのだが,その中に注目すべき展示があった。
それは,2014年3月にレイトレーシング対応のGPU IPコアとして発表された「PowerVR Wizard」こと,「PowerVR GR6500」(以下,GR6500)の実動チップによる世界初公開のデモだ。そこで本稿では,会場で披露されたデモの概要と,GR6500の特徴をレポートしたい。
PowerVR Wizardについては,4Gamerでは何度かレポートしているのだが,改めてどういう存在なのかを簡単に説明しておこう。
Imaginationは,2010年12月にレイトレーシング用プロセッサを開発するベンチャー企業であったCaustic Graphicsを買収し,レイトレーシングをハードウェアアクセラレーションする技術を,新世代のGPUコアに統合する戦略を発表した。
2011年には「Caustics Two」と呼ばれるレイトレーシングユニット(RTU)の開発を表明しており,2013年には,PCI Express x8接続のPC用拡張カードであるR2000シリーズとして,プロフェッショナルユーザー向けに製品化を実現した。
そして2014年には,このRTU技術をPowerVRに統合する,PowerVR Wizardシリーズの開発を発表した。その第1弾となるGPU IPコア製品が,GR6500というわけだ。
GR6500シリーズは,PowerVR Series6シリーズ(以下,PowerVR6)の上位モデルである「PowerVR Series6XT」に,RTUを統合したGPUである。
GR6500は,実のところGPU IPコア製品としては,2014年3月に発表済みの製品だ。ただ,RTUの最適化されたサンプルチップはこれまで存在しておらず,2014年3月の「GDC 2014」で公開されたデモ(関連記事)も,実際にはロジックが動作することを証明するためにFPGAを使って作られた暫定版的なものだったのである。
だが,今回,Imaginationが公開したものは,今までの暫定版とは違う。Po
会場にいたImaginationのスタッフに話を聞いたところ,デモに使われたのはCPUコアが載ったSoC(System-on-a-Chip)ではなく,単体GPUの形態であり,これがPCI-Expressバス接続の拡張カードに搭載されている構成だそうだ。
残念ながら,GPU自体の写真撮影は許可されず,詳細なスペックについても公表されなかった。今回,デモに使われた拡張カードは,そのまま市販されることはなく,開発者向けに提供されるGR6500開発キットの一部になるようだ。
とはいえ,FPGAによる暫定版ではなく,フルカスタムロジックのチップとしてGR6500が製造されたことのインパクトは大きい。近い将来,どこかのSoCメーカーから,GR6500を搭載したSoCが登場してくる可能性は高そうだ。
今回のデモに使われたテスト基板上のGR6500は,4クラスタ構成(4 USC)のPowerVR6コアにRTUを統合したものである。
USCとは「Unified Shading Cluster」の略で,1基のUSCは,16本のパイプラインで構成されている。16本のパイプラインは,最大で16要素の32bit浮動小数点演算を行えるのだが,16bit浮動小数点形式ならば,スループットを倍増できるのが,PowerVR6系GPUの特徴だ。SIMDベースの演算機であれば,データ長が半分になればスループットが倍になっても不思議ではないのだが,実はPowerVR6はスカラー式の演算機を使用している。
PowerVR5までは,SIMDベースの演算ユニットで構成されていたが,PowerVR6からは,複数のスカラー演算ユニットで構成されるようになった。これは,NVIDIAのGPUがCUDAベース,AMDのGPUがGCNベースになったときに行われたアーキテクチャ変更と同じものだ。理由は当然,GPGPUへの対応のためである。つまり,USCとは,NVIDIA GPUにおける「Streaming Multiprocessor」(SM)のようなものと理解しておけばいいだろう。そして,PowerVR6では,スカラー演算でFP16性能を上げるために,FP16 ALUを2倍詰め込んだ仕様になっている。
ちなみに,PowerVR6は,GPU IPコアを購入する顧客企業の要望に応じて,USCを複数実装することが可能だ。Imaginationによれば「公開したデモを動かしているUSCが4基のGR6500は,ミッドレンジ向けのスマートフォンやタブレットでの搭載を想定したものとして見てほしい」とのことであった。
会場では,GR6500による3種類のデモが公開されていた。ビデオを交えて説明していこう。
まずは,GR6500搭載カードを装着したPCによるリアルタイムレイトレーシングデモだ。
1つめのビデオでは,ティーポットや球体,幾何学的な多面体や曲面立体で構成された比較的シンプル――300万ポリゴン程度――なシーンをフルレイトレーシングで描画する様子を撮影している。デモ映像の解像度は1280×720ドットで,30fps前後のフレームレートが出ているとのこと。
ビデオ中で確認できるライティング効果はもちろんのこと,間接光効果や映り込み,影のすべてがレイトレーシングの結果として自動的に得られているものだ。

次のビデオは,600万ポリゴン程度で作られたロボットがベンチでくつろいでいるシーンを,カメラレンズの光学シミュレーション付きで1920×1080ドットにて描画した様子である。こちらは,さすがに負荷が高いので,フレームレートも3fps前後まで落ちていたが,CPUで同シーンを描画させたときの100倍は高速だとのこと。
被写界深度のピンボケ効果は,レイトレーシングの結果として自動的に得られるものであり,現在のゲームグラフィックスで行っているような,別処理によるポストエフェクトを行う必要はない。レンダリングパイプラインとしては,こちらのほうがシンプルではあるのだ。

2つめのデモは,お馴染みのゲームエンジン「Unity」で構築したテストシーンを,一般的なラスタライズベースのレンダラーによって3Dオブジェクトをレンダリングしながら,影生成と映り込み表現だけをレイトレーシングで描画するという「ハイブリッドレンダリング」のデモだ。
ポリゴン数は不明だが,多面体のデモよりもポリゴン数は多めで,シーン構成もより複雑であるにも関わらず,解像度1920×1080ドットでフレームレートは30fps程度出ているという。

このデモは,通常のラスタライズベースのレンダリングとレイトレーシングを適材適所的に使い分ける実装例で,「ゲームグラフィックスの未来像」ともいうべき描画スタイルである。
3つめのデモは,GR6500を複数台使ったマルチGPU動作におけるリニアな性能向上をアピールするためのものだ。このデモに使用したPCは,GR6500カードを4枚も搭載しているという。
デモ自体は,約30億ポリゴンの超多ポリゴンのテストシーンをフルレイトレーシングで描画するというもので,アウディのスポーツカー「R8」を,外装から内装まで精密に再現したモデルを複数台配置し,カメラ(視点)が車内から外までを動き回るという内容だった。なお,車や周囲のオブジェクトは動かず,動くのはカメラだけだ。
シーン全体の総ポリゴン数が30億ポリゴンとはいえ,実際の描画ポリゴン数はそれよりも低い可能性はある。それでも,GR6500を4基も使っただけあって,解像度1920×1080ドットのフルレイトレーシングで描画しても,30fps程度のフレームレートが出ているそうだ。

今回のデモで使われたGR6500は,動作クロックといったスペックの詳細が公開されていない。ただ,毎秒3億レイを飛ばすことができる性能があるという。この値は,2014年に発表されたスペックと変わっていないので,当時の発表どおりなら,動作クロックは600MHzということになる(関連記事)。
光源から放射されたレイは,シーン内の探索(ノードテストと呼ぶ)を毎秒240億回も行え,毎秒1億ポリゴンとの交差判定を処理できるという。
そこで,30fpsでの映像描画を目標とすると,1フレームあたりに飛ばせるレイの数は1000万本程度になり,解像度1280×720ドット(約92万ドット)で描画した場合,1ドットあたりに飛ばせるレイの数は10本強という計算になる。同じ解像度で60fpsに引き上げると,レイの数は1ドットあたり5本,解像度1920×1080ドットでは2.5本という計算になる。
GR6500が1基でこの性能なので,GR6500の数を増やしていけば,性能の理論値もその数だけリニアに向上するはずだ。ただ,仮にGR6500×2の構成にしたとしても,現状の性能でゲームグラフィックス用途に使うには,映り込みや影生成にレイトレーシングを活用するハイブリッドレンダリングが現実的なところではないだろうか。
とはいえ,CPUによるレイトレーシングに比べれば,数百倍は高速化できることは間違いなく,映像制作分野への訴求力はかなり高いかもしれない。
なお,今回実演されたGR6500カードは,専用のメモリを1GB搭載しているとのことだった。このカードは,スマートフォンやタブレットを開発する開発者向けのテスト用に使われることを想定していることもあり,グラフィックスメモリとして一般的なGDDR5メモリは使っていない。逆にいえば,GDDR5を使ったデスクトップPC向けの製品が実現できれば,さらにレンダリング性能を引き上げることも可能だろう。
話は変わるが,Caustic Graphics時代からRTUのことをウオッチしていた人の中には,2013年に登場したR2000シリーズと,GR6500は何が違うのか気になっているかもしれない。
実のところ,R2000シリーズが担当していたのは「シーン内でレイを飛ばすこと」と「シーン内のオブジェクトの交差判定」だけで,ドット単位のライティング計算やシェーディング計算は,CPUで行っていたのである。
それに対してGR6500では,R2000シリーズ相当の処理系,すなわちRTU部分がGPUコアに統合されているので,ドット単位のライティング計算やシェーディング計算をUSCで処理できるようになった。この設計によって,GR6500はR2000シリーズよりも,各段に高速化されたわけだ。
もう1つ,GR6500で疑問となるのは,「RTUをどうやってプログラムで活用すればいいのか」という点である。
Imaginationは,RTU構想を発表するのとほぼ同時に,プログラマブルレイトレーシングAPIとして「OpenRL」というAPIを提唱した(関連記事)。そうなると,OpenRLを使ってプログラミングするのかと思うかもしれないが,実は違う。Imaginationとしては,事実上,独自規格の構想どまりとなっているOpenRLの活用を強要するのは得策ではないと考えたのか,APIについては随分と柔軟な戦略を打ち出してきたのだ。
Imaginationによると,当面RTUは,OpenGL ES 3.2のExtension(※拡張API)経由で利用してもらうことに決定したとのこと。追って,新世代のAPIである「Vulkan」からもRTUが使える仕組みを提供しつつ,OpenRLでの環境も整備していくのだそうだ。

ところで,今回のデモは「Resin」と称するImagination製のレイトレーサーを使用しているとのことだった。筆者が関係者を取材した範囲では,これを社外向けに提供するかどうかは決めかねているそうだ。Imaginationとしては,自社でレイトレーサーまで提供するのではなく,グラフィックス関連ソフトウェアメーカーが,OpenGL ES 3.2 ExtensionやVulkanを活用して独自のレイトレーサーを開発することで,RTUを活用するエコシステムを拡張していく方向が望ましいと考えているようだ。
そうはいっても,NVIDIAが独自のレイトレーサーである「OptiX」を開発し,これが業界に認知された結果,あのPixarに採用されるようになった例もあるので(関連記事),Imaginationも自前のレイトレーサーを提供する必要があるのではないかと,筆者は考えるのだが。
RTUは,レイトレーシング用途はもちろんのこと,シーン内探索や交差判定処理などは,経路探索を初めとしたAI開発用途や物理シミュレーションなどにも役立てられるといわれている。Imaginationの取り組み次第では,GPU業界に新しいムーブメントを引き起こす可能性もある。
ImaginationのRTU戦略と,GPU業界のレイトレーシングに対する動向には,今後も注目していく必要がありそうだ。
それは,2014年3月にレイトレーシング対応のGPU IPコアとして発表された「PowerVR Wizard」こと,「PowerVR GR6500」(以下,GR6500)の実動チップによる世界初公開のデモだ。そこで本稿では,会場で披露されたデモの概要と,GR6500の特徴をレポートしたい。
 |
 |
ついに実動するカスタムチップが製造されたPowerVR Wizard
PowerVR Wizardについては,4Gamerでは何度かレポートしているのだが,改めてどういう存在なのかを簡単に説明しておこう。
 |
2011年には「Caustics Two」と呼ばれるレイトレーシングユニット(RTU)の開発を表明しており,2013年には,PCI Express x8接続のPC用拡張カードであるR2000シリーズとして,プロフェッショナルユーザー向けに製品化を実現した。
そして2014年には,このRTU技術をPowerVRに統合する,PowerVR Wizardシリーズの開発を発表した。その第1弾となるGPU IPコア製品が,GR6500というわけだ。
GR6500シリーズは,PowerVR Series6シリーズ(以下,PowerVR6)の上位モデルである「PowerVR Series6XT」に,RTUを統合したGPUである。
GR6500は,実のところGPU IPコア製品としては,2014年3月に発表済みの製品だ。ただ,RTUの最適化されたサンプルチップはこれまで存在しておらず,2014年3月の「GDC 2014」で公開されたデモ(関連記事)も,実際にはロジックが動作することを証明するためにFPGAを使って作られた暫定版的なものだったのである。
 |
だが,今回,Imaginationが公開したものは,今までの暫定版とは違う。Po
会場にいたImaginationのスタッフに話を聞いたところ,デモに使われたのはCPUコアが載ったSoC(System-on-a-Chip)ではなく,単体GPUの形態であり,これがPCI-Expressバス接続の拡張カードに搭載されている構成だそうだ。
残念ながら,GPU自体の写真撮影は許可されず,詳細なスペックについても公表されなかった。今回,デモに使われた拡張カードは,そのまま市販されることはなく,開発者向けに提供されるGR6500開発キットの一部になるようだ。
とはいえ,FPGAによる暫定版ではなく,フルカスタムロジックのチップとしてGR6500が製造されたことのインパクトは大きい。近い将来,どこかのSoCメーカーから,GR6500を搭載したSoCが登場してくる可能性は高そうだ。
GR6500は,4クラスタ構成のPowerVR6コアにRTUを統合
今回のデモに使われたテスト基板上のGR6500は,4クラスタ構成(4 USC)のPowerVR6コアにRTUを統合したものである。
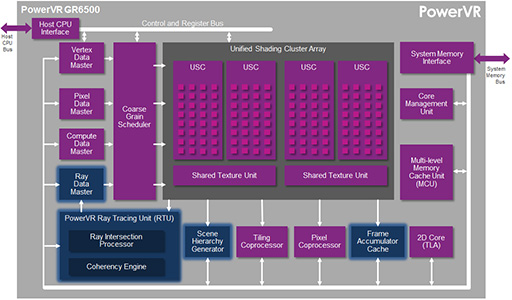 |
USCとは「Unified Shading Cluster」の略で,1基のUSCは,16本のパイプラインで構成されている。16本のパイプラインは,最大で16要素の32bit浮動小数点演算を行えるのだが,16bit浮動小数点形式ならば,スループットを倍増できるのが,PowerVR6系GPUの特徴だ。SIMDベースの演算機であれば,データ長が半分になればスループットが倍になっても不思議ではないのだが,実はPowerVR6はスカラー式の演算機を使用している。
PowerVR5までは,SIMDベースの演算ユニットで構成されていたが,PowerVR6からは,複数のスカラー演算ユニットで構成されるようになった。これは,NVIDIAのGPUがCUDAベース,AMDのGPUがGCNベースになったときに行われたアーキテクチャ変更と同じものだ。理由は当然,GPGPUへの対応のためである。つまり,USCとは,NVIDIA GPUにおける「Streaming Multiprocessor」(SM)のようなものと理解しておけばいいだろう。そして,PowerVR6では,スカラー演算でFP16性能を上げるために,FP16 ALUを2倍詰め込んだ仕様になっている。
ちなみに,PowerVR6は,GPU IPコアを購入する顧客企業の要望に応じて,USCを複数実装することが可能だ。Imaginationによれば「公開したデモを動かしているUSCが4基のGR6500は,ミッドレンジ向けのスマートフォンやタブレットでの搭載を想定したものとして見てほしい」とのことであった。
世界初公開となった実動シリコンによる実動デモ
会場では,GR6500による3種類のデモが公開されていた。ビデオを交えて説明していこう。
まずは,GR6500搭載カードを装着したPCによるリアルタイムレイトレーシングデモだ。
1つめのビデオでは,ティーポットや球体,幾何学的な多面体や曲面立体で構成された比較的シンプル――300万ポリゴン程度――なシーンをフルレイトレーシングで描画する様子を撮影している。デモ映像の解像度は1280×720ドットで,30fps前後のフレームレートが出ているとのこと。
ビデオ中で確認できるライティング効果はもちろんのこと,間接光効果や映り込み,影のすべてがレイトレーシングの結果として自動的に得られているものだ。
次のビデオは,600万ポリゴン程度で作られたロボットがベンチでくつろいでいるシーンを,カメラレンズの光学シミュレーション付きで1920×1080ドットにて描画した様子である。こちらは,さすがに負荷が高いので,フレームレートも3fps前後まで落ちていたが,CPUで同シーンを描画させたときの100倍は高速だとのこと。
被写界深度のピンボケ効果は,レイトレーシングの結果として自動的に得られるものであり,現在のゲームグラフィックスで行っているような,別処理によるポストエフェクトを行う必要はない。レンダリングパイプラインとしては,こちらのほうがシンプルではあるのだ。
 |
 |
2つめのデモは,お馴染みのゲームエンジン「Unity」で構築したテストシーンを,一般的なラスタライズベースのレンダラーによって3Dオブジェクトをレンダリングしながら,影生成と映り込み表現だけをレイトレーシングで描画するという「ハイブリッドレンダリング」のデモだ。
ポリゴン数は不明だが,多面体のデモよりもポリゴン数は多めで,シーン構成もより複雑であるにも関わらず,解像度1920×1080ドットでフレームレートは30fps程度出ているという。
このデモは,通常のラスタライズベースのレンダリングとレイトレーシングを適材適所的に使い分ける実装例で,「ゲームグラフィックスの未来像」ともいうべき描画スタイルである。
 |
 |
3つめのデモは,GR6500を複数台使ったマルチGPU動作におけるリニアな性能向上をアピールするためのものだ。このデモに使用したPCは,GR6500カードを4枚も搭載しているという。
 |
シーン全体の総ポリゴン数が30億ポリゴンとはいえ,実際の描画ポリゴン数はそれよりも低い可能性はある。それでも,GR6500を4基も使っただけあって,解像度1920×1080ドットのフルレイトレーシングで描画しても,30fps程度のフレームレートが出ているそうだ。
GR6500の描画性能はどれくらいなのか?
今回のデモで使われたGR6500は,動作クロックといったスペックの詳細が公開されていない。ただ,毎秒3億レイを飛ばすことができる性能があるという。この値は,2014年に発表されたスペックと変わっていないので,当時の発表どおりなら,動作クロックは600MHzということになる(関連記事)。
光源から放射されたレイは,シーン内の探索(ノードテストと呼ぶ)を毎秒240億回も行え,毎秒1億ポリゴンとの交差判定を処理できるという。
そこで,30fpsでの映像描画を目標とすると,1フレームあたりに飛ばせるレイの数は1000万本程度になり,解像度1280×720ドット(約92万ドット)で描画した場合,1ドットあたりに飛ばせるレイの数は10本強という計算になる。同じ解像度で60fpsに引き上げると,レイの数は1ドットあたり5本,解像度1920×1080ドットでは2.5本という計算になる。
GR6500が1基でこの性能なので,GR6500の数を増やしていけば,性能の理論値もその数だけリニアに向上するはずだ。ただ,仮にGR6500×2の構成にしたとしても,現状の性能でゲームグラフィックス用途に使うには,映り込みや影生成にレイトレーシングを活用するハイブリッドレンダリングが現実的なところではないだろうか。
 |
 |
とはいえ,CPUによるレイトレーシングに比べれば,数百倍は高速化できることは間違いなく,映像制作分野への訴求力はかなり高いかもしれない。
なお,今回実演されたGR6500カードは,専用のメモリを1GB搭載しているとのことだった。このカードは,スマートフォンやタブレットを開発する開発者向けのテスト用に使われることを想定していることもあり,グラフィックスメモリとして一般的なGDDR5メモリは使っていない。逆にいえば,GDDR5を使ったデスクトップPC向けの製品が実現できれば,さらにレンダリング性能を引き上げることも可能だろう。
GR6500についての疑問と課題
将来的にはVulkanによるプログラミングに対応
話は変わるが,Caustic Graphics時代からRTUのことをウオッチしていた人の中には,2013年に登場したR2000シリーズと,GR6500は何が違うのか気になっているかもしれない。
実のところ,R2000シリーズが担当していたのは「シーン内でレイを飛ばすこと」と「シーン内のオブジェクトの交差判定」だけで,ドット単位のライティング計算やシェーディング計算は,CPUで行っていたのである。
それに対してGR6500では,R2000シリーズ相当の処理系,すなわちRTU部分がGPUコアに統合されているので,ドット単位のライティング計算やシェーディング計算をUSCで処理できるようになった。この設計によって,GR6500はR2000シリーズよりも,各段に高速化されたわけだ。
 |
もう1つ,GR6500で疑問となるのは,「RTUをどうやってプログラムで活用すればいいのか」という点である。
Imaginationは,RTU構想を発表するのとほぼ同時に,プログラマブルレイトレーシングAPIとして「OpenRL」というAPIを提唱した(関連記事)。そうなると,OpenRLを使ってプログラミングするのかと思うかもしれないが,実は違う。Imaginationとしては,事実上,独自規格の構想どまりとなっているOpenRLの活用を強要するのは得策ではないと考えたのか,APIについては随分と柔軟な戦略を打ち出してきたのだ。
Imaginationによると,当面RTUは,OpenGL ES 3.2のExtension(※拡張API)経由で利用してもらうことに決定したとのこと。追って,新世代のAPIである「Vulkan」からもRTUが使える仕組みを提供しつつ,OpenRLでの環境も整備していくのだそうだ。
ところで,今回のデモは「Resin」と称するImagination製のレイトレーサーを使用しているとのことだった。筆者が関係者を取材した範囲では,これを社外向けに提供するかどうかは決めかねているそうだ。Imaginationとしては,自社でレイトレーサーまで提供するのではなく,グラフィックス関連ソフトウェアメーカーが,OpenGL ES 3.2 ExtensionやVulkanを活用して独自のレイトレーサーを開発することで,RTUを活用するエコシステムを拡張していく方向が望ましいと考えているようだ。
そうはいっても,NVIDIAが独自のレイトレーサーである「OptiX」を開発し,これが業界に認知された結果,あのPixarに採用されるようになった例もあるので(関連記事),Imaginationも自前のレイトレーサーを提供する必要があるのではないかと,筆者は考えるのだが。
RTUは,レイトレーシング用途はもちろんのこと,シーン内探索や交差判定処理などは,経路探索を初めとしたAI開発用途や物理シミュレーションなどにも役立てられるといわれている。Imaginationの取り組み次第では,GPU業界に新しいムーブメントを引き起こす可能性もある。
ImaginationのRTU戦略と,GPU業界のレイトレーシングに対する動向には,今後も注目していく必要がありそうだ。
Imagination Technologies 公式Webサイト
- 関連タイトル:
 PowerVR
PowerVR - この記事のURL:
(C)2011 Imagination Technologies Ltd. All rights reserved
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー