NVIDIAの独自CPU開発計画
「Project Denver」(プロジェクトデンバー)は,来たるヘテロジニアスコンピューティング時代において,GPU側からコンピューティング性能を引き上げるには欠かせない存在だ。
もともとProject Denverは,今から約3年半前に,GPUの並列演算処理性能を向上させるために,GPU内部のスケジューリングや命令発行を制御する,より強力なプロセッサが必要だとして始まったとされる。
だが,「Windows 8」という開発コードネームで呼ばれる次期Windows(以下,Windows 8)のARMアーキテクチャ対応によって,状況は大きく変わってきた。今回はNVIDIAのGPUコンピューティングへ向けた取り組みと,今後のCPU開発について整理してみよう。
限界にさしかかったCPUの性能向上
馬路 徹氏(エヌビディア ジャパン シニア ソリューション アーキテクト)
 |
2011年7月下旬に東京・六本木で開催された
「GTC Workshop Japan 2011」では,NVIDIAの馬路 徹氏が「GPUアーキテクチャおよびGPUコンピューティング入門」と題して,現在のCPUが抱える問題点と,GPUコンピューティングの現状を説明した。
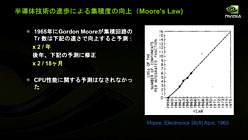
そこでまず馬路氏が述べたのは,18か月で2倍のトランジスタ集積度を実現するという「ムーアの法則」の恩恵を受け,CPUが順調に性能を伸ばしてきたのは2000年までだった,という話だ。
氏によると,2000年までの間,
- プロセス技術の進化に伴うトランジスタ速度向上:19%
- パイプラインーF/F(フリップ・フロップ,入力信号“0”または“1”を一時的に保持する論理回路)間の論理ゲート数削減:9%
- マイクロアーキテクチャの改良:18%
によって,実行性能は,
1.19×1.08×1.18=1.52
と,毎年52%の性能向上を果たしてきたのこと。しかし2000年以降,とくにCPUのマルチコア化が加速された2005年以降は,複数のプロセッサによる並列コンピューティング性能の向上度合いに関する法則として注目されている
「アムダールの法則」(Amdahl's Law,Gene Amdahl氏が提唱したことからそう呼ばれる)が壁として立ちはだかっているという。
半導体技術の指標とされるムーアの法則は,CPU性能の向上を示すのではなく,あくまでもトランジスタ集積度の向上を示すものだ(左)。馬路氏は,「2000年まで,CPU業界はこのムーアの法則を実行性能の向上に当てていた」と述べている(右)
 |
 |
コア数を増やしつづけても,それに比例した性能向上は望めないとする「アムダールの法則」
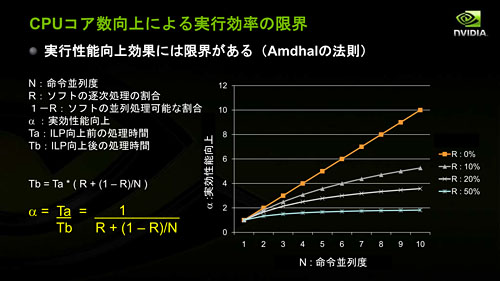 |
アムダールの法則では,「演算処理の並列度を高めるためにCPUのコア数を増やしても,アプリケーションで並列処理できない部分があった場合,その比率(≒ソフトの逐次処理の割合)の大きさによっては,マルチコア化に比例した実効性能の向上は望めない」とされる。馬路氏は,マルチコアCPUに最適化されていないアプリケーションだと,逐次処理の割合が20〜50%に達するとし,「8コアCPUをもってしても,実効性能向上幅はシングルコア比の4倍に満たないのが現状で,2000年以降,CPUの性能向上速度は年19%にまで鈍化している」と指摘する。
2000年以降,CPUベンダーはムーアの法則をコア数の増大に充ててきたが(左),マルチコア化に伴い,CPUの性能向上のペースは大幅に低下したという(右)
 |
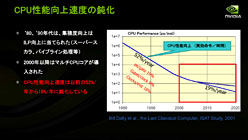 |
マイクロアーキテクチャの改良によりCPUの並列処理性能は高められるが,それにも限界はある
 |
もちろん,CPUベンダーはアムダールの法則を十分に理解している。もともとCPUは逐次処理に適したアーキテクチャが採用されており,IntelがMMXやSSE,AVXといったSIMD(Single Instruction Multiple Data)演算機能を強化してきたのも,並列処理性能をアーキテクチャレベルで引き上げるためだ。またIntelが,アプリケーションソフトのマルチコア最適化を推奨し,自社のプログラミングツールなどを訴求しているのも,並列処理性能向上を目的としたものである。
ただ,それにも限界はあり,結果として,スーパーコンピューティングの世界では,並列演算性能を追求したアーキテクチャになっているGPUコンピューティングが注目されている。
GPUはムーアの法則をGPUコア数の増加に充て,CPUを上回るペースで高性能化を進めてきたとするスライド
 |
「GPUでは,半導体集積度の向上をコア数の増加に充て,並列処理性能を追求したアーキテクチャとすることで,現在でも年率74%の性能向上を維持している」と馬路氏。とくに,GPUとCPUの時間あたりの並列処理性能差は,2001年に30:1(=浮動小数点演算性能はGPUがCPUの30倍高速)であったのが,今日(こんにち)では1000:1にまで拡大しており,その差は今後も拡大していくと見ている。
GPUコンピューティングの現状
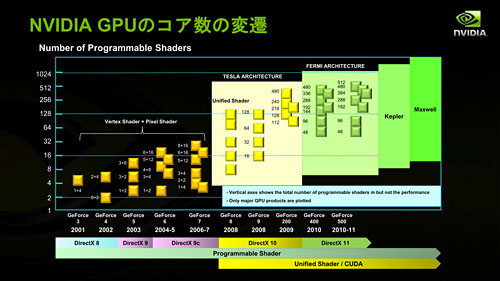
半導体プロセス技術の進化とともに,コア数を大きく増やしてきたGPUは,統合形シェーダアーキテクチャへ移行したDirectX 10以降,並列演算処理性能を高めるべく,CPUよりも早いペースでアーキテクチャの改良を繰り返し,汎用コンピューティング性能も高めてきた。
NVIDIA製GPUにおけるコア数変化の歴史
 |
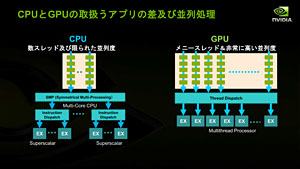 |
| CPUとGPUそれぞれの並列処理イメージ |
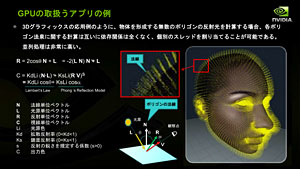 |
| GPUでは,各ポリゴンに関する法線処理には互いに依存関係がないため,それぞれに個別のスレッドを割り当てれば,複雑なキャラクター描画などを効率よく実現できる |
GPUが担うグラフィックス処理は,命令同士の依存関係がもともと薄いため,いくつものスレッドを並列に走らせやすく,並列処理性能を高めやすいという特徴があった。たとえば,3Dキャラクターなど無数のポリゴンに対して光源処理を行う場合,ポリゴンごとの法線処理には依存関係がないため,それぞれに個別のスレッドを割り当てることで,並列処理性能を高められる。
こういった並列処理性能は,科学演算処理などの高速化を可能にすることから,NVIDIAはGT100コアを採用する初代「Tesla」以降,より汎用的な大規模超並列処理ができるよう最適化を図ってきたと,馬路氏は述べている。
GPUの並列処理性能を汎用コンピューティングに活用するアプリケーションも増えているとするスライド
 |
 |
独自CPUコア開発は必然の産物
といっても,GPUとてアムダールの法則とは無縁ではない。今後もGPUコアが増え続ければ,当然のことながら壁に突き当たることとなる。
とくにボトルネックが生じやすいのは,増え続けるGPUコアを効率よく制御するためのスケジューリングや命令発行を司るコントローラ機能周りだ。
G80アーキテクチャで,SMごとのスケジューラに加え,チップレベルでスレッドを管理するThread Schedulerを搭載
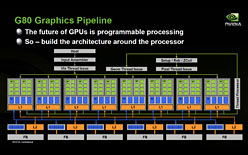 |
NVIDIAはG80(≒GeForce 8800)アーキテクチャで,32スレッドを1つにまとめたバッチ「Warp」のスケジューリングを行う「Warp Scheduler」(Thread Dispatch)に加え,チップレベルでスレッドのスケジューリングを行うThread Schedulerをも,Streaming Multiprocessor(以下,SM)レベルで搭載してきた。
その後,メニーコア化が進むなか,Fermiアーキテクチャでは,Thread Schedulerを「GigaThread Engine」へと大幅に強化。それまでは逐次実行しかできなかったカーネルプログラム(GPUを制御するためのプログラム)の同時実行に対応し,より並列処理性能を高める取り組みも行われている。
Teslaアーキテクチャ(GT100)のブロックダイヤグラムとダイ構成。Thread Schedulerが大きな割合を占めていると分かる
 |
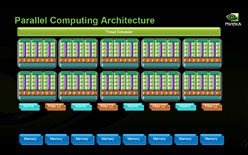 |
Fermiアーキテクチャでは,Thread Schedulerを大幅に強化したGigaThread Engineを搭載
 |
しかし,現在最大512基搭載されるCUDA Coreの数が,今度も増えていけば,スケジューリングや命令発行の処理負荷がさらに高まることは火を見るよりも明らか。つまり,今後もGPUの優れた並列処理性能を維持するためには,GPUの内部に,従来よりも強力なコントローラを搭載する必要が出てくるわけだ。そしてそれこそが,冒頭でも軽く触れた,GPU内部のスケジューリングや命令発行用プロセッサとしてのProject Denverである。
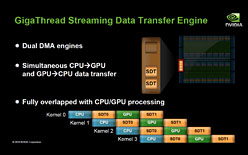
GigaThread Engineには,ハードウェアスレッドスケジューラと2基のDMAエンジンを搭載。より効率的な並列スレッド処理を実現するとともに,CPUーGPU間のデータ転送で生じるレイテンシを隠蔽する仕掛けになっている
 |
 |
同社でプロダクトマーケティングを担当副社長を務めるUjesh Desai(ユージェッシュ・デサイ)氏も「Project Denverは,GPUへの統合をターゲットとして,3年前に開発がスタートした」と認めている。
Ujesh Desai氏(Vice President, Product Marketing, NVIDIA)
 |
それが,Microsoftによる「次期Windows 8におけるARMアーキテクチャの正式サポート表明」を受けて,NVIDIAの独自ARMコアCPU開発は,その守備範囲を広げることになったわけだ。3月に開催された投資家向け会議「Financial Analyst Day 2011」で,同社社長兼CEOのJen-Hsun Huang(ジェンスン・ファン)氏も,Denverコアが将来のTegraに搭載される可能性を明らかにしている。
 NVIDIAの目指す「Computing Company」では,CPUも重要な収益源となる |
 2011年5月に示された,Project Denverプロセッサコアのイメージ |
Michael Rayfield氏(General Manager, Mobile Business Unit, NVIDIA)
 |
ただ,NVIDIA独自のCPUコアが将来のTegraへ実装されるのは,かなり先の話になりそうだ。
NVIDIAでTegraビジネスを統括するMichael Rayfield(マイケル・レイフィールド)氏いわく,
「Project DenverとTegraは無関係だ」。氏は,「省電力性が最重視されるTegraで冒険はしにくいため,当面はARMのロードマップに沿ったSoC開発を進めていく」とし,「Kal-ElはCortex-A9のクアッドコア,Wayneでは“その次のアーキテクチャコア”を採用するのが自然な流れだ」と述べている。つまりWayneでは,Cortex-A15コアを採用するということだ。
Desai氏も,
「Project Denverは,HPC向けプラットフォーム向けとなる高性能CPUコアをターゲットとしており,Tegraに収まる消費電力ではない」と述べ,Rayfield氏の発言を裏付けている。
Project Denverの目的とは
Echelon Projectには,CrayやMicron,テキサス大学,ジョージア工科大学,テキサス大学オースティン校,テネシー大学,ユタ大学,Lockheed Martinなどが参加する
 |
では,Project Denverとして開発が進められているNVIDIAの独自CPUコアは,いったいどのようなものなのか。それは,2010年11月に米ルイジアナ州ニューオーリンズ市で開催されたハイパフォーマンスコンピューティング関連の技術会議「SC10」で,2018年の投入が予告されていた「Echelon」(エシュロン)と,
GTC Workshop Japan 2011で公開されたプラットフォームロードマップから推測できる。
Echelonというのは,米国防総省の先端技術開発研究を担うDARPA(Defense Advanced Research Project Agency,国防高等研究計画局)主導の下,2018年にエクサスケールスーパーコンピュータを実現する「Ubiquitous High Performance Computing」(以下,UHPC)向けプロジェクトのこと。NVIDIAはEchelonに向けた研究助成金を受けているため,その「Phase1」期限となる2014年までにハードウェア設計を完了し,DARPAの審査を受ける必要があるのだ。
Bill Dally氏(Cheif Scientist and Senior Vice President of Research, NVIDIA)
 |
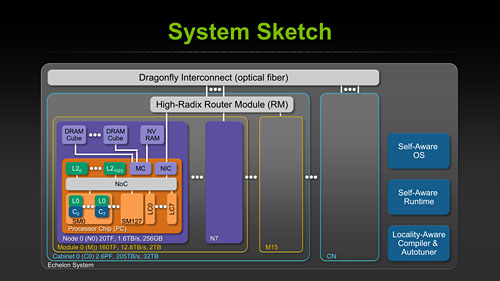
NVIDIAのチーフサイエンティストであるBill Dally(ビル・ダリー)氏がSC10のキーノートで明らかにした内容によれば,Echelonは128基のSMと,Project Denverベースで,「Latency Processor」と呼ばれる8基のCPUコアとを統合している。SMは,8基のCUDA Coreと,コアごとに1基用意されるL0キャッシュ――レジスタファイルだと思われる――とで構成されており,チップ全体では8×128=1024基のCUDA Coreを搭載する計算だ。
各SMは「NoC」(Network on Chip)と呼ばれる内部インタフェース経由でL2キャッシュやメモリコントローラ,別のSMなどと相互接続される。L2キャッシュはCUDA Core数と同じ1024個のバンクを備え,チップパッケージ上で接続されるDRAM「DRAM Cube」と1.4TB/sの広帯域幅で結ばれるのも特徴だ。
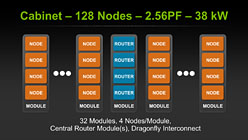
Echelonチップのピーク演算性能は倍精度で20TFLOPSに達し,「Echelonチップ4基をまとめたモジュール」を32基搭載したキャビネットで2.56PFLOPS(ペタフロップス)を実現する見込み。NVIDIAは,この基本設計を基に,Phase2では演算性能と省電力性を向上させる考えを持っている。
Echelonのブロックダイアグラム
 |
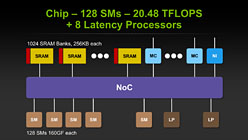 Echelonでは,128個のSMと8つのLatency Processorを統合。Latency ProcessorはDenverコアのこと |
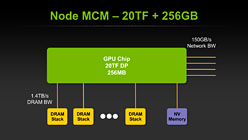 メモリもMCM(Multi Chip Module)で同一パッケージ上で接続し,DRAMスタックとは1.4TB/sの帯域を実現 |
128ノード(チップ)構成のキャビネット(Echelon×4のモジュールを32基搭載)で2.56PFLOPSを実現。400キャビネットで1EFLOPS(エクサフロップス)を実現する
 |
 |
 |
| NVIDIAのGPUロードマップ |
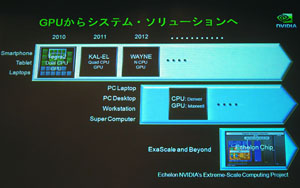 |
| GTC Workshop Japan 2011で公開されたプラットフォームロードマップ |
UHPCのPhase1にEchelonのエンジニアリングサンプルを間に合わせるためには,2013年までにProject DenverのCPUコアを完成させる必要がある。
そしてこのことは,
GTC Workshop Japan 2011で公開されたプラットフォームロードマップとも符合する。同イベントでは,Project Denverが,2013年登場予定の次次世代GPU「Maxwell」(マクスウェル,開発コードネーム)と同じタイミングで投入されることが示唆されているのだ。示されたスライドでは,DenverとMaxwellが同じ枠内に収まっていたが,Echelonと同様,MaxwellにもDenverコアが統合される可能性があると見ていいのではなかろうか。
もっとも,GPGPU用途だけではなく,3Dアプリケーション向けのGeForceとしても利用されるMaxwellでは,汎用コンピューティング専用チップとなるEchelonほどアグレッシブなアーキテクチャが採用されるとは考えにくい。
先ほどEchelonは1024コアで20TFLOPSを実現すると紹介したが,MaxwellがFermi世代と同じ消費電力の枠内,TDP(Thermal Design Power,熱設計消費電力)でいうと250W以下のレベルに収まるなら,倍精度演算性能は3.5〜4TFLOPS(Teslaの15倍,Fermiの7.5倍)あたりになるだろう。
EchelonとMaxwellでは,GPU性能そのものにも大きな違いが生じることになるはずだ。
ARMが公開した,Cortex-A15の性能指標。同じ1GHz動作でCortex-A9と比べ1.5倍の整数演算性能を実現するとされる。となると,「現行製品比3〜4倍」とされるProject Denverの性能は,Cortex-A15比で2倍以上がターゲットになるわけだ
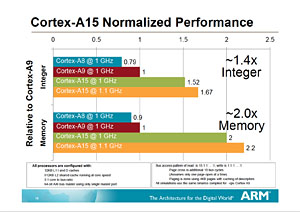 |
ところで,Project Denverのコア性能についてHuang氏は,「GPU Technology Conference 2010」において「GPUにARMベースのCPUを統合するならば,整数演算性能を現行製品の3〜4倍へ高める必要がある」と発言していた。仮にこれがProject Denverの性能ターゲットとするならば,おそらく,ARMの次世代コアであるCortex-A15の整数演算性能と比較しても2倍以上の性能を持つことになる。それが実現されれば,ARM陣営内における主導権争いを優位に進めるうえでも,Project Denverは大きな役割を果たすようになると思われる。
Desai氏は,
「『CPUコアの開発』は,すでに複数のプロジェクトが進行している」と,筆者に語っている。そして業界関係者も,Project Denverにはさらにもう1つのオプション――Windows 8ベースのノートPC向けSoC(System-on-a-Chip)――があると見ている。
念のため繰り返しておくと,EchelonやMaxwellがターゲットで,消費電力も大きなDenverコアが,そのままノートPC向けSoC製品として市場投入される可能性は低い。また,TegraにDenverコアを統合する計画は(少なくとも当面の間は)なく,付け加えるなら,2011年2月の
「Mobile World Congress 2011」で公開されたロードマップは,あくまでもスマートフォンやタブレット向けのものだ。
ただ,2013年にはIntelやAMDも薄型ノートPC向けCPUをSoC化する計画があるなか,せっかくARMアーキテクチャがサポートされたにもかかわらず,NVIDIAが“Windows 8世代のノートPC市場”へ参入しない理由もない。
Tegraのロードマップ
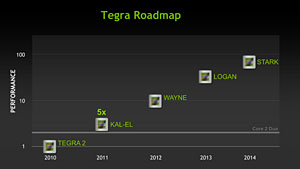 |
その意味でTegraには,より省電力性を向上させた
第2世代の独自CPUコアを充てると見るのが自然である。筆者は
5月23日の記事で,次次世代Tegraとなる「Wayne」(ウェイン,開発コードネーム)から,“Cortex-A15ベースのDenverコア”を採用するという予測をお伝えしていたが,現時点の情報を総合するに,Wayneどころか,2013年の「Logan」(ローガン,開発コードネーム)もCortex-A15ベースになる見込み。Project Denverベースの第2世代独自CPUコアがTegraに統合される可能性が出てくるのは,2014年の登場が予定されている「Stark」(スターク,開発コードネーム)からになるだろう。
Stark以降,Project Denverを活かしつつ,NVIDIAがTegraプラットフォームをどのように拡張していくのか,注目していきたい。
いずれにせよProject Denverは,NVIDIAにとって,来るべきヘテロジニアスコンピューティング時代におけるイニシアティブを握るうえで極めて重要な計画だといえる。GPUコンピューティング向けプロセッサ,3Dゲーム用GPU,そしてTegraといった同社の主要製品群に,大きな変革をもたらしそうだ。















 Project Denver(開発コードネーム)
Project Denver(開発コードネーム)