













ニュース
NVIDIA,「GeForce GTX 580」を発表。これが“本物のGTX 480”だ!?
 |
 |
 |
GeForce GTX 580レビュー記事
GeForce GTX 580はフルスペックFermiである
 |
報道関係者向けの事前説明会でGTX 580に関する説明を行ったNVIDIAのSteven Zhang(スティーブン・ザン)氏は,「GTX 480の解析を進め,『GPUコア内の,どの部位に高速なトランジスタを割り当て,どこにエネルギー効率の良いトランジスタを割り当てるべきか』について最適化を行い,リファインを行った」と,GTX 580の位置づけを説明している。言うならば,GTX 480コア内の物理設計を見直した結果が,GTX 580ということのようだ。
その主なスペックは以下のとおり。
- Graphics Processing Cluster:4基
- Streaming Multi-processors:16基
- CUDA Core:512基
- Texture Unit:64基
- ROP Unit:48基
- コアクロック:772MHz
- シェーダクロック:1544MHz
- メモリクロック:4008MHz相当(実クロック1002MHz)
- L2キャッシュ容量:768KB
- グラフィックスメモリ:GDDR5
- グラフィックスメモリ容量:1536MB
- メモリインタフェース:384bit
- メモリバス帯域幅:192.4GB/s
- テクスチャフィルタリングレート(バイリニア時):49.4GTexels/s
- 製造プロセスルール:40nm
- トランジスタ数:30億
- 外部インタフェース:Dual-Link DVI-I×2,Mini HDMI×1
- GPUクーラー:2スロット仕様,外排気
- 推奨電電容量:600W
- 公称最大消費電力:244W
- アイドル時の交渉消費電力:33W
- 動作限界温度:97℃
- 北米市場におけるメーカー想定売価:499ドル
 |
GTX 480のときには,GF100の総生産数に対して,フルスペックのSP 512基がすべて動作する良品のみを出荷すると,商売的に難しかった。そのため,製品仕様に余裕を持たせて妥協したのだが,今回は512基のSPが動作する良品の歩留まりが上がったということだ。これがZhang氏の言う,「GPUコア内における物理設計のリファイン」効果ということなのだろう。もちろん,TSMCの40nmプロセス自体が成熟度を増した可能性も,要因としては挙げられると思われる。
 |
つまり,物理的な半導体設計の見直しと,SPがフル稼働する状態になっているということを除けば,GTX 480とGTX 580に大きな違いはないのだ。
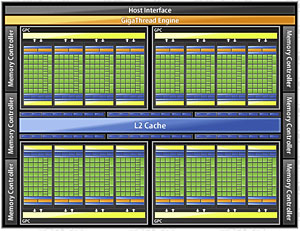
ちなみにNVIDIAは,説明会の終了後,GF110のブロックダイアグラムとしてGF100のそれを報道関係者に公開。合わせて「構造は一見,GF100と変わりないが,各ブロックの内部設計が更新されており,結果的に電力効率が改善された」といった説明を行っている。
10%のクロック向上を達成し,
理論性能値はGTX 480比で約18%向上
 |
| GTX 480解説記事よりこちらも再掲となる,GPCのクローズアップ。GTX 580ではフルスペックのGPCを4基搭載する |
 |
| こちらはRaster Engineのクローズアップ。Z-Cullユニットに改良が入っているという |
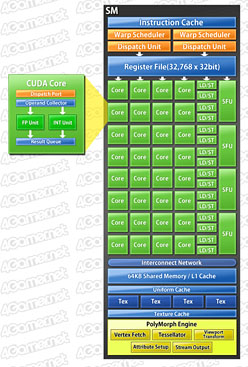 |
| SMとCUDA Coreのクローズアップ。SMの構造はGTX 480からまったく変わっていない |
各GPCに内蔵される「Raster Engine」(ラスタエンジン)が「Edge Setup」(エッジセットアップ)「Rasterizer」(ラスタライザ)「Z-Cull」(Z-カル)といった機能ブロックを持つ構成もGTX 480から変わりなし。ただ,Z-Cullユニットには改良が加えられているという。
Z-Cullは,ポリゴン(ピクセル)の描画可否判定をピクセルシェーダの起動前に行ってしまう,「早期Zカリング」(Early Z-Culling)を行うセクション。NVIDIAは伝統的に,解像度の異なるZバッファを複数組み合わせた階層的Zバッファを用いてこの処理を行ってきたのだが,GTX 580では,この可否判定処理の解像度を上げ,可否判定精度を向上させているとのことだ。これは主に,テッセレーションステージによって描画解像度以上まで過剰に分割されてしまったポリゴンの,不要な描画を回避することに貢献する。
さて,前述のとおり,1基のSMは32基のSPを内包する。SPの詳細はGTX 480の解説記事を参照してほしいが,単体のSPはスカラプロセッサであり,32bit浮動小数点(FP32)スカラ演算器と32bit整数(Int32)スカラ演算器1基ずつで構成されている。
64bit浮動小数点(FP64)演算は,SP内のFP32スカラ演算器で2クロックかけてこなす仕組みも変わらず。理論上のFP64ピーク性能はFP32ピーク性能の半分になり,GF100ベースのGPGPUソリューションたるTesla 20-Seriesだと,きっちりその性能が出ていたのに対し,GeForce製品たるGTX 480ではこれが意図的に8分の1まで抑え込まれていたが,GTX 580でもこの性能抑制は引き続いて行われている。
Texture Unit(テクスチャユニット)はSM 1基あたり4基を内包。フルスペックのGPC 4基からなるGTX 580の場合,総数は64基(4 GPC×4 SM×4 Texture Units)ということになる。
なお,4基のGPCは,6基のROP(Rendering Output Pipeline)パーティションを共有し,これらが6基の64bitメモリコントローラ接続される。ビデオメモリバス総幅は384bit(64bit×6)。ROPパーティションがそれぞれROPユニットを8基内包するため,総計48基となるが,このあたりもGTX 480と同じだ。
ビデオ出力周りにも変更はなし。世代的にもGTX 480と同等の「VP4」が搭載されている。
 |
また,メモリクロックも,GPU側のクロック引き上げに合わせて,GTX 480の3696MHz相当(実クロック924MHz)から10%引き上げられている。GDDR5メモリチップを容量1536MB分搭載するのは,GTX 480から変わりなしだ。
このほか,SMごとに超越関数ユニット(Special Function Unit。以下,SFU)を4基と,ジオメトリ支援エンジンブロックたる「PolyMorph Engine」(ポリモーフエンジン)を1基搭載する設計も,GTX 480と変わらない。
……いよいよアーキテクチャ的にはGTX 480とほとんど同じということになってきたが,ここでGTX 580のFLOPS値を計算してみよう。GTX 580の場合,SP 1基は積和演算(2 OP)をこなせ,さらにSFUは1基あたり4個の浮動小数点乗算(4 0P)をこなせるので,
1544MHz×(512 SP×2 OP+64 SFU×4 OP)≒1976GFLOPS
という計算になる。GeForceも,ついに約2.0TFLOPSの理論性能値超えが見えてきたという感じだ。ちなみにGTX 480だと,
1401MHz×(480 SP×2 OP+60 SFU×4 OP)≒1681GFLOPS
なので,演算性能は約18%向上ということになるが,ここにマジックはなく,単純に「32基のSP増加分×クロックアップ分」の性能向上割合に相当している。
SP数&クロック引き上げながら消費電力は維持
静音性が劇的に改善
 |
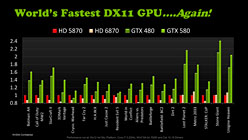
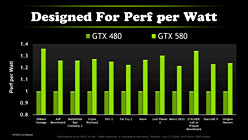
実効性能は別途掲載してあるレビュー記事を参照してほしいが,NVIDIAの公開資料によれば,SPが32基増え,動作クロックが10%向上したにもかかわらず,TDP(Thermal Design Power,熱設計消費電力)はGTX 480の250Wから244Wへ下がっているという。まあ,数値的には,「下がった」というより,「同じレベルを維持している」あるいは「物理設計の見直しによって得られた省電力性をSP数と動作クロックの引き上げに使った」と説明したほうが適切だと思うが。
 |
 |
むしろポイントは,「見直し」ではなく「一新」されたと謳われる,リファレンスGPUクーラーのほうだ。「Vapor Chamber」(ヴェイパーチャンバー)技術を採用して,冷却能力の向上を図ったのはもちろん,とくに問題視されていた動作音は,「GeForce GTX 285」と同等かそれ以下のレベルにまで引き下げられているという。
 |
 |
GTX 580向け(?)のDX11デモ
「Endless City」も公開
事前説明会では,GTX 580用に開発されたというテクノロジーデモ「Endless City」(エンドレスシティ)も公開された。内容的には「無限に広がる未来都市を飛び回る」というシンプルなものだが,登場するビルのすべてがプロシージャル技術によって生成されている」点がホットトピックになっている。

プロシージャル技術とは,知識や現象を算術的なアプローチで再現しようとする技術のこと。現在,さまざまな分野で応用研究が進められているが,3Dグラフィックスの世界では主に,コンテンツ生成のための支援技術としての研究が盛んだ。
Endless Cityでシーンに登場するビルは,デザイナーがモデリングした3Dモデルではなく,アルゴリズム的に生成された3Dモデルということになる。Endless Cityのビルモデルの生成においては「L-system」(Lindenmayer system)が応用されているとのことだった。
 |
「植物とビルの形状に一体どんな関連性が?」と思うかも知れないが,スイス・チューリッヒ工科大学の研究グループは,「建造物には植物と同じように自己相似性がある」と想定し,L-systemをビルの3Dモデル生成に応用する研究を発表した。この研究を商業ミドルウェアにまで発展させたのが,SIGGRAPH 2010のレポートでも紹介した「CityEngine」だ。
Endless Cityは,この着想を応用したものになる。
具体的には,部品となるビルディングパーツを低ポリゴンモデルで構成し,この部品を,実際にある建造物の法則性に照らし合わせて組み合わせる。そして,それらを積層させることで高層ビルを構成しているのである。
実際のレンダリングにあたっては,各低ポリゴンモデルの部品として,それぞれに対応したディテール表現を凹凸情報で記述した変位マップ(=ディスプレースメントマップ)をあらかじめ用意。レンダリング時には,視点からの距離に応じた詳細度でテッセレーションとディスプレースメントマッピングを行っている。これにより,1つ1つのビルディングをハイポリゴンでモデリングしてテクスチャを適用するよりも,圧倒的に少ないリソース消費量で,形状の異なるビルが建ち並んだ,無限に広がる街並みを再現できるというわけだ。
 |
 |
 |
 |
 |
 |
GPU負荷的にはテッセレーションステージへの負荷が高いので,SMが1基多く,すなわちテッセレーションユニット(を含むPolyMorph Engine)が1基多いGTX 580の性能誇示に貢献する,とい想定のデモなのだろう。なおこのデモ自体は,パフォーマンスさえ気にしなければGeForce GTX 400シリーズでも動作させることが可能で,実際,今回掲載したムービーは,いずれもGeForce GTX 460のSLIシステムで撮影したものになる。

 |
 |
GTX 480の製品投入が2010年の3月
それからわずか7.5か月での上位機投入
 |
4GamerのGPU関連情報を追いかけてくれている読者に向けては,まさに「このタイプの改良版」と説明したほうがピンを来るかもしれない。もっとも,GTX 480のリリースからわずか7か月半しか経っていないあたりからは,「Teslaはともかく,GeForce製品の最上位製品として,GF100はいろいろ苦しかった」という,NVIDIAの台所事情も透けて見える。
型番が100も上がったのは,主にマーケティング的な理由が大きいと思われるが,Zhang氏は「400シリーズのままだと数字が足りない」といった説明もしていたので,GF110世代の下位モデルを投入するには,450〜480あたりが詰まりすぎているというのも,理由の1つではあるのだろう。
今後の動向で注目したいのは,第4四半期中の市場投入が予告されている,AMDの「Cayman」(ケイマン,開発コードネーム)ことRadeon HD 6900シリーズだろう。絶対性能で勝るのはどちらか,そして,価格あたりの性能や消費電力あたりの性能で勝るのはどちらか。緑と赤の,(ウルトラ)ハイエンドGPU戦争に注目していきたい。
GeForce GTX 580レビュー記事
- 関連タイトル:
 GeForce GTX 500
GeForce GTX 500 - この記事のURL:
Copyright(C)2010 NVIDIA Corporation

4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー