














ニュース
西川善司の3DGE:NVIDIAが投入する20 TFLOPS級の新GPU「A100」とはいったいどのようなGPUなのか?
 |
Ampereとは,電流量の単位である「アンペア」の語源となったフランスの物理学者アンドレ=マリ・アンペール(André-Marie Ampère)にちなんだ開発コードネームだ。NVIDIAは近年,新しいGPUアーキテクチャの開発コードネームに,歴史に名を残した科学者の名を採用している。GeForce RTX 20シリーズの「Turing」や,その前世代の「Volta」も同様だ。
 |
Huang氏による基調講演では,このA100を採用したスーパーコンピュータ製品「DGX A100」や,エッジコンピューティング製品「EGX A100」が発表となったものの,これらはGPGPU用途の製品であり,グラフィックス用製品は,GeForceブランドはもちろん,プロフェッショナル用途向けのQuadroブランドにおいても発表されなかった。
ゆえに,A100自体はほとんど,4Gamer読者には縁のない存在となるだろう。とはいえ,2018年のTuringから2年ぶりとなるNVIDIA製の新GPUアーキテクチャの登場ということで,注目する価値はある。そこで今回は,基調講演とその後に行われた詳細セッション,および技術資料をもとに,A100の素性に迫ってみたい。
 DGX A100 |
 EGX A100 |
A100のアーキテクチャ概略
まずは,GPUとしての基本情報から見ていくことにしよう。
A100は,TSMCの7nmプロセスを用いて製造するGPUだ。ダイサイズと総トランジスタ数は,どちらもNVIDIA製GPUとしては最大で,826mm2,542億トランジスタとなる。かつて最大サイズを誇ったVolta世代GPU「V100」の場合,TSMCの12nmプロセスを用いて815mm2,211億トランジスタだったので,ほぼ同等のダイサイズに2倍以上のトランジスタを詰め込んだわけだ。
NVIDIAはV100登場時に「地球上に存在する最新かつ最先端の露光装置が一括で露光できる最大のサイズ」で作られたことをアピールしていたが,A100ではさらに,この限界サイズをわずかながら上げてきたわけだ。
ちなみに,NVIDIAの現行世代民生向けGPUで最上位製品となる「TU102」(※GeForce RTX 2080 Tiなどで使用)は,754mm2で186億トランジスタである。
そんなA100のブロックダイアグラムは,以下のとおり。
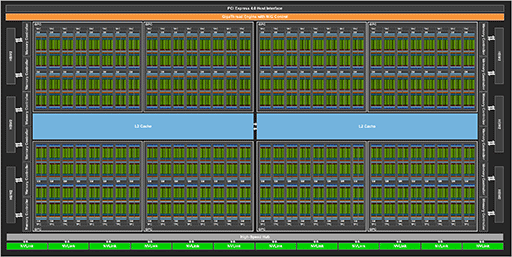 |
CPUで「コア」に相当するミニGPUクラスタ「Graphics Processor Cluster」(以下, GPC)は8基ある。ただ,この図はA100のフルスペック版を図式化したもので,半導体ダイ上はこのとおりになっているものの,最初にリリースされるA100搭載製品では,歩留まり対策のためにGPC 1基分を無効化しているそうだ
さて,以前から4Gamerでは「GPCはミニGPUのようなもの」とたとえてきたが,A100では,本当に各GPCを個別に動作するミニGPUとして扱える「Multi-Instance GPU」機能を実装してきた。簡単に言うと,MIGとは,GPC単位で独立したGPUの動作を実現することで,仮想マシンにおける仮想GPUのあり方を最適化したものと理解していい。その詳細は後段で説明するとして,GPCの話を続けよう。
GPU内には,演算コアクラスタ「Streaming Multiprocessor」(以下,SM)が多数組み込まれている。「TITAN V」のGPUである「GV100」はSM数が14基,「Tesla P100」で使われた「GP100」は10基,TU102は12基だった。そして新しい「A100」では,GPC 1基あたりのSM数は16基となっている。
つまりA100は,
- 8 GPC×16 SM=128 SM
という構成であるわけだ。
これまでのNVIDIA製GPUにおけるSMあたりのシェーダプロセッサ(NVIDIA用語のCUDA Core)数は,世代ごとに異なることもあれば,同数ということもある。Ampere世代のA100は,Volta世代やTuring世代と同じSM 1基あたり64基のCUDA Coreという構成を採用しているので,A100におけるCUDA Core総数は以下のとおりだ。
- 8 GPC×16 SM
×64 CUDA Core= 8192
| 世代 | GPU名 | CUDA core総数 | SM 1基あたりのCUDA core数 |
|---|---|---|---|
| Tesla | GT200 | 240 | 8 |
| Fermi | GF100 | 512 | 32 |
| Kepler | GK104 | 1536 | 192 |
| Maxwell | GM200 | 3072 | 128 |
| Pascal | GP102 | 3840 | 128 |
| Volta | GV100 | 5120 | 64 |
| Turing | TU102 | 4608 | 64 |
| Ampere | A100 | 8192 | 64 |
さて,ブロックダイアグラムをよく見ると,GPUの中に「TPC」という名称が見える。Ampereの仕様表を確認すると,「GPU 1基あたりのTPC数は8基」とか,「TPC 1基あたりのSM数は2基」といった情報もある。
TPCとは,「Texture Processing Cluster」の略で,現行世代のTuringにもあるものだ。NVIDIAによると,GPGPUモードでは「Thread Processing Cluster」,グラフィックスモード時にはTexture Processing Clusterと使い分けていたそうだが,現在では後者で統一しているそうだ。
以前から存在する機能ブロックではあったが,最近のNVIDIA製GPUを理解するうえであまり重要な情報ではなかったので,これまでの本連載では取り上げてこなかった。しかし,せっかくの機会なので簡単に解説しておこう。
TPCは,「テクスチャユニット群を共有するSMグループ」を示す名称だ。それがなぜ重要ではないのかというと,SM内にあるCUDA Core数がGPUアーキテクチャによって変わるので,TPCとSM数の関係から読み取れるGPUの特徴が分かりにくくなっているためだ。
たとえば,各世代のNVIDIA製GPUでは,TPC 1基あたりのSM数は以下のようになっている。
- Tesla GT200:TPC 1基あたりSM 3基
- Fermi GF100:TPC 1基あたりSM 3基
- Kepler GK104:TPC 1基あたりSM 1基
- Maxwell GM200:TPC 1基あたりSM 1基
- Pascal GP102:TPC 1基あたりSM 2基
- Volta GV100:TPC 1基あたりSM 2基
- Turing TU102:TPC 1基あたりSM 2基
- Ampere A100:TPC 1基あたりSM 2基
ただ,前述のとおり,SM内のCUDA Core数がGPUの世代によって異なるうえ,SM 1基あたりのテクスチャユニット数も世代で変わるので,TPC 1基あたりのSM数が分かったところで,GPUの素性は何も読み取れないのである。むしろ,SM 1基あたりのCUDA Core数とテクスチャユニット数の関係を見たほうが,GPUの性能特性を想像しやすい。それを表2に示そう。
| GPU名 | CUDA core数 | テクスチャ |
CUDA core数: テクスチャユニット数 |
|---|---|---|---|
| Tesla GT200 | 8 | 8 | 1:1 |
| Fermi GF100 | 32 | 4 | 8:1 |
| Kepler GK104 | 192 | 16 | 12:1 |
| Maxwell GM200 | 128 | 8 | 16:1 |
| Pascal GP102 | 128 | 8 | 16:1 |
| Volta GV100 | 64 | 4 | 16:1 |
| Turing TU102 | 64 | 4 | 16:1 |
| Ampere A100 | 64 | 4 | 16:1 |
SM 1基あたりのCUDA Core数はKeplerが最大で,その後は減少傾向にある。ただ,PascalからAmpereまでのGPUは,演算能力とテクスチャ性能のバランスを16:1に設定し続けていることが読み取れて面白い。
さて,A100のCUDA Core総数は8192基と上で述べたが,実際に製品として出荷されるGPUの「GA100」は,1280基ものCUDA Coreが無効化されるそうで,有効なCUDA Core総数は6912基であるとのこと。1280基といえば,「GeForce GTX 1650 SUPER」1基分に相当するのだから,かなりの数を無効化しているわけだ。
さらに,無効化の内訳も興味深い。前述のとおり,8基あるGPCのうち,まるまる1基分を無効化するのに加えて,残るGPC 7基中の2基から,SMを2基ずつの計4基を無効化しているのだ。式にするとこうなる。
- 1 GPC×16 SM×64 CUDA Core=1024
- 4 SM×64 CUDA Core=256
GPU 1基分の無効化だけでは済まかったのが興味深いところで,超巨大なチップゆえ,歩留まりがあまりよくないのかもしれない。
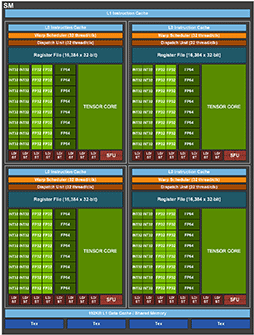 |
A100が内蔵する推論アクセラレータのTensor Coreは,総数512基となっている。Volta世代のGV100は640基だったので,やや少ない。GV100の場合,SM 1基あたりTensor Coreが8基という割合だったが,A100ではSM 1基あたりTensor Coreが4基になっているのだ。数は減少しているものの,A100におけるTensor Coreはアーキテクチャを刷新したそうで,Tensor Core 1基あたりの演算能力が向上しているので,むしろ総合性能ではGV100を凌駕するという。この詳細は後述しよう。
なお,GA100の動作クロックについてはブーストクロックだけが公開されており,1410MHzとなっている。ベースクロックが未公開なのは,2019年にNVIDIAが提起した動作クロック表記問題に関係がありそうだ。つまり,「NVIDIAのブーストクロックは,継続して動作できるクロックなので,これが事実上のベースクロックのようなものである」という主張なのだろう。
ここまでを踏まえて,単精度浮動小数点演算の理論性能値を計算してみると,A100がフルスペックで動作したときは以下のようになる。倍精度浮動小数点演算は,この値を半分にすればよい。
8192×2 OPS×1410MHz=23.10 TFLOPS
製品として登場するGA100の単精度浮動小数点の理論性能値は,以下のとおり。
6912×2 OPS×1410MHz=19.49 TFLOPS
GPU 1基の理論性能値が,ついに約20 TFLOPSまで到達したことは,とても感慨深い。
グラフィックスメモリには,第2世代のHigh Bandwidth Memoryとなる「HBM2」を採用しており,総容量は48GBだ。GPUパッケージ上には,6つのHBM2スタックがあり,各スタックは,記憶容量8Gbit(1GB)の半導体ダイを8層重ねた製造コストの高い構造であるという。グラフィックスメモリのメモリインタフェースは,1024bit×6スタックの計6144bitとなる。
 |
ここで興味深いのは,実際にNVIDIAから出荷されるGA100は,パッケージ上に実装したHBM2のうち,6スタック中1基分を無効化していることだ。つまり,パッケージ上には48GBのHBM2を実装しているのに,利用できるのは40GBに留まり,メモリインターフェースも1024bit×5スタック分の5120bitとなる。これも歩留まり対策であろう。GA100のHBM2実装が,8層ものメモリダイを貫通するTSVを用いて配線するという技術的な難度の高い方法を選択したことと無関係ではあるまい。
グラフィックスメモリの動作クロックは1215MHz。5120bitのメモリインタフェースで倍速(Double Data Rate,DDR)でのデータ転送を行うので,メモリバス帯域幅は,
- 5120bit×1215GHz×2(DDR)÷8(byte)=1555GB/s
となる。これはいうまでもなく業界最速だ。
進化したキャッシュシステムとCUDA 11が実現するAsync Copy
続いて,もう少し細かいレベルでA100を見ていきたい。まずはキャッシュメモリと共有メモリだ。
Volta世代のGV100では,SM 1基あたり容量128KBで,L1キャッシュと共有メモリを兼任する超高速なメモリサブシステムを搭載していた。専用命令を使うことにより,動かすアプリケーションに応じて128KBのメモリを「L1キャッシュに何KB,共有メモリに何KB」といった具合で柔軟に割り振ることができた。
それに対してA100では,このアーキテクチャをそのままに,容量を192KBに増やしている。これによって,GV100では共有メモリ側に割り当て可能な最大サイズは96KBまでだったところ,A100では164KBまで増えたそうだ。164KBという容量は,いかにも中途半端に思える。筆者は資料の誤記かと思い,NVIDIAのアーキテクトに確認したところ,たしかに160KB+4KBで正しく,4KB分はここで説明する新しい非同期技術のために必要と判断して増量したのだそうだ。
一方,A100におけるL2キャッシュ容量は大幅に増えている。GV100では6MBだったのが,A100では約6.7倍にあたる40MBにまで増えたのだ。A100のL2キャッシュ増量は,単なるGPUアーキテクチャの世代が新しくなったからではなく,A100が採用したメモリアクセスモデルの刷新によるものである。
A100では,最新版のCUDAである「CUDA 11」で採用となった「Asynchronous Copy」(非同期コピー,以下 Async Copy)と呼ばれる新しいメモリアクセスモデルに対応しており,それに合わせてGPUのメモリアーキテクチャを大幅に変えてきたのだ。
簡単に言うとAsync Copyとは,CUDA 11で導入された新しいプログラミングモデルを実現させるための技術で,あるGPGPU処理系が,前段のGPGPU処理系の処理が終わるのを待つことなく非同期に処理を開始できる機構である。
非同期(Async)のコピー(Copy)とは,あるデータセットが処理中であっても,その処理終了を待つことなくGPUシステム側がGPGPU処理系に対して,次に流し込むべきデータセットの準備を行えるところから来ている。
次に掲載する図をもとに説明しよう。次に掲載する図の左は従来のGPGPU処理系だ。この場合,GPGPU処理のカーネル(※GPU内で動く小さなプログラム,実質的な処理実行部)は,割り当てられたデータセット(Produce Data)の処理を終えるまで,次のデータセットを準備できなかった。一方,図の右はAsync Copyの処理系を示したものだ。GPGPU処理のカーネルが作業を終えていなくても,必要なデータセットの準備(コピー)を非同期に実行できる。
ただ,Async Copyを実現するには,CUDA 11に新設された専用のプログラミングモデルを使う必要がある。また,非同期で実行できるのはデータセットの準備までで,カーネルの実行は同期を取る必要がある。
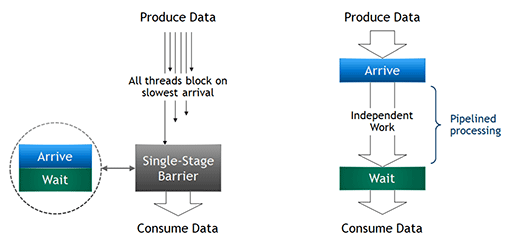 |
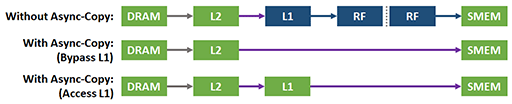
この実現にともない,NVIDIAはA100のL1キャッシュとL2キャッシュに,Async Copy専用の動作モードを用意している。次の図は,GV100(※図中のV100)とA100におけるキャッシュアクセスの流れを示したものだ。左がGV100で,右がA100である。
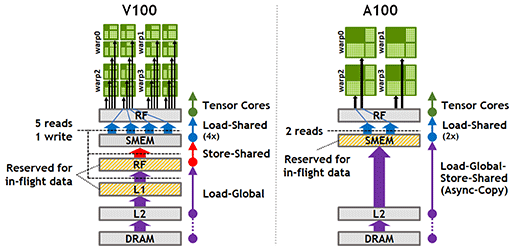 |
GV100以前の場合,グラフィックスメモリ(図中のDRAM)から読み込まれたデータはL2キャッシュとL1キャッシュに格納されたうえで,レジスタファイル(同 RF)を通じて共有メモリ(同 SMEM)に転送されていた。これがA100になると,Async Copyをかけている間はL2キャッシュからダイレクトに共有メモリに転送できる。L1キャッシュへの格納を省略できるのだ。
なお,Async Copy時にL1キャッシュが意味をなくすわけではない。L1キャッシュへの格納を省略するだけだ。GPGPU処理系ではストリーム処理が多いため,データがL1キャッシュに載っている必要はないという理屈である。
 |
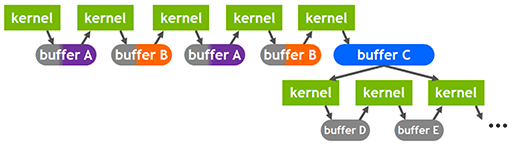
さらにA100では,Async Copyを実行中に専用命令でL2キャッシュの振る舞いを制御できるようになっている。
GPGPU処理系において,処理を行うカーネルはグラフィックスメモリ上にあるデータに対して処理をしているつもりだが,実際にはL2キャッシュにあるデータに対して処理をしている場合がある。そのカーネルが処理を終えれば,L2キャッシュの内容はグラフィックスメモリに書き戻される(※キャッシュのライトバック処理)わけだ。
ところが,ある種のGPGPU処理系では,単一あるいは複数のカーネルが集中して特定のメモリ領域を処理することがある。その場合,1つのカーネルが処理を終えるたびにライトバック処理をしていると余計なメモリバス帯域を消費するし,どうせ次のカーネルも同じメモリ領域を参照するのだから,そもそもライトバック処理は不要かもしれない。
そこでA100では,CUDA 11においてAsync Copyを使用するときに,L2キャッシュの内容をライトバックしないという制御ができるようになった。
 |
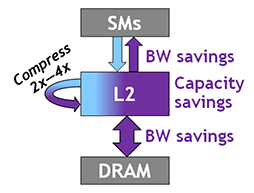 |
圧縮率は最大4倍で,圧縮するデータの様相(※値の分散具合など)によって決定されるとみられる。
演算精度よりもスループット重視へ
AI処理に最適化した新生Tensor Core
SMの内部にあるGPUコア部分を見ると,CUDA CoreはTuring世代から大きな変化はない。大きな変化があったのはTensor Coreだ。
念のために説明しておくと,Tensor Coreとは「推論アクセラレータ」のことで,マーケティング用語では「AIプロセッサ」などと言われるものである。なんだかすごそう名前だが,実際に行える演算は行列同士の積和算である。行列同士の積和算は,機械学習のようなAIの学習処理,あるいは推論処理において多用されるもので,畳み込み演算や座標変換計算などにも応用できるので,CGや映像処理でも使え,音声信号処理にも有効だ。
GV100の第1世代Tensor Coreでは,Tensor Core 1基あたり16bit半精度浮動小数点(FP16)数の積和算(FMA:Fused Multiply-Add)を1クロックに64並列で演算できた。加算する対象や演算結果の出力先としてFP32が選択できるため,混合精度(Mixed-Precision)演算とも呼ばれる。第2世代Tensor Coreを搭載するTuring世代GPUも,アーキテクチャは基本的にGV100のそれと変わらない。
これに対して,A100が搭載する第3世代Tensor Coreでは,混合精度の積和算を1クロックで256も行えるようになった。つまり,SM 1基あたりのTensor Core数は,GV100の8基から4基へと半減したものの,演算能力は4倍に向上しているわけだ。すなわち,同クロックで動作させた場合,A100のTensor CoreはGV100よりも2倍も性能が上がっていることになる。
NVIDIAは,「A100のTensor Coreは,GV100比で2.5倍の性能がある」と説明しているが,この2.5倍という数字はどこから出てきただろうか。これは,GA100とGV100の動作クロックとSM数の違いに着眼すると理解しやすい。
GV100とGA100のスペックは以下のようになっているので,
- GV100:SM 80基,クロック 1530MHz
- GA100:SM 108基,クロック 1410MHz
これから計算すると,
- (108÷80)×(1410÷1530)×(Tensor Core 1基あたり2倍の性能向上)=2.488
となる。NVIDIAの言う2.5倍の根拠が理解できるだろう。
さて,Turingの第2世代Tensor Coreでは,INT8,INT4,INT1(バイナリ)に対応したことがアピールポイントだった。INT8はいわゆる8bit整数(0〜255)で,INT4は4bit整数(0〜15),INT1は(0か1)のことだ。ただ,INT8はともかく,INT4,INT1までをTensor Coreがサポートする必要があるのかと思うかもしれない。
機械学習系AIの開発においては,学習対象とするデータによっては,取り得る値の範囲(ダイナミックレンジ)が広い数値表現形式は,それほど必要ないケースも多々ある。正規化した学習データを用いて行う推論処理ではとくにその傾向が強いので,INT4やINT1で十分という用途もあるのだ。
さらにGA100のTensor Coreでは,第1〜第2世代で対応していた数値表現形式に加えて,新たに「BF16」「TF32」という2つの形式に対応した。ちなみに,BF16の「B」は「Brain」の略で,「学習用データ形式」の意味が込められている。NVIDIA独自の定義ではなく,AI開発に関連する業界では,少し前から実用化が始まっていた形式だ。一方,TF32の「T」は「Tensor」から取られている。
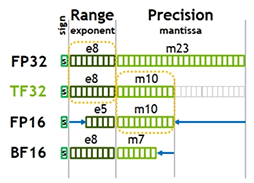 |
ここで注目すべきは,どちらも指数項をFP32と同じ8bitとして,AIに与える学習データや信号データのダイナミックレンジを拡大しているところだ。数値計算における値の精度よりも,記録できるデータの幅を重視した数値表現形式なのである。INT4やINT1とは逆に,学習対象とするデータ群のダイナミックレンジが広い場合には,BF16やTF32のような数値表現形式は都合がいいのだ。
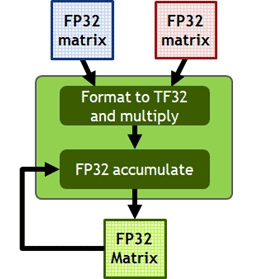 |
VoltaやTuring世代のTensor Coreは,FP16の行列演算に対応していたものの,FP32の行列演算には対応していなかった。一方,Ampere世代のTensor Coreは,VoltaやTuring世代とは異なり,FP32の行列演算をこなせるようになったのが大きなポイントだ。
それに加えてAmpere世代のTensor Coreは,2つのFP16演算か,2つのBF16演算を同時にこなせる設計となっている。A100の構造を説明した文章で,「A100のTensor Coreは総数512基で,Volta世代の640基よりも少ない」と説明したが,A100でTensor Core数が減っているのにSM 1基あたり2倍のTensor Core性能を実現できる理由がこれである。
ただ,A100のTensor Coreには少しからくりがある。演算器の内部演算精度はFP32ではなく,TF32に最適化されているのだ。そのため,FP32精度のデータを入出力はできるものの,積算時にはFP32をTF32に丸め込んで演算を行う。一方,加算の場合はFP32精度のまま行える。つまり,Ampere世代のTensor Coreの演算器は,19bit TF32演算器となっていて,仮数部の演算精度を犠牲にしてFP32の演算をこなせるようにしたわけだ。
ちなみに,NVIDIAによると,A100の19bit TF32演算器は,回路規模的にはFP32演算器に近いという。また,TF32のデータは,レジスタ上もメモリ上におけるサイズもFP32と同じ32bitサイズとして扱い,演算しているそうだ。
NVIDIAが明らかにしたA100の主な理論演算性能値を表3に示しておこう。「Peak〜Tensor Core」とある場合は,A100が有するすべてのTensor Coreを使用した場合の性能値で,Tensor Core表記がない性能値はCUDA Coreによる演算性能値である。また,すべての値はGPUをブーストクロックで動作させた場合のものだ。
| Peak FP64 | 9.7 TFLOPS |
|---|---|
| Peak FP64 Tensor Core | 19.5 TFLOPS |
| Peak FP32 | 19.5 TFLOPS |
| Peak FP16 | 78 TFLOPS |
| Peak BF16 | 39 TFLOPS |
| Peak TF32 Tensor Core | 156 TFLOPS|312 TFLOPS |
| Peak FP16 Tensor Core | 312 TFLOPS|624 TFLOPS |
| Peak BF16 Tensor Core | 312 TFLOPS|624 TFLOPS |
| Peak INT8 Tensor Core | 624 TFLOPS|1248 TFLOPS |
| Peak INT4 Tensor Core | 1248 TFLOPS|2496 TFLOPS |
A100におけるTF32の理論性能値が「156 TFLOPS」となっているが,この値の意味を説明しよう。
まず,4×4要素の行列同士による積和算を考える(関連画像)。計算量としては,4×4の16要素に対して4回の積和算(2 FLOPS)が必要だ。A100の製品版であるGA100の場合,Tensor Core総数は432基。A100では演算器がTF32化されて,さらに数が2倍となったことを踏まえて理論性能値を計算すると,
- 432基×1410MHz×(16要素×4回×2 FLOPS)×2倍=155.934T TensorFLOPS
となって,上のNVIDIA発表値とほぼ一致する。その他のFP16やBF16,INT8やINT4の理論性能値は,これの倍々ゲームなのであえて説明する必要はあるまい。
気になるのは,Tensor Core利用時におけるFP64の理論性能値が19.5 TFLOPSとなっている点だ。CUDA Coreによる9.7 TFLOPSの2倍はあるが,FP32やTF32形式のスループットに比べると8分の1しかない。単純にイメージすると,FP32やTF32形式の半分となる78 TFLOPSあたりではないかと思うのだが,そうはならないという。NVIDIAに確認したところ,これはTF32精度に最適化した演算器の特性によるものだという。「FP64は,Tensor Coreで取り扱うべき数値表現形式としては優先度が低い」と判断してこの仕様になったそうで,NVIDIAとしては,それでも19.5TFLOPSもあれば性能面では十分だろうという話だった。現状では,確かにそうかもしれない。
さて,A100のTensor Coreには,もうひとつ施された改良点がある。それは「疎行列」(Sparse Matrix)演算への対応と最適化だ。
疎行列とは,スパース行列とも呼ばれるもので,行列の要素にゼロが多く含まれるものをいう。ゼロに対する積算はゼロになることが確定しており,ゼロの加減算は演算を行うこと自体が無意味だ。つまり,ゼロ演算を行うことなく,本当に演算が必要な行列の計算に演算器を回せるのなら,より速く処理が終えられるはずだ。こうした最適化が,A100のTensor Coreに施されたのである。
疎行列は,機械学習や深層学習においてよく登場するものだ。多層のニューラルネットワークにおいて,対象とする学習テーマによっては,特定のノード間における接続が不要であると分かった場合に,そのノード接続を無効化しても問題ない場合が多い。これを「枝刈り」(Pruning,プルーニング)と呼ぶが,プルーニングを行ったニューラルネットワークでの畳み込み演算には,疎行列が頻繁に登場するのだ。
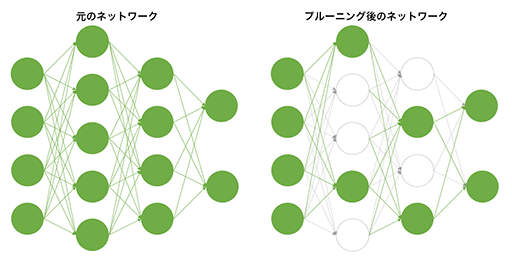 |
また,学習データの正規化(Normalize)や量子化(Quantize)を行うときも同様だ。大小の値が混ざる学習データにおいて,あまりにも絶対値が小さい値はゼロと見なしてもいいと判断した場合,その値を用いる演算には疎行列計算が頻発する。こうした疎行列への最適化は,近年の学習・推論アクセラレータにおけるトレンドとなっており,A100もこの流れに乗ったということのようだ。
A100の場合では,「2 out of 4」パターン,すなわち4要素のうち2つがゼロではない実効値を持つ行列計算に対応する。疎行列は「4要素のうち,どの位置がゼロになるか」を表す4bitのインデックスビット(図における紫色の「Non-zero indices」)とともに表現される。
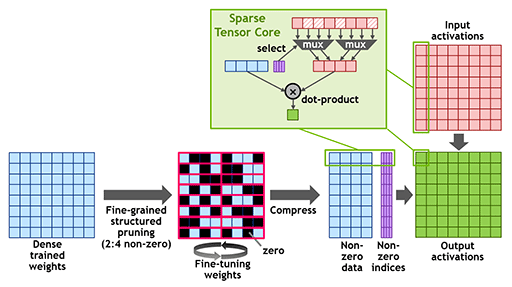 |
これにより,2 out of 4パターンの4要素による疎行列の計算は,これまでの半分の演算器で済むことになり,トータルでは2倍のスループットが期待できる理屈である。
A100とV100で同じ表現形式同士で,A100では,疎行列計算の最適化を利用した場合における演算性能の比較をまとめたのが表4だ。「TC」はTensor Coreを使った演算を示す略表記である。少々ごちゃごちゃしているが,「A100」と「A100 Sparsity」(※A100における疎行列計算の最適化理論値)の列を比較してみると,きっちり2倍となっているのが確認できるだろう。
なお,Tensor Coreを使った疎行列計算の最適化理論値で,FP64とINT1(0か1,Binary)はN/A,つまり非対応となっていた。INT1は,これ以上簡略化できない演算なので当然ではあろうが,FP64の疎行列計算にA100が対応していないのは興味深い。
| V100 | A100 | A100 |
A100 |
A100 |
|
|---|---|---|---|---|---|
| A100 FP16 |
31.4 | 78 | N/A | 2.5倍 | N/A |
| A100 FP16 TC |
125 | 312 | 624 | 2.5倍 | 5倍 |
| A100 BF16 TC |
125 | 312 | 624 | 2.5倍 | 5倍 |
| A100 FP32 |
15.7 | 19.5 | N/A | 1.25倍 | N/A |
| A100 FP32 TC |
15.7 | 156 | 312 | 10倍 | 20倍 |
| A100 FP64 |
7.8 | 9.7 | N/A | 1.25倍 | N/A |
| A100 FP64 TC |
7.8 | 19.5 | N/A | 2.5倍 | N/A |
| A100 INT8 TC |
62 | 624 | 1248 | 10倍 | 20倍 |
| A100 INT4 TC |
N/A | 1248 | 2496 | N/A | N/A |
| A100 Binary TC |
N/A | 1248 | 2496 | N/A | N/A |
A100をハードウェア的に7つのGPUとして使えるMIGモード
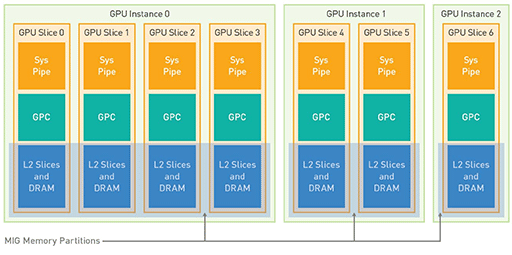
A100には興味深い新機能として「Multi-Instance GPU」(以下,MIG)機能を搭載してきた。MIGとは,「GPCはミニGPUのようなもの」と本連載でたびたび例えていたものを実現したような機能で,A100にある8つのGPC(※製品版であるGA100では7基)を,それぞれ独立したGPUとして動作させるというものだ。
NVIDIAは,MIGを何のために実装したのかというと,スーパーコンピュータやデータセンター向けサーバー,あるいはGPUサーバー的な用途で使うためである。仮想マシンに割り当てたGPUに高性能を発揮させるための新アーキテクチャという感じだろうか。
Pascal世代以前のNVIDIA製GPUの場合,仮想マシンから使えるGPUは,物理的に1基のGPUをソフトウェアのみで仮想化していた。そのため,複数のユーザー(≒複数の仮想マシン)が発注したGPUタスクを,ソフトウェア的な処理で単一GPUに対する仕事に偽装してGPUに送り,得られる結果をまたソフトウェアによって仕分けしてユーザー側に返すといった処理をしていたわけだ。
それがVolta世代GPUから,ハードウェア支援を受けての仮想化に変わった。Volta世代では,複数の仮想マシンが発注したGPUタスクをタグ付けしてGPU側に送ることで,そのままGPU内で処理できる仕組みを実現していたのだ。処理結果は,終わったものから逐次仮想マシン側に返すことができるため,結果として性能も向上する。
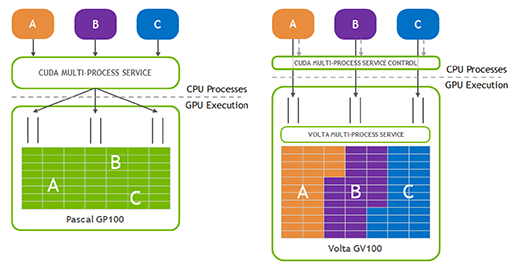 |
GPU仮想化は,Volta世代以降の実装形式で何の問題もないように思えるが,課題もあった。それは,メモリやキャッシュの使い方が,各仮想マシンで異なっている場合の対処である。発注されたGPUタスクの実行自体は,1基のGPUで行われるため,たとえば,あるGPUタスクが非常に高い頻度でメモリアクセスを行うとメモリバス帯域が消費されてしまい,他の仮想マシンからのGPUタスクに対するキャッシュの効果は薄まってしまう。言い方を変えれば,同時に動いている他の仮想マシン次第で,自分が使っている仮想マシンのGPU性能が変わってしまうということでもある。これは望ましいあり方ではない。
そこでNVIDIAは,GA100なら7つ有するGPCを「最大7基の物理GPU」(※A100のフルスペックならGPC 8基)として使えるようにMIGを実装したのである。
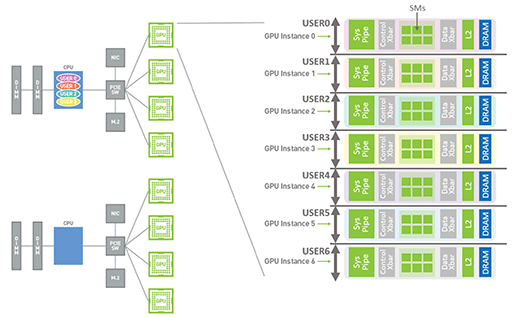 |
最大7基とあるのは,仮想マシンの構成に合わせて,割り当てるGPCの数を変えられるためだ。トータルで7基になる範囲で割り当てを変えられるので,たとえば3つの仮想マシンに対して,それぞれGPCを4基,2基,1基といった具合に,異なる構成で仮想マシンに割り当てることもできる。仮想マシンユーザーの契約や処理の優先度に応じて,GPC割り当ての多い仮想マシンを使わせることもできるのだ。
このMIG構造により,各仮想マシンのGPUは独立したGPUとして振る舞うため,メモリもキャッシュも,他の仮想マシンがGPUをどう使うかに影響を受けない。加えて,ある仮想マシンのGPUから,別の仮想マシンのGPUにアクセスする手段もなくなったので,セキュリティ的にも安心というわけである。
 |
ただ,MIGモードは,GPGPU専用の機能であるため,いくつかの使用制限のようなものはあるというという。
A100に限らず,近年のNVIDIA製GPUは,グラフィックス処理とGPGPU処理を兼任できるパイプラインが1本あり,これ以外のパイプラインはすべてGPGPU処理専用パイプラインとなっている。GA100には7つのパイプラインがあるが,MIGモードになると,パイプラインはすべてGPGPU用となってしまうのだ。そのため,MIGモード時のGA100はGPGPU専用GPUになってしまい,グラフィックス描画は行えない。
なお,MIGモードと通常の単一GPUモードとの切り替えは,GPUモードリセットが必要で,気軽に切り替えることは推奨していないようだ。
A100はNVIDIA製GPU初のPCIe Gen 4対応へ
GA100の登場に合わせ,NVIDIAは,独自インターコネクトである「NVLink」を強化してきた。
NVLinkは,GPUとCPU,あるいはGPUとGPUを結ぶNVIDIA独自の専用バスだ。Pascal世代で導入され(関連記事),Voltaで第2世代となり,今回のA100で第3世代へと進化した。
第3世代NVLinkでは,差動伝送技術(Differential Signaling)の採用により,伝送レーンあたりの帯域幅は2倍に向上している。ただし,1リンクあたりの信号線数は半分に減ったそうだ。
Turing世代以前のNVLinkは,1レーンあたりの帯域幅が片方向25Gbps(=3.125GB/s,なお,一部のNVIDIA資料では25.78Gbpsという記述もあるが,本稿では25Gbpsで統一する)であった。この伝送レーンを8本束ねてNVLinkの1リンク分を構成していたので,1リンクあたり8レーン×2(上り下り)という構成になるので,1リンクの帯域幅は双方向で以下のとおりとなる。
- 3.125GB/s(=25Gbps)×8レーン×2=50GB/s
一方,AmpereのNVLinkでは,それまでのシングルエンド伝送を改めて,高クロック化に強い差動伝送技術を採用したことで,1レーンあたりの伝送速度を倍速化した。そのため,1リンクあたり4レーン×2構成で,同じ50GB/sを達成したわけである。
実質的に信号線数を削減できたので,リンク数を増やすことも可能になった。Volta世代のGV100は6リンク,Turing世代のTU102で2リンク,TU104では1リンクだったところ,GA100では12リンク仕様を実現している。
なお,近年のNVIDIA製GPUのNVLink帯域幅は,以下のようになっていた。
- GV100:300GB/s
- TU102:100GB/s
- TU104:50GB/s
- GA100:600GB/s
※いずれも双方向の値
Turing系はグラフィックス処理用GPUであり,同時接続GPU数も少ないため帯域幅は控えめだ。それに対して,ほぼGPGPU専用GPUのGV100とGA100の帯域幅は相当に高い。
GA100では,12リンク構成のNVLinkを介して他のGA100と接続することが可能だ。A100と同時に発表となったスーパーコンピュータのDGX A100の場合,8基のGA100を搭載しており,それぞれのGA100は,GPU間インターコネクト技術「NVSwitch」を6基使って相互接続している。8基のGA100とNVSwitchが,このNVLinkを介して接続されるわけだ。
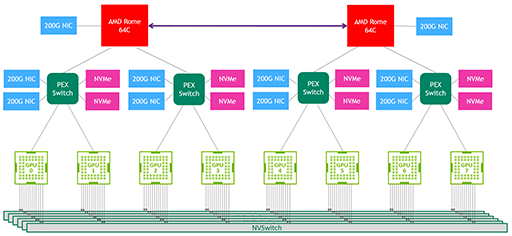 |
NVSwitchは,いうなればGPU〜GPU間接続チップセットのようなもので,Volta登場時の解説記事で詳しく説明しているので,そちらを参照してほしい。以下の動画でも大体の雰囲気は理解できると思う。

NVIDIAがDGX A100に搭載したNVSwitchは,A100に合わせて設計した新型である。最大の特徴は,8基のA100を接続するために,NVLinkを16リンク分備えている点だ。そうなると,NVSwitchの伝送帯域幅も計算できる。
- 50Gbps×2(双方向)×4レーン×16リンク=6400Gbps(=800GB/s)
さらに,この値からNVSwitchを介した8基のGA100それぞれに対する伝送帯域幅も計算してみよう。前述したように,GA100は12リンク分のNVLinkを持っているので
- 800GB/s÷(NVSwitchの16リンク÷GA100の12リンク)=600GB/s
となり,先に示したGA100のNVLink帯域幅とぴったり合致する。
なお,NVIDIAによれば,第3世代のNVLinkでは,伝送性能が向上しただけではなく,エラー訂正制御やGPU間の同期を容易にする改善や,送受信可能なコマンドの制限緩和なども実現されたそうである。
ついでに補足しておくと,GA100では,NVIDIA製GPUとしては初めてPCI Express Gen 4に対応したことも注目すべき点と言えよう。そのほかに,GA100はI/O仮想化技術の「SR-IOV」にも対応しており,仮想マシンシステムへの親和性を高めているそうだ。
AmpereベースのGeForceは出るのか?
2019年は,NVIDIAからウルトラハイエンドクラスのGPU新製品が出なかったので,今回の発表されたA100は,実に久々の新GPUアーキテクチャという印象だった。筆者の感想は,良くも悪くも「GTCというGPUコンピューティングのイベントで発表されるに相応しいGPU」に尽きる。
826mm2という世界最大級サイズのチップに,542億トランジスタも詰め込んだモンスターチップは,写真で見ても後光が眩しいほどだ。しかし,4Gamer読者のようなゲームファンからすれば,気になるのは「AmpereベースのGeForceは出るのか出ないのか」というところだろう。
これに対する筆者の予想は,「今回のA100が,TITANブランドのような形で登場する可能性は低い」というものだ。というのも,NVIDIAが「GA100は,リアルタイムレイトレーシングを処理する『RT Core』と,ビデオエンコーダ『NVENC』を内蔵していない」と明言しているからだ。
NVIDIAは2018年,「Graphics Reinvented」(グラフィックス技術の再発明)というキャッチコピーを掲げてハードウェアによるリアルタイムレイトレーシング技術を推進し始めた。仮に,巨大で高価なGA100搭載のウルトラハイエンドグラフィックスカード製品が,リアルタイムレイトレーシングに対応しないということになれば,NVIDIAのグラフィックス製品構成がおかしなことになってしまうだろう。
仮に,GA100を搭載してPCで利用可能なGPGPUカード製品としてリリースされるとしても,プロフェッショナル向けのQuadroブランドか,あるいは特殊用途の少量ロット製品になるのではないか。
それでは,Ampereを土台とした次世代のGeForce RTXシリーズは出ないのかというと,そんなこともないだろう。GA100の製造で,NVIDIAも7nmプロセス活用の知見がたまり,手応えも感じているはずだ。そこで,次世代GeForce RTXのハイエンド市場向けGPUの姿をざっくりと予測してみよう。
Volta世代のGV100は,12nmプロセスで約210億トランジスタ,ダイサイズは815mm2で,CUDA Core数は5120基だった。GA100は7nmプロセスで542億トランジスタ,ダイサイズがほぼ同じ826mm2で,CUDA Core数は6912基(フルスペックのA100は8192基)だ。仮にダイサイズを同等とみなした場合,プロセスルールの進化によってトランジスタ数は2.58倍,CUDA Core数は1.6倍の増加が可能となる。
|
GA100と同様にGPUクロックが1.4GHzだと仮定すると,理論性能値はちょうど20 TFLOPSだ。フルスペックはTITANブランドに限るとして,GeForceブランドでは歩留まり対策でGPC を1基分,CUDA Coreにして1024基分削減したものにしたならば,CUDA Core数は6272基となる。理論性能値は17.5TFLOPSといったところだ。はたしてこの予想は的中するだろうか。
NVIDIAが次世代GeForce RTXを投入するとしたら,AMDのNavi 2x世代にぶつけてくると思われるので,タイミングは2020年後半になりそうだ。ゲーマーにとっても夢が膨らむ話と言えよう。
NVIDIA公式WebサイトのA100情報ページ
- 関連タイトル:
 NVIDIA RTX,Quadro,Tesla
NVIDIA RTX,Quadro,Tesla
- 関連タイトル:GeForce RTX 30
- この記事のURL:
キーワード
- HARDWARE:NVIDIA RTX,Quadro,Tesla
- GPU
- NVIDIA
- ニュース
- ライター:西川善司
- 西川善司の3Dゲームエクスタシー
- HARDWARE:GeForce RTX 30
- HARDWARE
Copyright(C)2010 NVIDIA Corporation
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー