













ニュース
Intel,スーパーコンピュータ向けアクセラレータ「Xeon Phi 5110P」発表。60基のx86コアを1チップ上に集積
 |
| Xeon Phi 5110P。6月の時点でIntelは,最初のXeon Phiが「50基以上のx86コアと,容量8GBのGDDR5メモリが組み合わされる」というおおざっぱな情報と,Xeon Phiに集積されたx86コアの技術的な概要しか明らかにしていなかったが,いよいよ全容が明らかになった |
 |
| 2013年1月23日以降,国内外の大手メーカーから,Xeon Phi 5110P搭載のサーバーやワークステーションが国内市場向けに登場するという |
また,「Xeon Phi Coprocessor 3100」(国内製品名:Xeon Phi コプロセッサー 3100,以下 Xeon Phi 3100)シリーズの2製品を2013年第1半期中に市場投入することも合わせて同時にアナウンスしている。
Xeon Phiというブランド名やアーキテクチャの概要は6月の時点で明らかになっていたが(関連記事),ようやく,最終製品名や出荷時期などが判明したわけである。
ちなみにXeon Phi 5110Pは,米ユタ州ソルトレイク市で現地時間10日から開催されているスーパーコンピュータ関連の国際会議「SC12」に合わせて発表されたもの。Xeon Phi 5110Pの登場によってIntelは,同社として初めて,スーパーコンピュータ向けアクセラレータ市場に参入することになる。
製品の性格上,4Gamer読者とすぐに直接関係してくるものではないが,その開発経緯からして興味をそそられている人は少なくないだろう。また,Xeon Phiで培われた技術が将来のグラフィックス機能統合型CPUに活かされないとは限らない。
4Gamerでは,国内の報道関係者向け説明会に参加してきたので,それを基にXeon Phiの特徴をまとめつつ,いま何が起こっているのかを考えてみることにしよう。
60基のx86コアを実装し
ピーク倍精度演算性能1 TFLOPS超を達成
 |
Intelはかつて,「Larrabee」(ララビー)という開発コードネームで,x86アーキテクチャに基づくコアを大量に搭載する,独自設計のGPUを開発しようとしていたのだが,さまざまな理由から最終的には製品化を断念した。
しかし,「x86アーキテクチャのコアを大量に搭載する製品」の開発そのものは継続し,それに「MIC」(Many Integrated Core,マイク)というアーキテクチャ名を与えて,最終的にはスーパーコンピュータに向けて,製品化する方向へと舵を切ったのだ。6月頃まで開発コードネーム「Knights Corner」(ナイツコーナー)と呼ばれていたXeon Phiは,そんなMICアーキテクチャを採用する初の最終製品である。
Xeon Phi 5110PおよびXeon Phi 3100シリーズは,双方ともPCI Express x16に接続するタイプのカード製品だ。IntelはXeon Phiを,一般的に用いられる「アクセラレータ」という呼び名ではなく,Xeon(=CPU)の補助的に動作する「コプロセッサ」と位置づけているが,「スーパーコンピュータの演算能力を強化するPCI Express拡張カード」という意味では,NVIDIAのTeslaと同じ位置づけの製品という理解で構わない。
 |
 |
また,搭載されるメモリは合計容量8GBのGDDR5 SDRAMで,これは6月に予告されていたものと変わらず。ピーク帯域幅は320GB/sとされている。説明会で直接的な言及はなかったのだが,Intelから報道関係者に配布されたスペック表によるとメモリの転送速度は5GT/s(=メモリクロック5GHz相当)なので,メモリインタフェース幅は512bitと推定できる。
下に示した写真は,説明会の会場で展示されていたXeon Phi 5110Pの実機だ。冷却ファンを持たないパッシブ冷却型の製品となっていることから,冷却システムが完備されたサーバーやワークステーション向けの製品であると分かる。
 |
PCI Express補助電源コネクタは8ピン+6ピン構成。仕様上は最大300Wを供給できる計算になるが,カード全体のTDP(Thermal Design Power,熱設計消費電力)は225Wと,かなり抑えられた印象である。電力効率は悪くなさそうだ。
 カード後方に設けられたPCI Express補助電源コネクタは8ピン+6ピン |
 ブラケット部には,いわゆる後方排気用の大きな孔が開けられている |
 |
メモリ容量はXeon Phi 5110Pより2GB少ない6GBとなり,メモリの転送速度は5GT/sとXeon Phi 5110Pと同じながらメモリバス帯域幅が240GB/sに縮んでいるので,メモリインタフェースは384bitになっていると思われる。一方,カードレベルのTDPは300Wに引き上げられているので,動作クロックが引き上げられている可能性はありそうだ。
Xeon Phi 3100シリーズの販売形態は未定だが,Xeon Phi 5110Pと異なるのは,単体販売される可能性が否定されていないこと。Xeon Phi 3100シリーズの1000個ロット時単価は2000ドル以下だそうで,Xeon Phi 5110Pよりは低価格になる見込みだが,それでも店頭で販売されるとすると,価格は20万円を超えるだろうという話だった。気軽に購入できるような製品にはならないようだ。
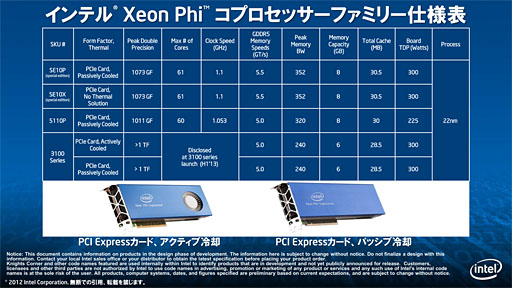 |
ところで,上のスライドで「特別版」(special edition)と書かれた製品「SE10P」「SE10X」が並んでいるのに気づいた人もいると思う。
詳細は明らかになっていないが,これらはXeon Phi 5110Pと比べて,x86コアの数が1基だけ多く,動作クロックが引き上げられ,カードレベルのTDPも300Wに達しているのが特徴だ。インテルによると,「特定顧客向けの特別版で,一般販売を行う予定はない」とのことだったので,高性能を必要とする顧客向けに出荷される(もしくは出荷された),文字どおりの特別版製品なのだろう。
Xeon Phi 5110Pのスペックを掘り下げてみる
最大の優位性はプログラムのしやすさか
 |
Xeon Phi 5110Pに集積される60基のx86基コアは,2本のパイプラインを持った,シンプルなスーパースカラ(Superscalar,スーパースケーラともいう)型だが,ハードウェアで最大4スレッドの実行に対応するとされる。つまりXeon Phi 5110Pは1枚で最大240スレッドを同時に実行できるわけだ。
NVIDIAからは「20年前のPentiumを束ねた製品」と揶揄されたx86コアで,実際に2本のパイプラインを持つシンプルな構成は20年前のPentiumによく似ている。しかしもちろん,“本物の”20年前のCPUコアを60基束ねたところで意味はなく,Xeon Phiのコアには,当時のPentiumになかった機能が付加されている。
それが512bitベクトル演算機能である。現在のCore iプロセッサはAVX(Advanced Vector eXtentions)という256bitのベクトル演算機能を持つが,その2倍のベクトル長で演算をサポートするわけだ。Xeon Phiの性能面においては,x86命令セットとの互換性より,むしろベクトル演算器こそがキモになる。
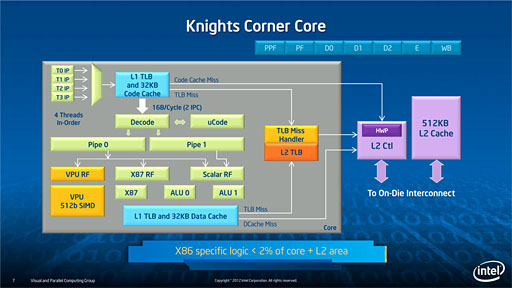 |
Xeon Phiのベクトル演算器は1クロックあたり最大2回の演算が――積和演算時だと思われるが――可能とされる。「512bit=64bit倍精度×8」なので,Xeon Phi 5110Pの場合は動作クロック1.053GHz×60(コア数)×2(1クロックあたりの演算回数)×8(64bit倍精度浮動小数点演算の数)=1010.88 GFLOPSがピーク演算性能となるわけだ。32bit単精度ならその2倍に達すると見ていい。
公開されたダイ写真も興味深い。2012年6月に公開された写真とはやや異なっており,コアと思しき相似形のブロックが合計62個あるのを確認できる。おそらくXeon Phi 5110Pでは歩留まり向上のためにコア2基分の不良が許容されているのだろう。特別版とされるSE10PやSE10Xでは許容される不良が1基ということなのだと思われる。
 |
プログラミングモデルの優位性を武器に
市場で先行するNVIDIAへ挑むIntel
 |
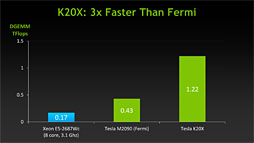
示された各種ベンチマークのスコアは下に示したスライドのとおりで,たとえば代表的なベンチマークテストである「Linpack Benchmark」では722 GFLOPS(0.722 TFLOPS),行列計算を行う「DGEMM」では833 GFLOPS(0.833TFLOPS)というスコアが示されている。
 |
 |
しかし,Xeon Phiが持つウリは,実のところ,性能だけではない。その優れたプログラミングモデルこそが大きなアピールポイントになっているのである。
具体的にどういうことかというのは,説明会で筆者が「Xeon Phiは単なる60コアのx86プロセッサと考えていいのか」と尋ねたのに対する岡崎氏の回答が「512bitのベクトル演算を除けばそのとおり」というものだった点が示唆的だ。つまり,現行のSandy BridgeやIvy Bridgeなど,従来からあるIntel製CPUとほぼ同じ感覚でプログラムを書けるというのが,Xeon Phiの持つ大きな特徴になる。
 |
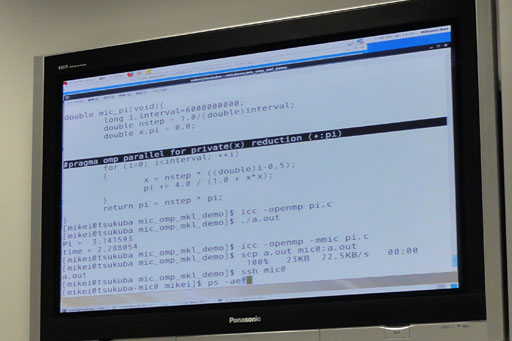
前述のとおりXeon PhiはPCI Express拡張カードになっているが,内部ではスタンドアロン型のLinuxが動作しており,ホストからはSSHを使ってログインできる。そしてデモでは,ホストOSとしてもLinuxが用いられ,円周率を計算する簡単なサンプルによるXeon Phi上でのコード実行が行われた。
サンプルプログラムは,Intelのコンパイラでサポートされるマルチプロセッサ向けプログラミング基盤「OpenMP」を使って書かれたもの。Xeonシリーズはもちろん,4Gamer読者のPC上でも実行できる,ごく標準的なマルチコア向けコードである。
 |
というわけで,Xeon Phi上で動作しているLinuxに実行コードをコピーし,Xeon Phi上で直接実行する例が下の写真だ。
 |
| 実際にデモ機で操作している様子。コンパイル実行後,ssh mic0というコマンドを実行してXeon Phiにログインしている |
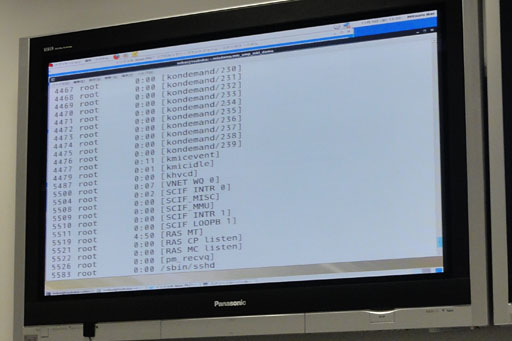 |
| Xeon Phiにログイン後,プロセスリストを表示させたところ。60コア分のカーネルスレッド(Linuxカーネル内部のスレッド)がずらずらと表示されている。Xeon Phiはスタンドアロンで動く60コアのx86プロセッサのようなものなのだ |
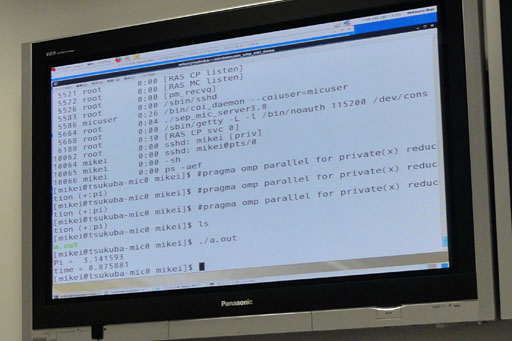 |
| Xeon Phi上で円周率計算を実行。約0.88秒という結果が表示されている |
UNIX系OSに馴染みがないとちんぷんかんぷんかもしれないが,簡単に説明すると,Xeon Phiを搭載したPCは,独立して動く60コアの別のPCをもう1台持っているように扱える。Xeon Phiにログインしてコマンドを実行したり,コードを実行させたりすることができるわけである。
このような動作は,独立したOSが動作し得ない(現行の)GPUでは不可能。Xeon Phiならではのメリットだ。もちろん,Xeon Phiではコードの一部をXeon Phiにオフロードさせて実行する,つまりGPGPUと同じ形のオフロード実行もサポートされており,ホストCPUと協力しながら計算を遂行することも可能な仕様である。
 |
GPUの場合,CUDAやOpenCLといった言語を用いて「GPUにオフロードするコード」を記述し,CPU側のコードを別のコンパイラ向けに書くといった作業が必要で,馴染むにはそれなりのハードルがある。それと比べると。OpenMPを使ってIntel製コンパイラ向けに書かれたコードならXeon Phi上でサクッと実行できるというのは,筆者には非常に魅力的に映る。
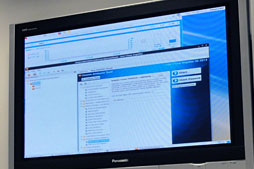 |
| Intelが提供する開発ツールの1つ「Advisor XE」を用いたデモ。Advisor XEはコードの実行効率を調べ,並列化を行うための方向性を示してくれるツールで,PC向けの開発環境で利用されているものだ。このような,既存のIntel製x86向けツールを使えるのも,Xeon Phiの大きな利点となる |
 |
| 上のAdvisor XE以外にも,スライドに示されているようなIntel製ツールがXeon Phi上で利用可能。また,「Xeon Phi専用のモニタリングツールも必要になる」(岡崎氏)とのことで,これもIntelから提供予定になっているそうだ |
ちなみに,NVIDIAはCUDAやOpenCLに加え,ホストCPUとGPU側を1つのコードで記述できる「OpenACC」というプログラミング言語の――現時点ではC言語とFortranの――拡張仕様を推している。
OpenACCをIntelがサポートすれば,GPUでもXeon Phiでも同じように実行できるコードが書ける理屈ではあるのだが,岡崎氏は筆者の質問に対して「少なくとも現行バージョンのOpenACCをサポートすることはない」と断言していた。
その理由は,現在のOpenACCが「あまりにGPUに特化し過ぎているから」(岡崎氏)だそうだ。将来のバージョンのサポートには含みを残していたが,当面はOpenMPで行くということのようである。NVIDIAでTesla製品のゼネラルマネージャを務めるSumit Gupta(スミット・グプタ)氏は以前,筆者の取材に対して,IntelがOpenACCをサポートしてくれることを期待する発言をしていたのだが,少なくとも当面の間,その期待は実現しないようだ。
いずれにしても,Xeon Phiは60コアのシングルカードコンピュータっぽい製品だったわけで,マニア的には実に面白そうなアイテムといえる。筆者も説明会場で見ていて欲しくなってしまったのだが,単体販売されそうなXeon Phi 3100シリーズでもカード単体の価格が20万円超えというと,搭載製品を遊びで買うのはさすがに少し厳しい感じがする。
ただ,実物を入手するかどうかはともかく,今後の展開には注視していくつもりだ。
 |
インテル公式Webサイト
- 関連タイトル:
 Xeon Phi
Xeon Phi - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー