















連載
 |
日本時間2012年3月22日,NVIDIAは,DirectX 11.1世代の新型GPU,「GeForce GTX 680」(以下,GTX 680)を発表した(関連記事)。
GTX 680は,かねてから予告されてきた「Kepler」(ケプラー)コアを採用する製品だ。先代の「Fermi」(フェルミ)コアは,第1弾がGeForce GTX 400シリーズとして2010年初頭に発表され,その後,GeForce GTX 500シリーズへとリファインされているが,今回は約2年ぶりのアーキテクチャ刷新ということになる。
4GamerではすでにGTX 680のレビュー記事を掲載済みだが,新世代ということもあって,GPUアーキテクチャに興味のある読者のなかには,まだすっきりしない部分がある人も多いのではないだろうか。
今回は,そのなかでもとくに引っかかるのではないかと思われる8つの事柄について,3Dゲームグラフィックス技術の視点から考察し,GTX 680,そしてKeplerアーキテクチャの正体に迫ってみたいと思う。
疑問1:トランジスタ数がほとんど増えていないのにGTX 680のSP数が従来比3倍を実現できたのはなぜか
 |
| GTX 680 GPU。ダイ上には「GK104-400-A2」の刻印がある |
 |
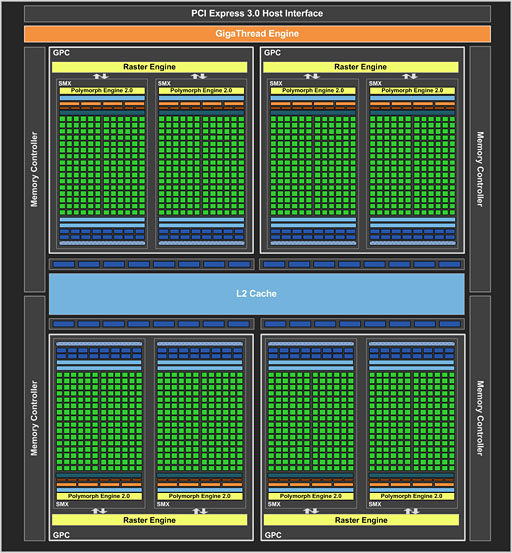
| Fermiアーキテクチャを採用したGF110コアのブロック図 |
さて680(GK104)だが,トランジスタ数は35.4億個で,ダイサイズは294mm2。Fermi世代の「GeForce GTX 580」(以下,GTX 580)だと順に30億個,520mm2なので,トランジスタ数は約16%増え,ダイサイズは約43%小さくなった計算だ。
GTX 580ではTSMCの40nm HP(High Performance)プロセス技術を採用していたのに対し,GTX 680ではこれが28nm HPプロセス技術へと一世代シュリンクされているので,これが主要因ということになる。
 |
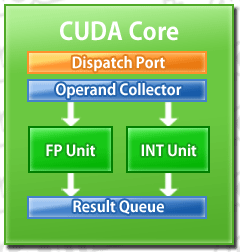 |
ちなみにGTX 680のSP自体は,32bit浮動小数点(FP32)スカラ演算器と32bit整数(Int32)スカラ演算器各1基で構成されるスカラプロセッサで,Fermi世代から変わっていない。
……と,ここで腑に落ちない点が出てくる。それは,「トランジスタ数が16%程度しか増えていないのに,なぜSP数が3倍になっているのか」というものだ。
もったいぶる必要もないので結論から言うと,KeplerアーキテクチャのGPUコアでは,FermiアーキテクチャのGPUコア上で幅を利かせていた「命令のスーパースカラ実行を司る部分」が排除され,その空きスペースにSPが詰め込まれているのである。
NVIDIAはGeForce 6シリーズ以降のGPUで,SPの命令実行をスーパースカラ化し,以降,高効率化に努めてきた。スーパースカラとは「複数の命令を同時実行させる仕組み」で,ILP(Instruction-Level Parallelism,命令レベルの並列性)を向上させるための工夫になる。
プロセッサの歴史に立ち返れば,Intelの汎用CPUでこのスーパースカラ実行を初めて導入したのは初代Pentiumだった。Pentium以降,インテルがILP向上のためにさまざまな技術を詰め込んでCPUを進化させてきたのは,ここであらためて紹介するまでもないだろう。
そんなスーパースカラ実行で面倒なのは,「同時に実行する命令の依存関係」の制御だ。スーパースカラ実行において,
- a=b+c
- z=x+y
の計算は2つ同時に行えるのだが,
- a=b+c
- y=x+a
という形になると,aの結果が出てくるまでyの計算に取りかかれなくなる。あくまでもこれは簡単な例だが,GeForceでは,このような「スーパースカラ実行における依存関係」に配慮した制御と実行とを,高度なハードウェアスケジューラで行ってきていたのである。
プログラマブルシェーダ1.x時代は,利用できる命令数や,1つのシェーダプログラムで利用できる命令種別やレジスタ数に制限があった。プログラマブルシェーダ3.x以降になると命令数の制限もほとんどなくなって,条件分岐にまで対応するようになり,そのプログラマビリティはCPUに肉薄するものになっている。そうした事情もあって,ハードウェアスケジューラの複雑度は,Fermiアーキテクチャの時点で1つの完成形になっていたのだ。
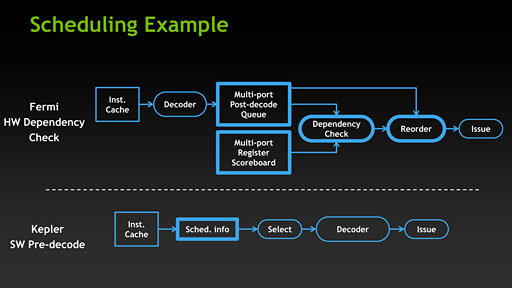
このハードウェアスケジューラは,Fermiアーキテクチャにおいて,SPを束ねた「Streaming Multiprocessor」(ストリーミングマルチプロセッサ,以下 SM)に搭載されてきたが,ここからが本題。Keplerアーキテクチャでは,このハードウェアスケジューラが簡易的なものにスケールダウンしたのである。そして,それによって空いたスペースに,SPをぎっしり詰め込んできたというわけだ。
もっとも,GTX 680ではL2キャッシュ容量が小さくなっていたり,ROPユニットが削減されたり,メモリインタフェースが256bitになっていたりもするので,アーキテクチャの総合的な整理整頓も,GTX 580比で3倍ものSPを詰め込めた大きな要因となっているのは間違いないのだが。
では,GTX 680においてNVIDIAは高効率なスーパースカラ実行をあきらめてしまったのかというと,そういうわけではないらしい。
GTX 680では,このアーキテクチャ改変に伴い,グラフィックスドライバのアーキテクチャも変更しているのである。
GTX 680用のグラフィックスドライバは,従来のGeForceにおいて,GPU内部のハードウェアスケジューラが行っていたような「スーパースカラ実行のためのスケジューリング」を事前処理して,GPU側で実行されるネイティブ命令コードに,その依存関係を記載した付随情報(ステータスビット)を仕込むのだ。GPUコア側では,この付随情報とともに命令をデコードし,実行時にはこの情報を基にして「どの命令とどの命令を同時に実行するか」を選択していくことになる。
ここで重要なのは,ドライバ「ソフトウェア」で,これまでハードウェアスケジューラで行っていた処理を行うということだ。もっといえば,CPU側で実行されるというわけである。
となると気になるのは「ここにオーバーヘッドはないのか」という部分になる。
そもそもの話として,コンパイル済みのバイナリコードになっているシェーダプログラムは,ドライバ側でネイティブコードへ変換されてGPUに送り込まれる仕様になっており,「ネイティブコード変換時ににGPUごとの最適化処理を盛り込む」というのはこれまでも行われてきた。ただ,Keplerアーキテクチャでは,この時点で「ネイティブコード実行計画の見繕い」も行われるわけで,そこが若干のオーバーヘッド増加をもたらす可能性はあるだろう。
要するにNVIDIAは,オーバーヘッドの増加を覚悟のうえで,多数のSPを搭載することを選んだのだと思われる。
 |
なお,DirectX 11世代のグラフィックスドライバでは,GPU側の都合をあまり気にせず並列動作できるジョブキュー(Job Queue)型のマルチスレッド制御を行える仕組みが導入されており,DirectX 10以前よりもCPUとGPUの並列性が高まっている。さらに最近はほとんどのPCにマルチコアCPUが搭載され,PCI Expressインタフェースも,より高速なGen.3を選択する人が多くなるだろう。こうした状況も,NVIDIAの判断を後押ししたと筆者は推測している。
疑問2:NVIDIAはなぜ,倍速シェーダクロックアーキテクチャをやめたのか
 |
GPUに限らず,プロセッサの性能を上げるためには単位時間当たりの演算能力を高める必要があり,その方策としては2つのアプローチがある。
1つは「演算ユニットを高速に動かして単位時間当たりの演算量を高める方針」,もう1つは「演算ユニット(※GPUの場合ならばSP)を増やす方針」だ。言ってしまえば当たり前の話だが,ともあれ2種類ある。
前者で性能向上を図るには,処理の単位を細かく裁断し,「細かく裁断された処理単位」でロジック(logic,電気回路構成)を構築する。この裁断数がいわゆるパイプライン段数(あるいはパイプラインステージ)だ。
パイプライン実行はよくバケツリレーに喩えられるが,バケツを手渡す人の1人が各パイプラインステージというイメージでいい。
消費電力という問題があるため,ロジックが大規模であればあるほど高クロックで動作させるのは難しそうというのは何となく想像できると思うが,同時に,高クロックで動作させるには,パイプライン1段あたりのロジック規模(≒トランジスタ数)をシンプルにしたほうがいいということもイメージしやすいはずだ。
ただ,パイプライン段数を多くしたほうが確かに高クロック動作には向いているのだが,今度は,もしパイプラインの各段でメモリアクセスやら条件分岐やらで実行が止まると,「パイプラインストール」(pipeline stall)と呼ばれる現象が生じ,パイプライン全体のスループット(throughput,処理量)に負の影響が出る。なので,闇雲にパイプライン段数を増やすのがよいわけではなかったりもする。
ちなみにこのあたりの議論はプロセッサ設計方針の熱いテーマであり,1990年代以降,今日(こんにち)に至るまで,プロセッサメーカーの個性が強く出ている部分だ。さて,想像できると思うが動作クロックは無限に上げられるわけではないので,プロセッサの性能を向上させようと思ったら,パイプラインの本数を増やそうという発想になる。これはつまり,演算ユニットを増やそうという上記2つの方針の,後者のアプローチに手を伸ばさざるを得ないということでもある。
ただし,パイプラインの本数を増やしていこうとすると,ロジックの規模が大きくなり,やはり消費電力の問題が立ちはだかることになる。
常識の範囲内で単純にパイプラインを増やせば,確かに性能は上がるが,パイプライン本数が多いロジックは性能向上率以上に消費電力が高くなってしまう。これは,演算ロジックの増加に合わせて,パイプラインを司どるクロック同期回路も増加してしまうためだ。
プロセッサをはじめとしたデジタル回路で,トランジスタの動作タイミングが,MHzやGHzで表される「クロック」を基準として動作していることは知っている人も多いことだろう。
ただ実のところ,トランジスタ自身はクロックと無関係に動作している。トランジスタで構成されるロジックに「さあ,ほれ,動作してくれよ」と促してくれるのがクロック同期回路だ。クロック同期回路はラッチ(Latch)回路とも呼ばれるが,これはフリップフロップ回路(flip-flop circuit,0と1で1bitの情報を保持できる回路)を根幹としており,これがないとプロセッサ内のロジックは,クロックに同期した,規律だった動作を行えない。
NVIDIAとしては,倍速クロック動作のまま演算ユニットを増やしたかったが,それをやってしまうとクロック同期回路数も増大してしまう。総合的に見て,性能向上に対する消費電力の跳ね上がり方がプロセスルールの微細化を踏まえても見逃せないレベルになってしまった……というのが,Keplerアーキテクチャの設計タイミングだったようなのだ。
そこで採用されたのが,潔く,これまでのシェーダクロック(=倍速クロック動作)を諦めるという方針で,その分,パイプラインの本数を多くする(=演算ユニットとしてのSPを多く搭載する)ことにしたというわけである。
高クロック動作を目指さないのであれば,パイプライン段数を細かくしておく必要がなく,それならクロック同期回路の数を大幅に削減でき,性能向上率に対する消費電力の増加も抑えられる。こういう事情から,Keplerアーキテクチャでは,シェーダクロックという倍速クロックがなくなったのだ。
ではなぜTesla〜Fermi世代で倍速クロックが採用されたのだろう?
NVIDIAはこの疑問に対し,「当時の製造プロセスルールだと,目標の性能を実現するために必要な演算ユニットの数を1チップに詰め込めなかったから」と回答している。つまり,限られたダイサイズで性能を高めるためには,高クロック動作させるほうが有効だと当時は判断されていたのだ。
話を戻そう。NVIDIAはGTX 680の発表にあたって,動作クロックと消費電力の相関について,ぱっと見ただけではなんだかさっぱり分からないスライドを下のとおり示している。
 |
本稿では以下,スライドにある「円の中に+がある記号」を(+),「長方形の下辺に三角形が見える記号を□と表記するが,(+)はロジック,□はクロック同期のタイミングを示している。
ここで注意したいのは,(+)の大きさが上段のFermiと下段のKeplerとで異なっている点で,Fermiではパイプライン段数が多く,クロック同期回路も含まれているため,(+)も大きく描かれているのだ。
そしてこのスライドは,「同じ製造プロセス技術で従来比2倍の性能を持つプロセッサを作ろうというときに,パイプラインステージを減らすことでクロック同期回路の数が減ったKeplerアーキテクチャの場合,ロジックの専有面積はFermiアーキテクチャをそのまま2倍化したものと比較したものと比較して1.8倍で済む」ということをまず示している。スライド中の「Logic」以下にある「1.8x」がそれだ。
そして実際には,Keplerアーキテクチャだと倍速クロックが採用されないため,消費電力は,倍速動作のFermiを1とした場合に0.9倍となり,Fermiアーキテクチャと比べて若干下がる。
また,動作クロック視点で言えば,搭載するロジック数が同じでGPUコアクロックも同じなら,KeplerアーキテクチャはFermiアーキテクチャ比で半分の消費電力になるというのも,「Clocking」以下には示されている。「Fermi 2x clock」から「Kepler 1x clock」になっているので,半分というわけだ。
疑問3:なぜ「SMX」という名前が採用されたのか
〜SMXに見る「強化」と「妥協」のポイント
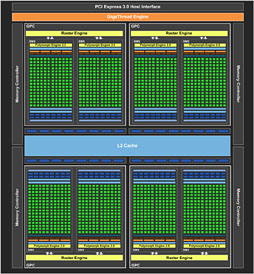
GeForce 500シリーズにおいてSPは,GTX 580(GF110)だと32基,「GeForce GTX 560 Ti」(GF114)より下位のGPUだと48基単位で管理され,「Streaming Multiprocessor」(ストリーミングマルチプロセッサ,以下 SM)を構成するような構造となっていた。さらにそれが最大4基集まって,「Graphics Processing Cluster」(以下,GPC)という“ミニGPU”を構成し,そんなGPCを最大4基搭載することにより,最大512 SP(=32×4×4)という仕様を実現しているというのは,憶えている人も少なくないだろう。
 |
 |
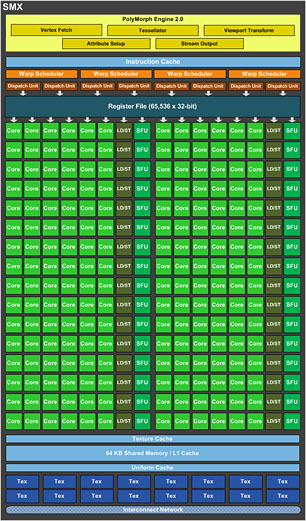
これに対しGTX 680では,GPCとSMという概念こそ変わらないながら,SMが1基あたり192基のSPを搭載する形に変更されて「Streaming Multiprocessor eXtreme」(以下,SMX)となり,それに合わせてGPCを構成するSMXの数も最大2基に変わっている。192×2×4=1536 SPという計算だ。
……というのは,あくまでもSP数にのみ焦点を当てたときの話。SMからSMXへの変更における本質は実のところ,「Warp」(ワープ)周りの変更にある。
 |
 |
WarpというのはNVIDIA製GPUにおける処理スレッド実行単位で,筆者の連載バックナンバーにある「GeForce GTX 480」の解説記事で詳しく説明しているので参考にしてほしい。
簡単に説明するなら,「1 Warp」というのはひとかたまりの32スレッドのこと。GPUでは,「複数のデータに対して1つのプログラムを同時実行する」のが基本概念なので,グラフィックスレンダリングのピクセルシェーディングステージを例に使って説明するなら,「1 Warp」(=ピクセルシェーダプログラム1命令)はピクセル32個の塊に対して適用されることになる。
このとき,Warpに対して直接的に命令を発行するのが「Instruction Dispatch Unit」(命令発行ユニット,以下日本語表記)で,その管理を行うのが「Warp Scheduler」(以下,Warpスケジューラ)だ。SPを起用する都合上,Warpスケジューラや命令発行ユニットはSM内に置かれるわけだが,GTX 580の場合,SMあたりのWarpスケジューラ数は2基で,それぞれが専用の命令発行ユニットを持っていた。つまり,SMごとに2つのWarpへ個別の命令を仕掛けることができたわけである。
それに対してGTX 680ではSMXあたりのWarpスケジューラが4基となり,しかも各Warpスケジューラが2基の命令発行ユニットを持っている。つまり,4つのWarpに対して,個別の命令実行を2つずつ仕掛けられるようになっているのだ。
GTX 580を基準に考えれば,GTX 680におけるSMXというのは,2基のSMをひとまとめにしたようなものと言ってもいい。あるいは命令実行のスループットで見れば,SMXは(依存関係などが発生しない限り)4 Warpに対して8命令同時実行をかけられるから,GTX 580のSMを4基ひとまとめにしたものという見方ができるかもしれない。
GTX 580だと,32基のSPを2命令実行に振り分けるため,1命令実行に動員できるSP数は単位時間あたり16基(32÷2)だった。一方,GTX 680では192基のSPを8命令実行に振り分けられるので,1命令実行に動員できるSP数は単位時間あたり24基(=192÷8)ということになる。
 |
疑問4:GTX 680の演算能力は
実のところGTX 580比で何倍なのか
すでに4Gamerではベンチマークテストを実行済みで,その結果もお伝えしているため,机上のスペックを語ることにそれほど深い意味はないと見る人もいるだろうが,自動車も馬力や最高時速,モード燃費など,視点を変えてみるとスペックやグレードを想像できるので,GTX 680でもやってみることにしよう。
GTX 680のSPは1基あたり2つ(2 OP)の積和演算をこなせ,またSFUは1基で4つの浮動小数点乗算(4 OP)をこなせるので,GPUのベースクロックで計算すると,浮動小数点演算演算能力は以下のとおりとなる。
- 1006MHz×(1536 SP ×2 OP+256 SFU×4 OP)≒4121 GFLOPS
GTX 680では,いよいよGPU単体で4 TFLOPSの大台へ到達したわけだ(※競合の「Radeon HD 7970」だと3.79 TFLOPS)。
ちなみに,シェーダクロックが採用される先代GTX 580だと計算式は下記のとおり。2 TFLOPS弱といったところになっている。
- 1544MHz×(512 SP×2 OP+64 SFU×4 OP)≒1976 GFLOPS
というわけで,FLOPS(FLoating-point Operations Per Second)の計算結果だと「2倍強」という,ある程度順当な結果に収まる。「新しい世代のGPUでは,従来世代比で2倍の性能を発揮させる」という,NVIDIAの昔からの公約は,少なくとも机上の計算だと守られたことになるわけだ。
ところでNVIDIAは,GTX 680でSFUをFLOPS性能値に含めない方針としている。上の計算では4121 GFLOPSだが,NVIDIAの公称値だと3090 GFLOPSだ。本稿では比較の意味合いからSFUを含めているが,NVIDIAは「より詳しいFLOPS性能値の解説は5月の『GPU Technology Conference』まで待ってほしい」と述べているので,このあたりのカラクリは5月に明らかとなるのだろう。
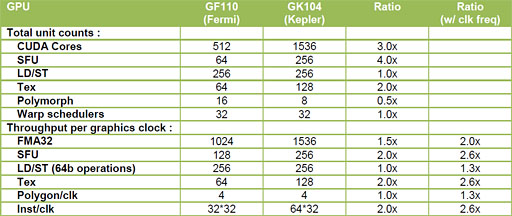
「机上のスペック話」のついでに,GTX 680のSMXとGTX 580のSMとで,SP 1基あたりのユニットバランスも計算してみよう。
 |
ロード/ストアユニットはSPからのメモリアクセス(=読み書き)を司るユニットだが,GTX 580では2基のSPが1基を共有するのに対し,GTX 680では6基のSPで共有することになるため,メモリアクセスの“渋滞”はGTX 680のほうが起こりやすくなるだろうと想像できる。
また,1基のSPが自由にできるメモリバス帯域幅で比較しても,GTX 680はGTX 580比で3分の1であり,SP数の増加分対するメモリ性能の引き上げはまったく十分でない。
キャッシュ容量が十分なら,この“渋滞”もいくらか軽減できそうなのだが,単純計算で,GTX 680が自由にできるL1キャッシュ容量はGTX 580比で6分の1,L2キャッシュ容量は4.5分の1(9分の2)しかないのだ。
さらに,テクスチャユニットも同様で,GPU全体で搭載される絶対数はGTX 580の64基に対してGTX 680は128基と2倍になっているのだが,1基のテクスチャユニットを共有するSPの数はGTX 580の8基からGTX 680で12基となっており,テクスチャユニット利用時の“渋滞”は,やはりGTX 680のほうが生じやすい。
レジスタファイルの数も,GTX 680ではSPあたりの自由度がGTX 580比で3分の1にまで下がってしまっている。
ただ,NVIDIAはこのスペックをとくに嘆いてはいない。
というのも,「3Dグラフィックスにおけるメモリアクセス」とは,テクスチャへのアクセスだったり,レンダリング結果の描画時に起こる各種バッファへの出力だったりするからだ。現在主流の解像度である1920×1080ドット程度へのレンダリングであれば,レンダーターゲットも同程度の解像度になるし,使われるテクスチャの容量なども自ずと決まってくる。なので,メモリバス帯域幅までSPのように従来製品比で3倍に引き上げる必要はないという判断が働いているのだ。
 |
ただ,GPGPU用途だと,こうした妥協はあまり歓迎されない。メモリバス帯域幅が十分で,キャッシュ容量も潤沢にあれば,より大局的なシミュレーションを高速に実行できるようになるからだ。
その意味でGTX 680(GK104)は,3Dグラフィックスに特化したGPUコアだと言うことができるだろう。
Teslaアーキテクチャ以降,とくにFermiアーキテクチャ時代におけるNVIDIAのハイエンドGPUは,GPGPU用途を主として,それにグラフィックス機能を与えたような設計になっていた。そのため,倍精度浮動小数点演算性能など,3Dグラフィックス用GPUたるGeForceとしての用途では不要な部分が多く,それが価格や3Dレンダリング性能面での足枷となっていた点が否めない。
GTX 680でNVIDIAはそのあたりを改め,絶対性能や価格対性能比で競合と戦える製品にまとめ上げてきたということなのだと思われる。
疑問5:ジオメトリエンジン数が半分に減ったのに
ジオメトリ性能が1.3倍に向上しているのはなぜか
先ほど軽く名前を出したが,DirectX 11世代のGeForceでは,ジオメトリエンジンとしてのPolyMorph Engineが用意されている。
PolyMorph Engineは,頂点シェーダやジオメトリシェーダ,ハルシェーダ,ドメインシェーダなどとしてSM&SMX内のSPを起用するときに機能するブロックだ。GeForce 400〜500シリーズを通じてSMあたり1基用意されていたが,GTX 680ではSMXあたり1基になっているので,その点での変更はなし。ただ,GPCあたりのSM数が減ったことを受けて,PolyMorph Engineの数はGTX 580の16基からGTX 680で8基に減ってしまっている。
なので,GTX 680ではジオメトリ性能が半分になってしまったような印象を持ちがちだが,NVIDIAはGTX 680で搭載されるPolyMorph Engineが,従来製品比で2倍の性能を持った「PolyMorph Engine 2.0」へと進化しているため,1秒あたりのジオメトリ処理能力に落ち込みはないとしている。というか,公称スペックを基にした机上の計算では,GTX 580が30億8800万頂点/sなのに対しGTX 680では40億2400万頂点/sなので,GPUコアクロックの引き上げ分,むしろ30%高速化したことになる。
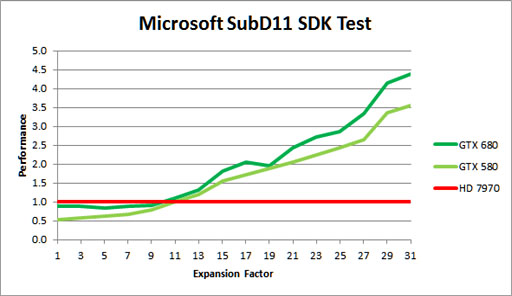 |
ではこのPolyMorph Engine 2.0で何が実現されているかだが,ブロック図レベルで違いは見られない。
NVIDIAもPolyMorph Engine 2.0についてはほとんど何も語っていないのだが,数少ない説明のなかから拾ってみると,「1クロックあたりの性能が倍になった」「SMあたりのプリミティブ(=ポリゴン)処理性能やテッセレーション性能が2倍になった」とのこと。GTX 580のSMに対して「主要ユニットを増大させて,そうでもないユニットを共有利用させる」というリファイン(?)を行ったのがGTX 680のSMXだとすれば,ジオメトリエンジンにおいても「Vertex Fetch」(頂点フェッチ)「Tessellator」(テッセレータ)「Viewport Transform」(ビューポートトランスフォーム)などといった主要ユニットを倍化し,それ以外を従来のまま据え置いた構造にしているのかもしれない。
 |
ちなみにこういった「妥協すべきところは妥協しつつ,主要ユニットを倍化する形での機能強化」というのは,競合のAMDもATI Technologies時代のATI Radeon HD 4000シリーズからATI Radeon HD 5000シリーズへの世代交代時に行っている。
疑問6:メモリ性能は下がったの?
それとも上がっているの?
 |
序盤でGTX 680のグラフィックスメモリインタフェースが256bit幅だと述べたが,グラフィックスメモリのデータレートは約6Gbps(メモリクロック6GHz相当)でグラフィックスメモリバス帯域幅は約192GB/s。GTX 580だと順に384bit幅,約4GHz,約192GB/sなので,GTX 680では,「インタフェース幅の削減分をクロックアップで挽回した」ことで,GTX 580とほぼ同じ帯域幅を確保しているといえる。
NVIDIAの公称スペックだと,テクスチャフィルレートはGTX 680が1287億6800万Texels/s,GTX 580は494億800万Texels/sと発表されている。これはそれぞれのテクスチャユニット数とGPUコアクロック/シェーダクロックを掛け合わせた結果で,実際のところ,この数字は「キャッシュに載ったテクスチャデータをテクスチャフィルタリング処理付きで読み出したときの値」だ。書き出し時の性能はテクスチャユニットの数ではなくROPユニット数に依存するため,GTX 680が321億9200万Texels/s,GTX 580が346億5600万Texels/sとなり,むしろGTX 680はGTX 580の後塵を拝してしまう。
また,L2キャッシュの総容量も,GTX 680が512KBなのに対してGTX 580は768KBだ。「メモリバス帯域幅に変わり映えなし」「ROPユニット数は削減」「L2キャッシュ容量も少ない」という,負のトリプルコンボである。
ただ,これをそのまま放置すると新世代GPUとしてのメモリスループット性能がみっともないため,NVIDIAはL2キャッシュの内部バスを効率化することで性能の改善を図っている。
具体的には,L2キャッシュのアーキテクチャを一新し,キャッシュヒット時のメモリスループットをGTX 580の384Bytes/clockからGTX 680で512Bytes/clockへと33%向上させているのだ。GTX 580の772MHzからGTX 680の1006MHzへというGPUコアクロックの向上分も加味すると,キャッシュヒット時のスループットは74%向上している計算で,最低限の面目は保てた格好になる。
 |
具体的なイメージを挙げると,「内部で再利用度の高いテクスチャや局所性の高いテクスチャをコネコネして,それらの情報を基に,従来比3倍に増えたSP群で高度な演算をギコギコガキガキと行うレンダリング手法」という感じだろうか。
昨今の高解像度テクスチャを前にするとメリットがないのではないと思うかもしれないが,偶然か必然か,最近,流行のDeferred(ディファード,遅らせた)系レンダリングエンジンや画面座標系ポストプロセスはまさに再利用度や局所性の高いテクスチャを使うイメージなので(※Deferred系レンダリングの詳細は筆者連載記事バックナンバーの「3DMark 11」解説記事を参照してほしい),「NVIDIAはこうした処理系に特化してアーキテクチャ強化を行った」と見ることはできるかもしれない。
疑問7:今回,テクニカルデモはあるの?
〜「地味だが実はすごい」新作デモが用意される
恒例,新世代GPUに合わせて発表されるテクニカルデモだが,今回は毛むくじゃらのモンスターが暴れる「Fur Demo」(毛皮デモ)と,石柱をゲーム感覚で破壊できる「Fracture Demo」(解体デモ)が用意された。
NVIDIAによれば,両デモはいずれもDirectX 11ベース。物理シミュレーション部分には「PhysX」が用いられているとのことである。
 |
 |
Fur Demoは,総数約9万9000本に上る毛の生えたモンスターが暴れると,その挙動につじつまの合った形で毛が翻弄される内容になっている。マウス操作を行うと,任意の場所に対して外力としての風を浴びせることもでき,無数の毛はその風にも影響されてなびく。これは,モンスターと毛の動作が事前計算されていたりはせず,リアルタイムでシミュレートされていることの証だ。

このデモで用いられている毛は,ラインストリップではなくポリゴンだが,「毛ポリゴン」は事前に分割されており,リアルタイムテッセレーションによって分割されているわけではない。ここはテクニカルデモとしてややパンチが弱い部分ではある。
 |
このとき,シミュレーション用の仮想パーティクルは,実際に描画されたりはせず,PhysXにて処理される。もちろん言うまでもなく,PhysXはGTX 680によるアクセラレーション動作だ。
毛パーツの挙動計算用仮想パーティクルは84万個もあり,シミュレーションはこれら84万個に対して行われる。毛は互いにめり込んだりしないことから,ちゃんと相互に衝突判定が取られていることも分かる。
柔体物理やバネ物理の類は実行されておらず,毛自体は事前分割された単位でしなやかに曲がるが伸び縮みしない。つまり,運動範囲が限定されているので,84万個の剛体物理は,隣接するローカルな毛パーツ(=仮想パーティクル)同士で行えばよく,84万個同士の総当たり計算は必要がない。逆に言えば,仮想パーティクルの物理シミュレーションは,局所的に見れば,データがキャッシュに載りやすく,膨大な数のSPを搭載するGTX 680の最大性能が活かしやすい。まさにGTX 680アーキテクチャ向けのデモだということができるのである。
 |
石柱は銃弾やボールが当たると,矛盾のない形で破片に分解される。そして分解された破片は,当然のことながらPhysXベースの剛体物理シミュレーションが適用され,ほかの破片と衝突を繰り返しながら地面に落ちていく。すごいのは,破片がシーンに残り続けるようになっており,銃撃やボールの投げつけによって,さらに細かく破壊できるようになっている点だ。
また,石柱の根本付近を破壊すれば,自壊し,ほかの破片に当たった衝撃でさらに壊れたり,ドミノ倒しのような連鎖破壊なども起こったりする。さらに,シーンをリセットしてもう一度,破壊に挑めば,その都度,違う壊れ方が披露される。地味ながら,ここも驚くべきポイントだ。
このような,毎回異なる壊れ方をするのを「ノンリニア破壊」と言ったりするが,まさにこのデモはそうした内容のものになる。
ただ,NVIDIA側がアピールしたいのは,ノンリニア破壊表現が可能ということ以上に,「この石柱モデルには一切の事前分解処理を施していない」という点のほうだ。実際,技術的にも,ここは最大のホットトピックといえるだろう。

最近のゲームではノンリニア破壊表現を採用したいるものが出てきてはいるが,そのほぼすべてで事前分解処理が行われている。
 |
 |
ダメージの受け方によっては,必ずしも最小単位パーツで壊れるわけではないし,壊れる場所や順序は,それこそダメージを受ける場所や順序によって変わってくるので,プレイヤーからは,毎回壊れ方が違う表現,すなわちノンリニア破壊に見える。
なぜ事前分割をするのか。それは,「どう分解していくのか」を事前に把握していないと,細かく壊れるたびに,動的生成される破片モデルを管理するジオメトリ量が爆発的に増えてしまい,メモリ使用量を圧迫していってしまうためだ。
たとえば,3頂点の三角形を2つの三角形に分解した場合,2倍の6頂点へと情報量は増える。これはあくまでも単純なケースだが,基本的には分割されればされた回数だけ倍々ゲームで管理すべき情報量――主にジオメトリの情報量――が増えていってしまうのである。
 |
現行世代機でも,「メタルギア ライジング リベンジェンス」(PC / PlayStation 3 / Xbox 360)などがこうした表現に挑戦しているが,本作ではことを比較的簡単にするために,あくまで直線で切断したプログレッシブ破壊に留めている。
対してこのFracture Demoでは,切断面に凹凸があり,破片の単位がプログレッシブなだけでなく,破片の形状そのものがプロシージャル(procedural,手続き的)に生成される。切断面のジオメトリ構造も相応に複雑なので,2つに割れただけでも,かなりのジオメリデータ増加になっていそうだ。
NVIDIAによると,プログレッシブ分割後に増殖したジオメトリデータもGPU側のローカルメモリ(=グラフィックスメモリ)に格納されており,衝突判定と剛体物理シミュレーション,そしてプログレッシブ破壊まで,すべての処理がGPUの中で完結しているという。
シーンが限定され,登場オブジェクトも石柱3本という限定条件付きだからこそ実現できたデモではあるものの,次世代のゲームグラフィックスをちょっとだけ先取りした感じはある。
 |
ただ,破片同士の衝突判定や剛体物理シミュレーションは,総当たり計算ではなく,衝突の可能性がある近隣のオブジェクトでグループ分けしてから局所単位ごとに並列計算を仕掛けるアプローチでよい。そう,これはちょうど,Fur Demoにおける毛皮のシミュレーションのケースと同じで,「データがキャッシュに載りやすい状況下での高密度計算」という実行モデルになっているのだ。そのため,GTX 680が持つアーキテクチャの優位性を活かせることになる。
疑問8:新たなアンチエイリアシングモード「TXAA」とは? 最近流行の「FXAA」って何?
 |
また,すでに発表済みで,採用例もいくつかあるが,業界でいま大人気のアンチエイリアシングモード「FXAA」も,Release 300から強制的な有効化が行えるようになっている。TXAAとFXAAはいずれも,DirectX 11世代のGeForceなら,GTX 680でなくても利用可能だ。
さてこのTXAAとFXAAだが,FXAAから順に少し説明してみたい。
FXAAはNVIDIAのソフトウェアエンジニアであるTimothy Lottes氏が開発した,完全なる画像ベースのアンチエイリアシング処理である。詳細はNVIDIAの開発者向けサイトで公開されているホワイトペーパー(※リンクをクリックするとpdfファイルのダウンロードが始まります)に詳しいのだが,簡単にまとめると,「レンダリング結果に対して画像解析を行い,コントラスト変移の激しい箇所をエッジと認定し,その箇所を選択的にぼかしを入れることでジャギーを低減させる手法」となっている。
FXAAは「Fast approXimate Anti-Aliasing」の略なので,意味合い上は「高速で,(一般的なアンチエイリアシング手法に)おおよそ近い(結果の得られる)アンチエイリアシング」といったところだが,実際にはポストエフェクト(effect→FX)のアンチエイリアシング(AA)といった感じで,略称主導型の命名になっているようだ。
そんなFXAAには,明らかなメリットとデメリットがある。
 |
 |
 |
Multi Sampled Anti-Aliasing(以下,MSAA)では,レンダリング解像度よりも数倍高い解像度(=サブピクセル解像度)の深度値を出力して,この情報を基にエッジ判定を行い,ぼかしを入れてジャギーを低減させる。ピクセルシェーダはレンダリング解像度のピクセル分しか稼動させないが,深度出力にあたっては数倍の解像度で出力して,さらにこれをサンプルしてエッジ判定するので,メモリバス帯域幅を相応に消費する。それに対してFXAAは,高解像度の深度値を用いないため,その分,メモリ負荷が低い。
また,FXAAではサブピクセル解像度の深度値の内容とは無関係にアンチエイリアシング処理が行われるため,MSAAではジャギーを低減できないエッジ,たとえば半透明テクスチャや透明部分を含む型抜きテクスチャのエッジに対して効くのもメリットだ。
さらに,Deferred系レンダリングというのは,深度値をレンダリング解像度で先出しし,後段で光源をレンダリングしたり,シェーディングしたりするため,「最終的なレンダリング結果としての,各ピクセルの色」がいつ決定されるか分かりようがない手法だ。それゆえ,MSAAの適用が原理的に難しいとされるが,FXAAならできあがったレンダリング結果に対して画像処理としてのアンチエイリアシングを適用できるので,Deferred系レンダリングとも相性がいい。
一方のデメリットだが,1つには,エッジ判定がサブピクセル単位ではなく,レンダリング解像度次元で行われるため,MSAAよりもボケ味の強くなる傾向があることだ。
またFXAAは,1枚1枚の独立した静止画フレームに対しては確かに高品位なジャギー低減を実現できるのものの,動画の各フレームに対して適用されたときには,時間方向に変移するボケ味がチラチラと振動して見えることがある。
その意味でFXAAは,MSAAをかけると“重く”なるような高い負荷のゲームや,Deferred系レンダリングが採用されており,MSAAを利用できないゲーム,MSAAでエッジのジャギーは低減できたが,テクスチャのディテール表現や透明&半透明表現にジャギーが目立つゲームにおける利用が向いているといえるだろう。
なおNVIDIAコントロールパネルでは「FXAA 1」と「FXAA 3」を選べるが,前者は速度よりも品質を重視したバージョン,後者は速度と品質のバランスを重視したバージョンになる。
というわけでTXAAだ。
TXAAのフルネームは「Temporal approXimate Anti-Aliasing」とされるが,「T」は「Temporal reprojection」の頭文字でもあり,Temporal reprojectionは意訳すると「時間再射影」といった感じになる。
 |
 |
 |
また,それだけでなく,「Temporal reprojection要素」も付加する。
アンチエイリアシング処理のためのボカし計算にあたって,1つ前のフレームもサンプルするのである。
もっとも,ただ何も考えずに前フレームをサンプルすると,動きの速い映像や,フレームレートが低い映像の場合,ジャギーを低減するどころか,前の映像の二重像映り(ゴースト)的なボケ味を作り出してしまう。これは「ジャギー低減のために前フレームからサンプルした箇所」が,現在のフレームとの関係がなさすぎて,何の役にも立たないときに起こる現象だ。
そこでTXAAでは,「現在のフレームにおける各ピクセルが前フレームではどこに対応するのか」が記された情報を利用して前フレームのサンプルを実施する工夫が盛り込まれている。
ちなみに,現在のフレームと前のフレームにおける対応関係というのは,画面座標系における各ピクセルの速度ベクトルがあれば分かる。モーションブラーなどのポストエフェクトで利用されるベロシティバッファ(Velocity Buffer)が一番近いイメージだろうか。
 |
 |
TXAAの選択肢はFXAAと同じく2つで,「TXAA 1」よりも「TXAA 2」のほうが高品質で描画負荷も高いという。
ところで余談になるが,FXAA的なアプローチを基軸としながら,さらなるアンチエイリアシング品質改善のためにサブピクセルレベルの深度情報を追加情報として利用する手法は,近年,いくつか発表されてきている。
TXAAととくに似ているのは,Crytekが2011年に発表したばかりの「SMAA」(Subpixel Morphological Anti-Aliasing)だ。
SMAAは,「FXAAとは別アプローチのポストエフェクトアンチエイリアシング処理の1つである『MLAA』(MorphoLogical Anti-Aliasing)をベースに,サブピクセルレベルの深度値を参照してエッジ検出を行いつつ,時間再射影を行って前フレームの内容もジャギー低減用の映像情報として利用するもの」である。……と書くと,まるでTXAAの説明をしているような気持ちになるほどだが,それほどよく似ているのだ。
なお,SMAAの根幹となっているMLAAについては,筆者の連載バックナンバーにあるRadeon HD 6800シリーズの解説記事を参照してほしい。
 |
FXAA人気が一段落した今年は,こポストエフェクトアンチエイリアシング処理にユニークな追加情報を組み入れる技法が流行していくかもしれない。
終わりに
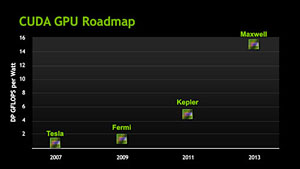
〜GPGPU向けの改良型Keplerが登場する?
ハードウェアスケジューラをソフトウェア実装化した設計方針の変更に,従来製品比で3倍の数に達する汎用シェーダユニットの搭載,その割には無茶に欲張ったりしていないジオメトリ性能強化,メモリ性能の絶対的向上よりも重視されたテクスチャユニット数の増強……といった今回のアーキテクチャ方針からは,NVIDIAがGTX 680で,GPGPUよりはゲームグラフィックスレンダリングを重視した設計にしてきたことが感じられる。
メモリ周りの性能を考えると,対応可能なレンダリング解像度はまだフルHD+α程度という感じがあるが,シェーダ(演算)パワーは潤沢なので,これからますます流行しそうなDeferred系レンダリングや画面座標系のポストエフェクト,シミュレーション規模は大きくても実効演算は局所的なものに落とし込めるような物理シミュレーションなどとの相性はよさそうだ。
ただ,GPGPUをここまで成功させてきたNVIDIAが,グラフィックスレンダリングに特化したGPUだけをリリースして満足しているわけもない。GPGPUによくハマる“改良型Keplerコア”のGPUも投入してくるに違いない。
その意味で今世代,NVIDIAは,グラフィックスレンダリング用途のGPUに関しては,これまでのワンビッグチップのウルトラハイエンド路線から,価格対性能比を重視した,AMD的な「スイートスポット戦略」にシフトしてきたという見方ができるかもしれない。
 |
果たして,NVIDIAらしい,ワン・ビッグチップは登場するのか。楽しみに待ちたい。
- 関連タイトル:
 GeForce GTX 600
GeForce GTX 600 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー