












ニュース
NVIDIA,GTC 2022でHopperベースの次世代GPU「H100」を発表。H100を組み合わせたスーパーコンピュータも登場
北米時間2022年3月22日,NVIDIAは,独自イベント「GPU Technology Conference 2022」(GTC 2022)の基調講演で,次世代GPU「H100」を発表した。頭文字の「H」は,開発コードネーム「Hopper」(ホッパー)から取ったもので,物理学者であり,計算機科学分野の研究者でもあるGrace Hopper氏に由来する。
最初に述べておくと,H100は,ゲーマーがPCで使うGPUではなく,スーパーコンピュータやデータセンター向けのGPUだ。実質的に,2020年に登場した「A100」の後継と言えよう。とはいえ,A100で採用された「Ampere」アーキテクチャが,GeForce RTX 30シリーズでも使われているように,H100も今後登場するであろう次世代のNVIDIA製GPUを想像するうえでのヒントにはなろう。そこで本稿では,基調講演で明らかとなったH100の概要をまとめてみたい。
なお,本稿執筆時点でNVIDIAは,H100の詳細な仕様のすべてを明らかにはしていないため,一部にまだ明確ではない点があることをお断りしておく。
H100は,TSMCの4nmプロセスで製造するプロセッサで,その総トランジスタ数は約800億個であるという。ちなみに,A100のダイサイズは826mm2で,総トランジスタ数は542億トランジスタであった。
CPUとの接続インタフェースには,PCI Express(以下,PCIe) 5.0を採用しており,16レーン接続での理論帯域幅は128GB/sとなる。これは,現行のPCで一般的なPCIe 4.0の2倍だ。NVIDIAは,H100のことを「世界初のPCIe5対応のGPU」とアピールしていた。
H100は,グラフィックスメモリに「HBM3」を採用しており,総容量は80GB,GPUとHBM3間のメモリ帯域幅は3TB/sに達するそうだ。冒頭に掲載したGPUパッケージの画像を見ると,GPUダイの上下に6つのHBM3スタックが見てとれよう。
6基のHBMスタック構成は,A100と同じである。ただ,A100では,6つのHBM2スタックのうち,1つを歩留まり向上のために無効化していた。今回のH100も,6つのHBM3スタックがあるのに,総容量が80GBというのは辻褄が合わない。おそらく今回も,6スタックで96GB分になるところを1スタック無効化して,5スタック分である80GBを使っているのだと推測できる。
ちなみに,メモリ技術の標準化団体であるJEDECが発表しているHBM3の仕様書によると,メモリインタフェースは1024bitで,ピンあたりの伝送速度は最大6.4Gbpsとのこと。3TB/sというH100の仕様から考察すると,1基あたりのHBM3は4.8Gbps駆動で,HBM3スタック1つあたりのメモリバス帯域幅は614.4GB/s(=4.8Gbps×1024bit)ということになりそうだ。
H100のCUDA Core数は,本稿執筆時点では明らかになっていない。ただ,GPUで理論性能値指標に用いられる単精度浮動小数点数(FP32)の演算性能値は,60 TFLOPSである。
Ampere世代のA100は,FP32の理論性能値が約20 TFLOPSで,「GeForce RTX 3090」(GA102)がすでに30 TFLOPSオーバーだった。つまりH100は,A100に対して3倍,GA102に対して約2倍のFP32性能を有するわけだ。2年ぶりに登場した新GPUとしては順当な性能向上と言えよう。
ちなみに,上のスライド中にある「TF32」は,「Tensor Flops」であり,FP32とは別物だ。TF32は,符号ビットを1bit,仮数項は半精度浮動小数点数にならった10bit,指数項を8bitとした計19bitの数値表現形式で,32bitではない。
H100におけるFP8,FP16,TF32,FP64の理論性能値が高いのは,行列演算器の集合体である推論アクセラレータ「Tensor Core」を活用した場合の性能であるためだ。このあたりの詳細については,A100登場時の解説記事を参考にしてほしい。
なお,理屈は後述するが,H100のフルスペック版はGPCが8基,製品版はGPCが7基構成と筆者は推測しており,これでFP32の理論性能値60 TFLOPSを実現するには,CUDA Core数はGA102の1.5倍程度,動作クロックはGA102の10%程度向上しているといったスペックが浮かび上がる。
ただ,報道陣による「CUDA Core総数はいくつか」という質問に対して,NVIDIAのParesh Kharya氏(Senior Director,Data Center Computing)は,「H100の訴求ポイントはそこじゃない」とはぐらかしていた。
では,H100の強化ポイントはどこにあるのだろうか。
H100における強化点の1つめは,CUDAのプログラミングモデルが「DPX」命令に対応したことが挙げられる。
DPXの“DP”は,「Dynamic Programming」(動的計画法)を示す。動的計画法は,巨大な数のデータを対象にした組み合わせ問題などを解くときに用いられる手法だ。具体的には,再帰的な手法を使うことで解けそうだが,計算が膨大になりそうな問題に対して,再帰的な処理系を複数の部分問題へと分解したうえで,分解した部分問題における各処理系の計算結果をメモリに記録,管理することで,演算量を最小限に留めながら最適解を求めるといったアルゴリズムだ。
興味がある人は,「ナップサック問題」で検索すると,具体的な実装例を目にすることができるだろう。
さて,このアルゴリズムを構築するための命令セットがDPX命令セットである。イメージ的には,SIMD命令的なものや,複雑なインデックス演算付きのメモリアクセス命令群であろう。NVIDIAとしては,DPX命令を経路探索やグラフ解析,多変量解析といった数理的な問題のほか,ゲノム配列解析などの分野にも有効と見込んでいるようだ。
H100における強化点の2つめは,Tensor Coreが8bit浮動小数点演算(FP8)に対応したことだ。地味な印象を受けるかもしれないが,実際のところ,世界のAI研究開発者には歓迎される要素になる見込みだ。簡単にバックグラウンドを解説しておこう。
2017年にコーネル大学のAshish Vaswani氏らの研究グループは,「Attention Is All You Need」(あなたに必要なのはAttentionだけ)という挑戦的なタイトルの論文を発表した(関連リンク)。ここで言うAttentionとは,言語翻訳において「入力した文章の,どの単語に注目すべきか」の評価値に相当する。
論文の主題は,言語翻訳においてCNN(Convolutional Neural Network,畳み込みニューラルネットワーク)やRNN(Recurrent Neural Network,回帰型ニューラルネットワーク)ではなく,Attentionのみで構築したAIのほうが計算量が少なく,翻訳精度も高くなり,それでいて並列計算パラダイムに向いているというものだった。
それまでの言語翻訳系AIの多くでも,Attentionの概念は導入されていた。入力した翻訳対象文章における各単語のAttention評価値を求めるのに,膨大で多様な文章事例から学習して求めた学習データを参照するアプローチを採用していたのだ。
これに対して当該論文では,翻訳対象の文章に含まれる単語だけに着目したAttention評価値を求める方針(Self-Attention,自己注意)の深層学習だけで,必要十分な精度の翻訳結果が得られることを示したのである。この論文は,言語翻訳系AIに大きなブレークスルーをもたらした。論文の手法は「Transformer」モデルと呼ばれて,発表以降,言語翻訳系AIの開発は,Transformerモデルが主流となるよう移行している。
Transformerモデルは,自然言語処理以外にも応用されるようになり,NVIDIAによると,直近2年のAI系論文の70%がTransformerモデルに関するものになったというから,興味深い。
Transformerモデルの大流行以降,Self-Attention評価値を求める処理系において「16bit浮動小数点(FP16)では冗長すぎる」という問題が浮上する。かといって,「整数8bit(INT8)ではダイナミックレンジが小さすぎる」のだ。
2019年に,IBMのXiao Sun氏らによる研究グループは,TransformerモデルのようなAI学習フェーズにおける8bit浮動小数点数の有効性を訴える論文を発表した(関連リンク)。この論文は,「推論フェーズでは8bit整数(固定小数点数)で問題はないが,学習フェーズでは8bit浮動小数点数が有効であり,精度とGPUなどの超並列プロセッサにおける演算器の有効稼働率も高い」という内容だ。おそらく,学術界の動きにNVIDIAが反応して,FP8対応機能をH100に実装したのだろう。
ちなみに,Sun氏らが論文で提唱した8bit浮動小数点数は,仮数重視の「符号1bit,指数4bit,仮数3bit」型と,指数重視の「符号1bit,指数5bit,仮数2bit」型を使い分けるハイブリッドな仕組みを提唱していたが,NVIDIAが採用したFP8の形式がどれかは,本稿執筆時点では明らかになっていない。
H100における3つめの強化点は,GPUとしては世界初となる「Hopper Confidential Computing」に対応したことだ。これはGPU内部のデータをすべて暗号化して取り扱う仕組みを実装したことを意味する。暗号化には「AES(Advanced Encryption Standard)256」規格を採用しており,H100はハードウェアベースのエンコーダ/デコーダを内蔵しているので,暗号化処理に関連した性能低下はほぼ無視できると,NVIDIAは主張している。
またCPU〜GPU間,GPU〜GPU間のやり取りでも,この仕組みを適用できるので,サーバー上のH100を多数の仮想マシンから同時に活用する場合でも,データには強力なセキュリティの保持が期待できるそうだ。
4つめの強化点は,A100で実装された機能「Multi-Instance GPU」(以下,MIG)が,H100では,さらに進化したことだ。
まずは,MIGについて簡単に説明しておこう。近年のNVIDIA製GPUは,GPUとして使える機能を一塊にまとめた「Graphics Processor Cluster」(以下,GPC)を組み合わせるデザインを採用している。NVIDIAは,A100で,GPCを独立したGPUである「仮想GPU」として利用できるようにする技術としてMIGを実装した。言うまでもなく,GPUをスーパーコンピュータやデータセンター向けサーバー,あるいはGPUサーバー的な用途で使うための技術だ。H100でも,この機能を引き続き提供している。
A100は,フルスペックではGPC 8基の構成だったが,歩留まり対策でGPC 7基構成の製品としてリリースしていたために,MIG機能では仮想的な7基のGPUがあるように見える。H100も,7基のMIGを提供すると発表されたので,逆算すると,H100もGPC 7基の構成だと推測できる。おそらく,フルスペック版ではGPC 8基なのだろう。
話をH100のMIG機能における進化点に戻すと,H100のMIGでは,7基の仮想GPUでグラフィックス描画が可能になった。近年のNVIDIA製GPUは,グラフィックス処理とGPGPU処理を兼任できるパイプラインが1本しかなく,それ以外のパイプラインはすべて,GPGPU処理専用のパイプラインとなっていた。たとえば,A100には7本のパイプラインがあるものの,GPGPU専用が6本,グラフィックス/GPGPU兼用が1本という構成で,グラフィックス処理専用のパイプラインはない。MIGモードになると,パイプラインはすべてGPGPU用になるので,グラフィックス描画は行えなかったのだ。
H100では,この制限を改善した。これによりH100では,MIG機能による仮想GPUが7基の仮想GeForceとして稼動できるようになったのだ。A100は,ビデオプロセッサ「NVENC」を1つも搭載していなかったが,H100では,なんと贅沢にも各GPCにNVENCを搭載しているという。
なおA100は,レイトレーシングユニットの「RT Core」も搭載していなかった。H100がどうなのかは,残念だが,本稿執筆時点では判明していない。
最後となる5つめの強化点は,H100に合わせて登場した第4世代「NVLink」だ。
NVLinkとは,GPUとCPU,あるいはGPUとGPUを結ぶNVIDIA独自のインターコネクト技術のこと。Pascal世代で導入され(関連記事),Volta世代で第2世代NVLink,A100で第3世代NVLinkへと進化した。A100におけるNVLinkのインタフェース帯域幅は,12リンク仕様で600GB/sだった。
今回発表となったH100向けの第4世代NVLinkは,リンク数こそ不明だがインタフェース帯域幅は900GB/sであるとのことだ。
また,H100の登場に合わせて,GPU-GPU間インターコネクト(インタフェース)技術「NVLink Switch」が発表となった。
A100以前では,よく似た名前の「NVSwitch」があったが,「NVLink Switch」は,その進化版であり,「システム間インタフェースに対応したNVSwitch」と言えよう。もっと明確に言うなら,NVLink Switchとは,NVSwitchの「Quantum-2 InfiniBand」対応版である。
コンピュータのノード間接続にはLAN(Ethernet)がよく使われるが,より高性能を求めると,低遅延でスループットの高いコンピュータネットワークが必要になる。そのため,プロセッサ間を結ぶバス技術として,たとえばPCIeのような技術をLANのようなネットワーク接続機能としてコンピュータの外に出したいということで台頭してきたのが,InfiniBandのような高速かつ超低遅延なシステム間インターコネクト技術だ。
H100のNVLinkも,最速の900GB/sで相互接続できるシステム基板(マザーボード)上での数は8基までである。これはA100のNVLinkと同じだ。しかし,NVLink Switchを活用することで,最大で256基のH100同士をNVLink接続できるようになったわけである。
以下は,NVLinkとNVSwitchの概念の違いを解説した動画だが,NVLink Switchは,この動画におけるNVSwitch部分に,Quantum-2 InfiniBand対応機能を追加した状態をイメージするといいだろう。

H100とNVLink Switchの組み合わせによって,かつてないほど大規模で超高速なGPUベースのスーパーコンピュータや,クラウドコンピューティングシステムが構築できるようになるわけだ。
今回の発表では,H100を搭載した製品群も発表となった。
1つは,H100を8基搭載したAI開発の基本システムと言える「DGX H100」だ。
もう1つは,NVLink Switchを用いてDGX H100を32基相互接続することで,計256基のH100を搭載したスーパーコンピュータシステム「DGX SuperPOD with DGX H100」である。
さらに,18台のDGX SuperPOD with DGX H100を,360基のNVLink Switchと500基のQuantum-2 InfiniBandスイッチで相互接続した巨大なスーパーコンピュータシステム「NVIDIA EOS」も発表した。NVIDIA EOSにおけるH100 GPUの総数は4608基となり,FP8で18 EFLOPS,FP64で275 PFLOPSという世界最速のAI開発向けスーパーコンピュータになるそうだ。
そのほかにも,既存のサーバーに搭載できるH100システムとして,PCIe 4.0 x16接続で使える「H100 CNX」が発表となった。これらはすべて価格は未定であるが,2022年第3四半期に発売を予定しているとのことだ。
さらにNVIDIAは,2021年に発表したArmアーキテクチャベースのサーバー向けCPU「Grace」と,今回発表となったH100と同じHopperアーキテクチャーベースのGPU(※H100そのものであるという表現は避けていた)を1パッケージにまとめた「Grace Hopper Superchip」を発表した。
また,Graceを2ダイ1パッケージにまとめた「Grace CPU Superchip」も同時に発表となっている。これらは2023年前半のリリースを予定しているそうだ。
そのほかにもNVIDIAは,Grace関連の新プロジェクトとして,他社の半導体IPをGraceに統合させるサービスを開始すると発表した。たとえば,NVIDIA以外の半導体企業が,自社チップをGraceベースのSuperchipと統合したものを製造できるようになるそうだ。
統合レベルは基板上でもいいし,インターポーザを介したダイ間接続でもいい。あるいは,ウェハレベルの統合でもいいというから,NVIDIAの本気度がうかがえる。
NVIDIA製プロセッサとの相互接続には,Armのオンチップインターコネクト技術「AMBA」や,オープン規格のダイ間インターコネクト技術「UCIe」(Universal Chiplet Interconnect Express)などを利用できるそうだ。
4Gamer読者からすると,「H100の発表を踏まえて,そのゲームグラフィックス向けのGeForce GPUがどのような姿になるのか」が気になるところだろう。
PCIe 5.0対応は確実であろうし,プラットフォームとしての一貫性を維持するためにTensor CoreのFP8対応や,CUDA CoreのDPX命令対応,AES256暗号化対応セキュリティ機能なども実装されるだろう。一方で,MIG対応などの仮想化技術やNVLinkがらみの強化は,GeForceにはあまり関係がないので採用は見送られるのではないだろうか。
いずれにせよ,近年のNVIDIAは,GPGPU版の新GPUを発表したしばらく後に新GeForceを投入することは既定路線となっているので,その日が近づいていることは間違いない。今から楽しみにしておこう。
 |
最初に述べておくと,H100は,ゲーマーがPCで使うGPUではなく,スーパーコンピュータやデータセンター向けのGPUだ。実質的に,2020年に登場した「A100」の後継と言えよう。とはいえ,A100で採用された「Ampere」アーキテクチャが,GeForce RTX 30シリーズでも使われているように,H100も今後登場するであろう次世代のNVIDIA製GPUを想像するうえでのヒントにはなろう。そこで本稿では,基調講演で明らかとなったH100の概要をまとめてみたい。
なお,本稿執筆時点でNVIDIAは,H100の詳細な仕様のすべてを明らかにはしていないため,一部にまだ明確ではない点があることをお断りしておく。
H100は800億トランジスタ。メモリは80GBのHBM3
H100は,TSMCの4nmプロセスで製造するプロセッサで,その総トランジスタ数は約800億個であるという。ちなみに,A100のダイサイズは826mm2で,総トランジスタ数は542億トランジスタであった。
CPUとの接続インタフェースには,PCI Express(以下,PCIe) 5.0を採用しており,16レーン接続での理論帯域幅は128GB/sとなる。これは,現行のPCで一般的なPCIe 4.0の2倍だ。NVIDIAは,H100のことを「世界初のPCIe5対応のGPU」とアピールしていた。
H100は,グラフィックスメモリに「HBM3」を採用しており,総容量は80GB,GPUとHBM3間のメモリ帯域幅は3TB/sに達するそうだ。冒頭に掲載したGPUパッケージの画像を見ると,GPUダイの上下に6つのHBM3スタックが見てとれよう。
6基のHBMスタック構成は,A100と同じである。ただ,A100では,6つのHBM2スタックのうち,1つを歩留まり向上のために無効化していた。今回のH100も,6つのHBM3スタックがあるのに,総容量が80GBというのは辻褄が合わない。おそらく今回も,6スタックで96GB分になるところを1スタック無効化して,5スタック分である80GBを使っているのだと推測できる。
ちなみに,メモリ技術の標準化団体であるJEDECが発表しているHBM3の仕様書によると,メモリインタフェースは1024bitで,ピンあたりの伝送速度は最大6.4Gbpsとのこと。3TB/sというH100の仕様から考察すると,1基あたりのHBM3は4.8Gbps駆動で,HBM3スタック1つあたりのメモリバス帯域幅は614.4GB/s(=4.8Gbps×1024bit)ということになりそうだ。
FP32の理論性能値は60 TFLOPS
H100のCUDA Core数は,本稿執筆時点では明らかになっていない。ただ,GPUで理論性能値指標に用いられる単精度浮動小数点数(FP32)の演算性能値は,60 TFLOPSである。
Ampere世代のA100は,FP32の理論性能値が約20 TFLOPSで,「GeForce RTX 3090」(GA102)がすでに30 TFLOPSオーバーだった。つまりH100は,A100に対して3倍,GA102に対して約2倍のFP32性能を有するわけだ。2年ぶりに登場した新GPUとしては順当な性能向上と言えよう。
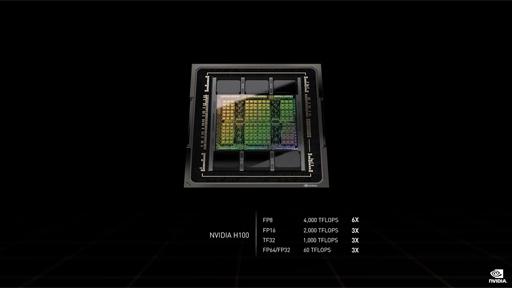 |
ちなみに,上のスライド中にある「TF32」は,「Tensor Flops」であり,FP32とは別物だ。TF32は,符号ビットを1bit,仮数項は半精度浮動小数点数にならった10bit,指数項を8bitとした計19bitの数値表現形式で,32bitではない。
H100におけるFP8,FP16,TF32,FP64の理論性能値が高いのは,行列演算器の集合体である推論アクセラレータ「Tensor Core」を活用した場合の性能であるためだ。このあたりの詳細については,A100登場時の解説記事を参考にしてほしい。
なお,理屈は後述するが,H100のフルスペック版はGPCが8基,製品版はGPCが7基構成と筆者は推測しており,これでFP32の理論性能値60 TFLOPSを実現するには,CUDA Core数はGA102の1.5倍程度,動作クロックはGA102の10%程度向上しているといったスペックが浮かび上がる。
ただ,報道陣による「CUDA Core総数はいくつか」という質問に対して,NVIDIAのParesh Kharya氏(Senior Director,Data Center Computing)は,「H100の訴求ポイントはそこじゃない」とはぐらかしていた。
では,H100の強化ポイントはどこにあるのだろうか。
H100はダイナミックプログラミングに対応した命令セット「DPX」に対応
H100における強化点の1つめは,CUDAのプログラミングモデルが「DPX」命令に対応したことが挙げられる。
DPXの“DP”は,「Dynamic Programming」(動的計画法)を示す。動的計画法は,巨大な数のデータを対象にした組み合わせ問題などを解くときに用いられる手法だ。具体的には,再帰的な手法を使うことで解けそうだが,計算が膨大になりそうな問題に対して,再帰的な処理系を複数の部分問題へと分解したうえで,分解した部分問題における各処理系の計算結果をメモリに記録,管理することで,演算量を最小限に留めながら最適解を求めるといったアルゴリズムだ。
興味がある人は,「ナップサック問題」で検索すると,具体的な実装例を目にすることができるだろう。
さて,このアルゴリズムを構築するための命令セットがDPX命令セットである。イメージ的には,SIMD命令的なものや,複雑なインデックス演算付きのメモリアクセス命令群であろう。NVIDIAとしては,DPX命令を経路探索やグラフ解析,多変量解析といった数理的な問題のほか,ゲノム配列解析などの分野にも有効と見込んでいるようだ。
 |
Tensor Coreが8bit浮動小数点数に対応。Transformer系AIの学習フェーズを加速
H100における強化点の2つめは,Tensor Coreが8bit浮動小数点演算(FP8)に対応したことだ。地味な印象を受けるかもしれないが,実際のところ,世界のAI研究開発者には歓迎される要素になる見込みだ。簡単にバックグラウンドを解説しておこう。
2017年にコーネル大学のAshish Vaswani氏らの研究グループは,「Attention Is All You Need」(あなたに必要なのはAttentionだけ)という挑戦的なタイトルの論文を発表した(関連リンク)。ここで言うAttentionとは,言語翻訳において「入力した文章の,どの単語に注目すべきか」の評価値に相当する。
論文の主題は,言語翻訳においてCNN(Convolutional Neural Network,畳み込みニューラルネットワーク)やRNN(Recurrent Neural Network,回帰型ニューラルネットワーク)ではなく,Attentionのみで構築したAIのほうが計算量が少なく,翻訳精度も高くなり,それでいて並列計算パラダイムに向いているというものだった。
それまでの言語翻訳系AIの多くでも,Attentionの概念は導入されていた。入力した翻訳対象文章における各単語のAttention評価値を求めるのに,膨大で多様な文章事例から学習して求めた学習データを参照するアプローチを採用していたのだ。
これに対して当該論文では,翻訳対象の文章に含まれる単語だけに着目したAttention評価値を求める方針(Self-Attention,自己注意)の深層学習だけで,必要十分な精度の翻訳結果が得られることを示したのである。この論文は,言語翻訳系AIに大きなブレークスルーをもたらした。論文の手法は「Transformer」モデルと呼ばれて,発表以降,言語翻訳系AIの開発は,Transformerモデルが主流となるよう移行している。
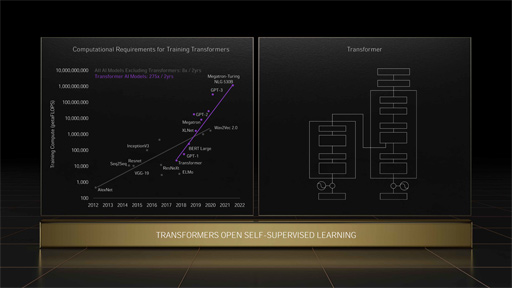
Transformerモデルは,自然言語処理以外にも応用されるようになり,NVIDIAによると,直近2年のAI系論文の70%がTransformerモデルに関するものになったというから,興味深い。
Transformerモデルの大流行以降,Self-Attention評価値を求める処理系において「16bit浮動小数点(FP16)では冗長すぎる」という問題が浮上する。かといって,「整数8bit(INT8)ではダイナミックレンジが小さすぎる」のだ。
 |
2019年に,IBMのXiao Sun氏らによる研究グループは,TransformerモデルのようなAI学習フェーズにおける8bit浮動小数点数の有効性を訴える論文を発表した(関連リンク)。この論文は,「推論フェーズでは8bit整数(固定小数点数)で問題はないが,学習フェーズでは8bit浮動小数点数が有効であり,精度とGPUなどの超並列プロセッサにおける演算器の有効稼働率も高い」という内容だ。おそらく,学術界の動きにNVIDIAが反応して,FP8対応機能をH100に実装したのだろう。
ちなみに,Sun氏らが論文で提唱した8bit浮動小数点数は,仮数重視の「符号1bit,指数4bit,仮数3bit」型と,指数重視の「符号1bit,指数5bit,仮数2bit」型を使い分けるハイブリッドな仕組みを提唱していたが,NVIDIAが採用したFP8の形式がどれかは,本稿執筆時点では明らかになっていない。
進化したH100のGPU仮想化技術
MIG機能はグラフィックス描画の仮想化にも対応
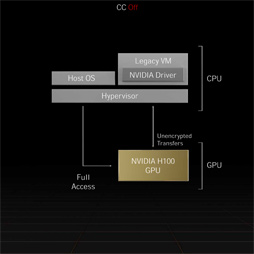
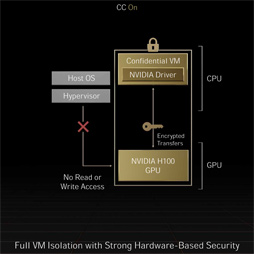
H100における3つめの強化点は,GPUとしては世界初となる「Hopper Confidential Computing」に対応したことだ。これはGPU内部のデータをすべて暗号化して取り扱う仕組みを実装したことを意味する。暗号化には「AES(Advanced Encryption Standard)256」規格を採用しており,H100はハードウェアベースのエンコーダ/デコーダを内蔵しているので,暗号化処理に関連した性能低下はほぼ無視できると,NVIDIAは主張している。
またCPU〜GPU間,GPU〜GPU間のやり取りでも,この仕組みを適用できるので,サーバー上のH100を多数の仮想マシンから同時に活用する場合でも,データには強力なセキュリティの保持が期待できるそうだ。
 |
 |
4つめの強化点は,A100で実装された機能「Multi-Instance GPU」(以下,MIG)が,H100では,さらに進化したことだ。
まずは,MIGについて簡単に説明しておこう。近年のNVIDIA製GPUは,GPUとして使える機能を一塊にまとめた「Graphics Processor Cluster」(以下,GPC)を組み合わせるデザインを採用している。NVIDIAは,A100で,GPCを独立したGPUである「仮想GPU」として利用できるようにする技術としてMIGを実装した。言うまでもなく,GPUをスーパーコンピュータやデータセンター向けサーバー,あるいはGPUサーバー的な用途で使うための技術だ。H100でも,この機能を引き続き提供している。
A100は,フルスペックではGPC 8基の構成だったが,歩留まり対策でGPC 7基構成の製品としてリリースしていたために,MIG機能では仮想的な7基のGPUがあるように見える。H100も,7基のMIGを提供すると発表されたので,逆算すると,H100もGPC 7基の構成だと推測できる。おそらく,フルスペック版ではGPC 8基なのだろう。
話をH100のMIG機能における進化点に戻すと,H100のMIGでは,7基の仮想GPUでグラフィックス描画が可能になった。近年のNVIDIA製GPUは,グラフィックス処理とGPGPU処理を兼任できるパイプラインが1本しかなく,それ以外のパイプラインはすべて,GPGPU処理専用のパイプラインとなっていた。たとえば,A100には7本のパイプラインがあるものの,GPGPU専用が6本,グラフィックス/GPGPU兼用が1本という構成で,グラフィックス処理専用のパイプラインはない。MIGモードになると,パイプラインはすべてGPGPU用になるので,グラフィックス描画は行えなかったのだ。
H100では,この制限を改善した。これによりH100では,MIG機能による仮想GPUが7基の仮想GeForceとして稼動できるようになったのだ。A100は,ビデオプロセッサ「NVENC」を1つも搭載していなかったが,H100では,なんと贅沢にも各GPCにNVENCを搭載しているという。
なおA100は,レイトレーシングユニットの「RT Core」も搭載していなかった。H100がどうなのかは,残念だが,本稿執筆時点では判明していない。
NVSwitchの進化形「NVLink Switch」
最後となる5つめの強化点は,H100に合わせて登場した第4世代「NVLink」だ。
NVLinkとは,GPUとCPU,あるいはGPUとGPUを結ぶNVIDIA独自のインターコネクト技術のこと。Pascal世代で導入され(関連記事),Volta世代で第2世代NVLink,A100で第3世代NVLinkへと進化した。A100におけるNVLinkのインタフェース帯域幅は,12リンク仕様で600GB/sだった。
今回発表となったH100向けの第4世代NVLinkは,リンク数こそ不明だがインタフェース帯域幅は900GB/sであるとのことだ。
また,H100の登場に合わせて,GPU-GPU間インターコネクト(インタフェース)技術「NVLink Switch」が発表となった。
A100以前では,よく似た名前の「NVSwitch」があったが,「NVLink Switch」は,その進化版であり,「システム間インタフェースに対応したNVSwitch」と言えよう。もっと明確に言うなら,NVLink Switchとは,NVSwitchの「Quantum-2 InfiniBand」対応版である。
コンピュータのノード間接続にはLAN(Ethernet)がよく使われるが,より高性能を求めると,低遅延でスループットの高いコンピュータネットワークが必要になる。そのため,プロセッサ間を結ぶバス技術として,たとえばPCIeのような技術をLANのようなネットワーク接続機能としてコンピュータの外に出したいということで台頭してきたのが,InfiniBandのような高速かつ超低遅延なシステム間インターコネクト技術だ。
H100のNVLinkも,最速の900GB/sで相互接続できるシステム基板(マザーボード)上での数は8基までである。これはA100のNVLinkと同じだ。しかし,NVLink Switchを活用することで,最大で256基のH100同士をNVLink接続できるようになったわけである。
以下は,NVLinkとNVSwitchの概念の違いを解説した動画だが,NVLink Switchは,この動画におけるNVSwitch部分に,Quantum-2 InfiniBand対応機能を追加した状態をイメージするといいだろう。
H100とNVLink Switchの組み合わせによって,かつてないほど大規模で超高速なGPUベースのスーパーコンピュータや,クラウドコンピューティングシステムが構築できるようになるわけだ。
H100搭載製品が多数発表へ
今回の発表では,H100を搭載した製品群も発表となった。
1つは,H100を8基搭載したAI開発の基本システムと言える「DGX H100」だ。
もう1つは,NVLink Switchを用いてDGX H100を32基相互接続することで,計256基のH100を搭載したスーパーコンピュータシステム「DGX SuperPOD with DGX H100」である。
 |
 |
さらに,18台のDGX SuperPOD with DGX H100を,360基のNVLink Switchと500基のQuantum-2 InfiniBandスイッチで相互接続した巨大なスーパーコンピュータシステム「NVIDIA EOS」も発表した。NVIDIA EOSにおけるH100 GPUの総数は4608基となり,FP8で18 EFLOPS,FP64で275 PFLOPSという世界最速のAI開発向けスーパーコンピュータになるそうだ。
 |
そのほかにも,既存のサーバーに搭載できるH100システムとして,PCIe 4.0 x16接続で使える「H100 CNX」が発表となった。これらはすべて価格は未定であるが,2022年第3四半期に発売を予定しているとのことだ。
 |
さらにNVIDIAは,2021年に発表したArmアーキテクチャベースのサーバー向けCPU「Grace」と,今回発表となったH100と同じHopperアーキテクチャーベースのGPU(※H100そのものであるという表現は避けていた)を1パッケージにまとめた「Grace Hopper Superchip」を発表した。
 |
また,Graceを2ダイ1パッケージにまとめた「Grace CPU Superchip」も同時に発表となっている。これらは2023年前半のリリースを予定しているそうだ。
 |
そのほかにもNVIDIAは,Grace関連の新プロジェクトとして,他社の半導体IPをGraceに統合させるサービスを開始すると発表した。たとえば,NVIDIA以外の半導体企業が,自社チップをGraceベースのSuperchipと統合したものを製造できるようになるそうだ。
統合レベルは基板上でもいいし,インターポーザを介したダイ間接続でもいい。あるいは,ウェハレベルの統合でもいいというから,NVIDIAの本気度がうかがえる。
NVIDIA製プロセッサとの相互接続には,Armのオンチップインターコネクト技術「AMBA」や,オープン規格のダイ間インターコネクト技術「UCIe」(Universal Chiplet Interconnect Express)などを利用できるそうだ。
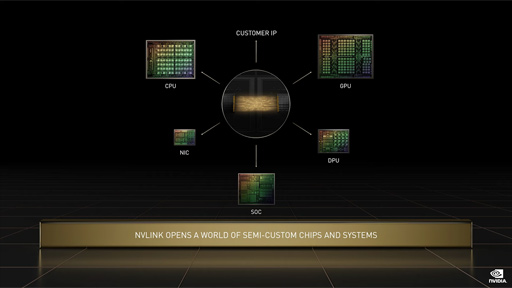 |
4Gamer読者からすると,「H100の発表を踏まえて,そのゲームグラフィックス向けのGeForce GPUがどのような姿になるのか」が気になるところだろう。
PCIe 5.0対応は確実であろうし,プラットフォームとしての一貫性を維持するためにTensor CoreのFP8対応や,CUDA CoreのDPX命令対応,AES256暗号化対応セキュリティ機能なども実装されるだろう。一方で,MIG対応などの仮想化技術やNVLinkがらみの強化は,GeForceにはあまり関係がないので採用は見送られるのではないだろうか。
いずれにせよ,近年のNVIDIAは,GPGPU版の新GPUを発表したしばらく後に新GeForceを投入することは既定路線となっているので,その日が近づいていることは間違いない。今から楽しみにしておこう。
NVIDIAのGTC 2022公式Webページ
- 関連タイトル:
 Hopper(開発コードネーム)
Hopper(開発コードネーム) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー