















ニュース
AMDの次世代を担う新CPUアーキテクチャ「Zen」の詳細を解説。IPCを40%も向上させた工夫とは
 |
だが,Zenを採用する第1弾のデスクトップPC向けCPU「Summit Ridge」(サミットリッジ,開発コードネーム)が,2016年後半,つまりそう遠くないタイミングで登場する状況になって,ようやくAMDも,マイクロアーキテクチャの詳細な情報を公開するようになってきた(関連記事)。
そこで本稿では,2016年8月に開かれた半導体関連イベント「Hot Chips 28」に合わせて説明された,Zenマイクロアーキテクチャの詳細について,従来の「Bulldozer」系マイクロアーキテクチャとの比較を行いながら説明してみたい。
 |
2011年から続くBulldozerモジュールを廃止
1基のCPUコアで2スレッドを同時実行するSMTに対応
Zenの特徴を説明する前に,簡単に現在のAMD製CPUに使われているBulldozerマイクロアーキテクチャがどのようなものであったか,簡単におさらいしておこう。
2011年10月に最初の採用CPU「FX-8150」が登場したBulldozerは,2基の整数演算ユニットが1基の浮動小数点演算ユニットを共有して1基のモジュールを構成するという,デュアルコアとシングルコアの間をとったようなアーキテクチャが特徴だった(関連記事)。
 |
この構造であれば,浮動小数点演算を扱わない命令は,実行部であるCPUコアが独立しているので2つのスレッドを同時に実行できる。一方,浮動小数点演算を扱う命令は,2つのスレッドが1つの実行ユニットを共有し,交互に浮動小数点演算命令を実行するという仕組みだった。
一般的に,プログラムには整数演算命令の割合が多く,浮動小数点演算を行わないプログラムも珍しくはない。逆に,浮動小数点演算の比率が多いプログラムであっても,整数演算命令を含まないということはありえない。そのため,Bulldozerの構造であれば,ほとんどのプログラムがデュアルコアのように動作できるという理屈だった。
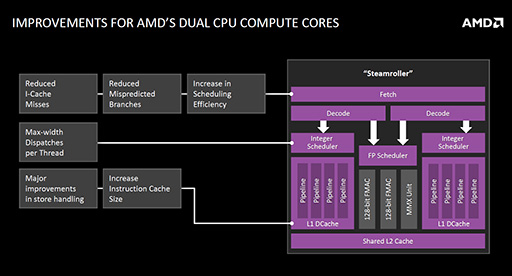
Bulldozerはその後,2012年5月に最初の製品が登場した第2世代の「Piledriver」マイクロアーキテクチャ(関連記事),2014年1月登場の第3世代「Steamroller」(関連記事)と改良が行われ続け,現在使われている最新のものは,「Excavator」と呼ばれるSteamrollerの改良版マイクロアーキテクチャとなっている。
これらも基本的にBulldozerの構造を踏襲しているのだが,x86/x64命令をCPU内部で実際に処理する「μOp」(マイクロ命令)に変換するデコーダが,モジュール全体で1基しかなかったのに対して,Steamrollerではこれを2基に増やすという改良が加えられたのが大きなトピックだった。
とはいえ,2基の整数演算ユニットと1基の浮動小数点演算ユニットで1モジュールという基本構造は,変わることなく引き継がれていたわけだ。
 |
これに対してZenマイクロアーキテクチャでは,Bulldozerのモジュール構造を廃止して,整数演算ユニットと浮動小数点演算ユニットが1対1で1つの物理CPUコアを構成する構造へと転換した。
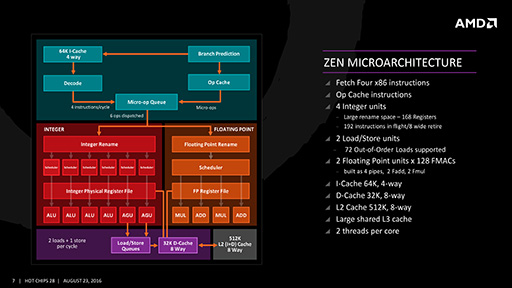 |
それに加えて,「Simultaneous Multi Threading」(同時マルチスレッディング,以下 SMT)にも対応し,1基のCPUコアで2スレッドの同時実行を可能にするという,Intel製CPUと同じような機能を採用した。
SMTに対応するCPUコアは,物理的には1基であるものの,OS側からは2つのCPUコア(論理CPUコア)に見えるので,同時に2つのスレッドを割り当てることが可能だ。内部的には,2つのスレッドを1つのCPUコアで切り替えながら実行することになる。SMTの導入により,メインメモリへのアクセスにともなう遅延が見かけ上削減されるので,実行ユニットの利用効率を上げられるわけだ。
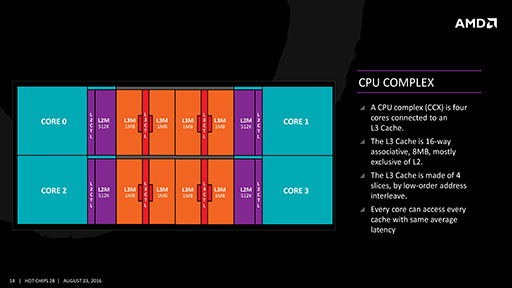 |
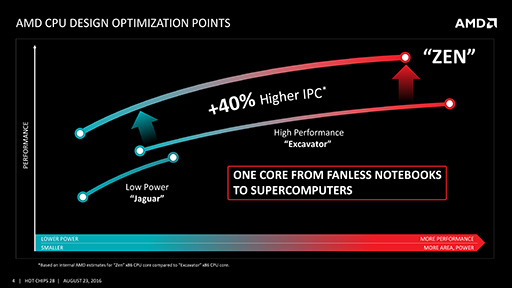
こうした改良により,Zenマイクロアーキテクチャは,ExcavatorよりもIPC
また,14nm FinFETプロセスで製造したことなどにより,電力効率も向上しており,消費電力当たりの動作クロックも向上しているという。
現在のAMD製CPUは,高性能を求めるCPU向けにExcavatorを,低消費電力を重視するCPU向けには,整数演算ユニットと浮動小数点演算ユニットが1対1でCPUコアを構成する「Jaguar」を利用している。しかし,Zenでは電力効率が向上したことによって,1つのマイクロアーキテクチャで低消費電力のモバイル向けから高性能なデスクトップPCまで,幅広い範囲をカバーできるという。
 |
CPUコアの詳細をチェック
整数演算ユニットは6個のマイクロ命令を処理可能
続いては,Zenマイクロアーキテクチャの詳細を見ていこう。
Zenマイクロアーキテクチャは,命令をメインメモリから読み出してデコードするデコーダと,整数演算ユニット,浮動小数点演算ユニット,そしてメインメモリとデータのやりとりを行うロードストアユニットの大きく4つに分かれる。
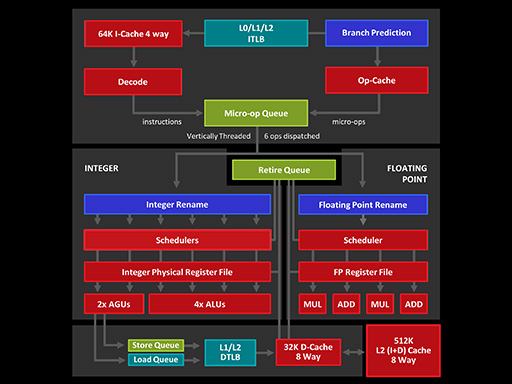 |
メインメモリからの命令読み込み(フェッチ)部は,容量64KBの命令キャッシュと分岐予測機構が組み合わさった構造となっている。
分岐予測機構には,過去に実行した分岐命令の位置や飛び先,分岐の履歴(※過去2回分)といった情報を格納する「Branch Target Buffer」(以下,BTB)がある。分岐予測機構は,BTBの情報を使って次回の分岐を予測し,確率の高いほうの命令を実行する。また,これとは別に,サブルーチン命令の戻りアドレスを記憶しておく「Indirect Target Array」(以下,ITA)というものもあり,これを使うことで,サブルーチンから高速に復帰することが可能だ。
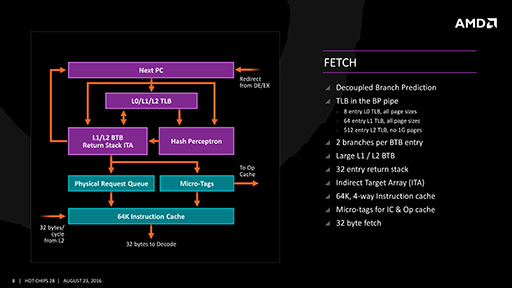 |
メインメモリから読み込まれた命令は,命令デコーダで「μOp」(マイクロ命令)に変換される。変換されたマイクロ命令は,「Op Cache」(マイクロ命令キャッシュ)に保管され,分岐による繰り返しが生じる場合には,Op Cacheからデコード済みのマイクロ命令を取り出して実行することで,デコードの繰り返しを避けるという仕組みだ。
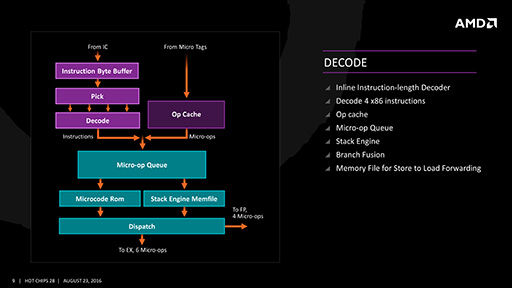 |
Steamrollerでは,独立して動作可能な2つのデコーダが,最大4命令の同時デコードを行って,2基の整数演算ユニットと1基の浮動小数点演算ユニットに命令を発行していた。
それに対してZenでは,命令の同時デコード数こそ4命令と変わらないが,整数演算ユニットに対しては,最大6マイクロ命令を同時に発行できるようになっている。ただ,浮動小数点演算ユニットに対する命令発行数は,最大4つまでとのことだ。
整数演算ユニットには,4つの「Arithmetic Logic Unit」(論理演算装置,以下 ALU)と2つの「Address Generation Unit」(アドレス生成ユニット,以下 AGU)があり,最大で6マイクロ命令を同時に処理できる。ただし,この部分は2つのスレッドで共有される仕様だ。ちなみにSteamrollerでは,1つのスレッドが2つのALUと2つのAGUを利用できた。
なお,物理レジスタは168個あり,これを必要に応じて,論理レジスタ(※x86/x64の内部レジスタ)に割り当てて利用する。
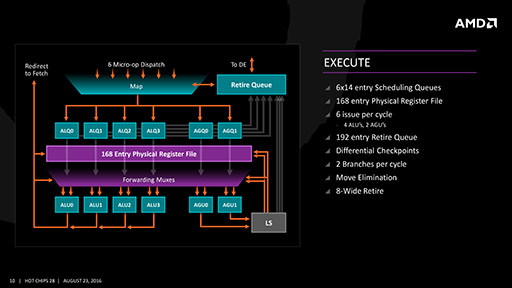 |
浮動小数点演算ユニットは,128bit演算が可能な演算器を4基内蔵している。そのうち「MUL0」と「MUL1」の2基は乗算用で,「ADD0」と「ADD1」は加算用だ。これら4基のうち,ADD0とADD1といった具合に同種のユニット2基を組み合わせることで,AVX命令の256bit演算を行う仕組みとなっている。
また,Bulldozerで実装された乗算と加算を一度に行う積和演算命令「FMA」(Fused Multiply-Add)も,乗算と加算のユニットを組み合わせることで実行可能だ。
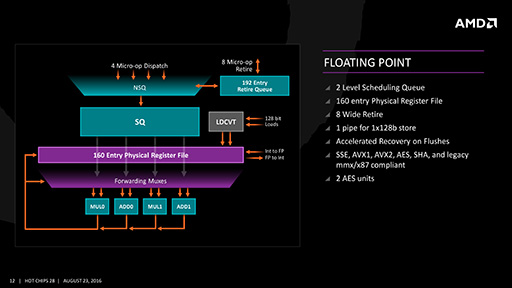 |
ロードストアユニットは,整数演算ユニット内のAGU 2基と接続されている。これは,レジスタの値などからアクセスすべきメモリアドレスを算出する必要があるため,演算命令と同様に計算を行う必要があるからだ。
処理能力としては,最大72個のロード処理と,最大44個のストア処理を受け付けることが可能である。また,容量32KBのL1データキャッシュが接続されていて,その先には命令/データ共用で容量512KBのL2キャッシュメモリがあるという構造だ。
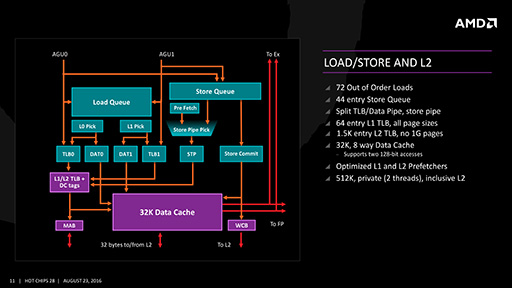 |
Zenマイクロアーキテクチャでは2つの新命令も追加
最後に,新しい命令セットについても説明しておこう。
Zenマイクロアーキテクチャでは,Intelの第5世代Coreプロセッサこと「Broadwell」以降に追加された6種類の命令に対応するのに加えて,AMD独自の命令を2つ追加している。
ただし,Broadwell以降のIntel製CPUに追加されたすべての命令に対応したわけではない。たとえば,Broadwellベースの「Xeon D」で導入されたトランザクションメモリ命令(TSX,関連記事)は,Zenが対応していない命令の1つだ。
 |
AMDが独自で追加した命令の1つである「CLZERO」は,レジスタで指定したキャッシュメモリの64byte分をクリアするものである。
メインメモリに大量にアクセスを行うプログラムで,キャッシュメモリ内にデータがあるかどうかで大きく性能差が出るような場合,不要になったデータ(エントリ)が残っていると,必要なデータを保持できない可能性が生じてしまう。そこで,CLZEROを使って不要なエントリをクリアすることで,他のキャッシュエントリを残したまま,新しいエントリを読み込めるようになるわけだ。
もう1つの新命令である「PTE Coalescing」は,仮想記憶で利用するページテーブルに関するもので,「PTE」は「Page Table Entry」の略と思われる。
動作に関する詳しい説明はなかったのだが,スライドの記述を読む限り,ページサイズが4KBのページテーブルを,ページサイズ32KBのページテーブルへと変換するものではないかと想像される。ページサイズが大きくなれば,メモリとページテーブルを変換する「TLB」(Translation Lookaside Buffer,索引変換バッファ)の利用効率が向上するので,TLBを増やさなくても,より大きなメモリ空間をカバーできるようになるからだ。
Zenマイクロアーキテクチャの変更点や特徴は,以上のとおりとなる。
半導体プロセスの変更とアーキテクチャの大幅な変更により,Zenは,IntelのハイエンドCPUと勝負になる性能を実現できるようになったと,AMDは主張している(関連記事)。もちろん,製品の実物が登場していない現状では,第三者による正当な評価ができる状態にはなく,真の実力はまだ未知数だ。
とはいえ,完全なSMT対応CPUとなったことで,Bulldozerモジュールの構造とWindows 8.x/7のスレッド割り当てアルゴリズムに齟齬が生じるといった,AMD製CPU特有の問題はなくなりそうである(関連記事)。
最初の製品であるSummit Ridgeが,一般的なPC利用だけでなく,ゲームにおいてもどの程度の実力が発揮できるのか。今は期待を込めて待ちたいと思う。
AMD 公式Webサイト(英語)
- 関連タイトル:
 Ryzen(Zen,Zen+)
Ryzen(Zen,Zen+) - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー