















連載
西川善司の3DGE:第2世代Maxwellベースの「GeForce GTX 980&970」発表。そのアーキテクチャに迫る
2014年9月18日,NVIDIAは,GeForceの最新モデルとなる「GeForce GTX 980」(以下,GTX 980)および「GeForce GTX 970」(以下,GTX 970)を発表した。Maxwellアーキテクチャに基づく新シリーズだ。
Maxwellアーキテクチャでは,「GM107」コアベースのGeForce GTX 750シリーズが2月に登場しているが,今回のGTX 980とGTX 970は,第2世代Maxwell世代の「GM204」コアベースとなっている。
本稿では,発表に先立って米国モントレー市で開催された技術説明会の内容を中心にレポートしたいと思う。
GM204は,TSMCの28nm HP(High Performance)プロセス技術を用いて製造されるプロセッサで,総トランジスタ数は52億個。ダイサイズは398mm2となる。
「GeForce GTX 680」(以下,GTX 680)や「GeForce GTX 770」で採用されたKepler世代の「GK104」コアだと,28nm HPプロセスで35.4億トランジスタを集積し,ダイサイズは294mm2。「GeForce GTX 780 Ti」(以下,GTX 780 Ti)や「GeForce GTX TITAN」などで採用された「GK110」は,28nm HPプロセスで71億トランジスタを集積しており,公式には未公開のダイサイズは実測で約550mm2となっていた。GPUコアの型番的にはGK104の後継ということになるGM204だが,そのプロセッサ規模は,GK104比で約35%大きく,GK110と比べると約70%に留まるわけである。
TSMCが20nmプロセス技術を用いてiPhone 6シリーズ用の「A8」プロセッサを製造していることは各方面で報じられているとおり。それだけに,20nmプロセス技術ではなく,28nmプロセス技術を用いてGM204が製造される点を少々意外に思う人もいるだろうが,実のところNVIDIAはここ数年,ハイエンドGPUの製造にあたって,製造プロセス技術の採択には保守的な方針を貫いてきた。それだけに,予想どおりだったと言うこともできると思う。
汎用シェーダプロセッサ「CUDA Core」の数は,GTX 980が2048基,GTX 970が1664基。GK104のフルスペックは1536基だったため,“104型番”のGPUとしては最大で約33%増えた計算になるが,GK110のフルスペックだと2880基なので,単一GPUにおけるシェーダプロセッサ数の最大数更新はお預けとなった。このあたりはGK110の後継――GM210? GM310?――までお預けいうことになる。
GPUコアのベースクロックとブーストクロックは,GTX 980が1126MHzと1216MHzで,GTX 970が1050MHzと1178MHz。1006MHzと1058MHzのGTX 680と比べると,動作クロックはかなり引き上げられたことになる。
ちなみに,公称の単精度浮動小数点演算性能値はGTX 980が5TFLOPS,GTX 470が4TFLOPSだ。
こうして見てくると,GTX 980は,GK110ベースのGeForce GTX 780シリーズやGeForce GTX TITANシリーズに対して圧倒的な性能差を見せつけるような製品ではないと,何となく分かってくるのではなかろうか。
実のところGTX 980(とGTX 970)は,Maxwellアーキテクチャの利点を活かし,性能対消費電力比(Performance per Watts)の向上を目指した製品であり,GK110ベースのGeForce GTX 700&TITANシリーズではなく,GK104ベースのGeForce GTX 600シリーズもしくはそれ以前の製品を使っている人へ向けたGPUなのである。
PCI Express補助電源コネクタが6ピン×2となり,TDP(Thermal Design Power,熱設計消費電力)が165Wに抑えられているのも,その証左といえそうだ。
ちなみに165Wというのは,GeForce 600&700系でいうと,「GeForce GTX 760」や「GeForce GTX 670」の170Wに近いスペックである。「165WというTDP値でGK110搭載のGeForce GTX 700シリーズと同等以上の性能が得られる」というのが,GTX 980における大きなアピールポイントになっている。
組み合わせられるグラフィックスメモリは,GTX 980,GTX 970とも,容量4GBのGDDR5。動作クロックは7GHz相当(実クロック1750MHz)なので,データレート的にはGTX 780 Tiと同じということになる。
ただし,グラフィックスメモリインタフェースは256bitで,ここはGTX 680から変わらず。GeForce GTX 780&TITANシリーズの384bitと比べて非常に見劣りする部分だと思う人が多いだろうが,この点にNVIDIAは対策を講じている。詳細は後段で述べたい。
というわけで,ここからはGM204のアーキテクチャを細かく見ていくことにしよう。
下に示したのが,フルスペック版GM204(=GTX 980)のブロック図である。
複数個のシェーダプロセッサに,スケジューラやロード/ストアユニット,超越関数ユニット(以下,SFU),L1キャッシュ,テクスチャユニット,そしてジオメトリエンジン「PolyMoprh Engine」を組み合わせて「Streaming Multiprocessor」(以下,SM)を構成。さらにこのSMを複数個集約させて,そこにラスタライザたる「Raster Engine」を与えて1つのミニGPUコア「Graphics Processing Cluster」(以下,GPC)として構成するアーキテクチャ自体は,NVIDIAがCUDA(Compute Unified Device Architecture)を推進するようになったTesla世代から継承するものだ。
ただ,GPCとSMの構成はTesla,Fermi,Keplerと世代ごとにマイナーチェンジされており,たとえばSMあたりのシェーダプロセッサ数は,Keplerの「SM eXtreme」(以下,SMX)だと192基だったのが,Maxwellの「Maxwell SM」(以下,SMM)では,32基のシェーダプロセッサごとにスケジューラやロード/ストアユニット,SFUとセットになったパーティションを構成し,それが4基まとまったような構成になった。
SMあたりのテクスチャユニット数がKepler世代比で半分の8基となっているのも目を引くが,このあたりはMaxwellアーキテクチャベースのGM107とGM204で共通の仕様だ。
ミニGPUたるGPCを構成するSMの数は,GK104が2基だったのに対し,GM204では4基となった。なのでGK104と比べた場合,GM204でSMあたりのシェーダプロセッサ数は約67%となったが,GPCあたりのシェーダプロセッサ数は約133%になったわけである。
その意図は,一言でまとめるなら,ジオメトリ性能の向上にある。
NVIDIAのGPUがCUDAベースになってから,SMにはジオメトリエンジンたるPolyMorph Engineが統合されるようになったという話は上で軽くしたが,GPCあたりのシェーダプロセッサ数が増えたということは,ジオメトリエンジンの数が増えたということとイコールでもある。
実際,その数はGK104が8基なのに対し,GM204では16基と,2倍だ。
ジオメトリエンジンの強化した理由についてNVIDIAは「新世代のゲームグラフィックスにおける,多ポリゴン化とテッセレーションステージ活用の積極化に対応するため」と述べている。
ところで,NVIDIAが公開したGM204のSMMブロック図を見ると,気づくことが2つある。1つは,Kepler世代のGPUやGM107では「PolyMorph Engine 2.0」だったジオメトリエンジンが,GM204で「PolyMorph Engine 3.0」になっていること。もう1つは,Kepler世代のGPUとGM107で64KBだった「Shared Memory」(共有メモリ)の容量が96KBに増量されていることだ。
実のところ,PolyMorph Engine 3.0自体に,PolyMorph Engine 2.0と比べて大きく変わったような部分はない。
一方のShared Memory増量は,テッセレーションステージの活用時,ポリゴン分割によって増えた頂点の一時保存場所が増えることとイコールになるため,より分割数の多いテッセレーションが行われた場合に高い性能を期待できるようになる。
続いて,Warp処理周りの実行効率についてチェックしてみよう。
軽く復習しておくと,NVIDIA製GPUには,処理スレッド実行単位の概念として「Warp」が存在する。詳細は筆者による「GeForce GTX 480」の解説記事を参照してほしいが,簡単にいうと,「1 Warp」はひとかたまりの32スレッドだ。
GPUでは,「複数のデータに対して1つのプログラムを同時実行する」のが基本である。分かりやすくグラフィックスレンダリングのピクセルシェーディングステージに喩えて説明するなら,「1 Warp」はピクセル32個のことで,ピクセルシェーダプログラム1命令は,このピクセル32個に対して並列に実行されるイメージになる。
そして,Kepler世代のSMXには,Warpに対して実際に命令を発行する「Instruction Dispatch Unit」(以下,命令発行ユニット)が8基,その発行管理を行う「Warp Scheduler」(以下,Warpスケジューラ)が4基用意されていた。4つのWarpに対して,個別の命令実行を2つずつ仕掛けられるようになっていたわけである。
ではMaxwellならどうかというと,Maxwell世代のSMMでも命令発行ユニットとWarpスケジューラの総数は変わらず,4つのWarpに対して,個別の命令実行を2つずつ仕掛けられる構成は同じ。ただ,1命令実行に動員できるシェーダプロセッサの数が変わっている点に注目したい。Kepler世代だと,192基のシェーダプロセッサに対して8命令実行を振り分けられたので,1命令に割り振れるシェーダプロセッサ数は単位時間あたり24基(=192÷8)だったのが,Maxwell世代では,32基のシェーダプロセッサに対して2命令実行に振り分けられるので,1命令に割り振れるシェーダプロセッサ数は単位時間あたり16基(=32÷2)となる。
実のところ,Maxwell世代における「1命令に割り振れるシェーダプロセッサ数が単位時間あたり16基」というのはFermi世代と同じだ。なので,一見するとMaxwellではKepler比で性能が下がっているようにも思えるのだが,話はそれほど単純ではない。
SM内では複数のWarp実行を同時に仕掛けており,あるWarpの命令実行においてメモリアクセスに遭遇した場合,当該メモリアクセスが完了するまでの待ち時間がもったいないため,別Warpの処理に切り換えることになる。これを「メモリアクセス時間の隠蔽」という。
なので,SM内で処理しているWarpがメモリアクセスに遭遇するたび,処理対象Warpを切り換えていけばメモリアクセスをどんどん隠蔽できるが,各Warpの実行にあたっては,データの一時保存などでレジスタファイルを消費する。ただし,当然のことながらこのレジスタファイル数は有限であり,メモリアクセス時間を次から次へと隠蔽していった結果,レジスタファイルが不足すると,当該SM内で切り替えられるWarpの数はそれ以上増やすことができなくなる。
Keplerコアでは65536個のレジスタファイルを192基のシェーダプロセッサで共有していたため,理論上は,シェーダプロセッサあたり341個(≒65536÷192)のレジスタファイルが自由になっていた。それが,Maxwellではシェーダプロセッサあたり512個(=16384÷32)のレジスタファイルが自由になるので,シェーダプロセッサあたりの「切り替えられるWarpの数」はKeplerコアよりも増える。切り替えられるWarpの数が増えれば,メモリアクセス隠蔽効率はよりよくなるので,性能は上がるという理屈である。
第1世代MaxwellベースのGeForce GTX 750シリーズが世に出たとき,NVIDIAはとくに語っていなかったのだが,Maxwellコアにはこうした設計意図が隠されていたのだ。
ここで,理論性能値を計算してみよう。
CUDAベースのNVIDIA製GPUにおいて,シェーダプロセッサは1基あたり2つ(2 OPs)の積和演算をこなせる。またSFUは1基で4つの浮動小数点乗算(4 OPs)をこなせる。そのため,GPUのベースクロック1126MHzで計算すると,GTX 980の単精度浮動小数点演算演算能力は以下のとおりとなる。計算式中の「SP」はシェーダプロセッサだ。
本稿の序盤で,GTX 980のNVIDIA公称値は5TFLOPSとしたが,それよりもずいぶんと大きな値が出てしまった。ちなみに,NVIDIAはこの計算式で求められる約4TFLOPSをGTX 680の公称理論性能値としていたのだが,GTX 980の発表にあたって,約3TFLOPSへと下方修正していたりする。
では,5TFLOPSという値は,どのように計算されているのか。「新しい計算方法ではSFUの演算能力を含めない」とのことなので,この計算式に当てはめてみると,
で,今度は公称の5TFLOPSよりも低くなってしまった。そこで,ベースクロックではなく,ブーストクロックの1216MHzを当てはめてみると,
となって,無事,公称値と一致した。
GPUメーカーは,新製品の優位性を際立たせるため,こうした「性能値の計算方法の変更」をしれっとやってくることがある。“出された数字”をただ鵜呑みにすると混乱のもとになるので,くれぐれもご注意を。
GM204におけるSMMあたりのテクスチャユニット数は,前述のとおり8基。GK104は16基なので半減した計算になるというのも前述のとおりだ。
ただし,GM204ではGPCあたりのSMM数が4基,GK104ではGPCあたりのSMX数が2基なので,GPCあたりのテクスチャユニット数は32基で変わらない。GPC数は4基なので,総数は128基となる。
一方で,大きく強化されているのが,メモリサブシステム側である。
まず,レンダリング結果をメモリに書き出したり読み込みを行ったりするROP(Rendering Output Pipeline)は,GPCあたりのユニット数がGK104比で2倍の16基に強化されている。GM204は4 GPC構成なので,全体では64基という計算になるが,これはGK110の48基をも上回る値だ。
また,L2キャッシュ容量も,GK104比で4倍となる2048KBになった。GK110は1536KBなので,ここでもGM204のスペックは際立っている。
GM204においてはさらに,レンダリング結果をメモリに書き出すための可逆(ロスレス)データ圧縮エンジンが強化されたのが大きな特徴となる。
NVIDIAは,Fermi世代で,レンダリング結果を可逆圧縮してシームレスにメモリに書き出すエンジンを搭載していた(関連記事)が,GM204ではそれがさらに進化したのだ。
NVIDIAのピクセルデータ可逆圧縮エンジンは8×8ピクセルを1単位としたブロックに対する圧縮を行うが,その圧縮アルゴリズムは,圧縮対象となる8×8ピクセルブロックを解析する,いわゆる適応型になっている。
2×4ピクセル単位でカラー値が一定ならば8分の1圧縮を行い,2×2ピクセル単位でカラー値が一定ならば4分の1圧縮を行う。
一方,これらが使えない場合は,8×8ピクセルで全ピクセルの色が異なるとことになるので,手法を切り換えて「Delta Color Compression」(差分カラー圧縮)を行うことになる。
差分カラー圧縮とは,隣接しているピクセル同士の差分(Delta)を計算して,より少ないビット数で差分値を圧縮するというもの。たとえば,あるピクセル値が200で隣のピクセル値が198だとすれば,差分は2だ。200は2進数で11001000となるため,記録するには8bitが必要だが,2(10)を記録するには2bitで済む(※この例だと圧縮率は4分の1という計算だが,実際には差分以外のデータも入れ込むことになるため,圧縮率は2分の1になる)。
GM204では,この差分カラー圧縮法を改良し,「差分を求めるときの隣接ピクセル選択アルゴリズム」を拡張したとのこと。詳細は企業秘密とのことだが,縦方向や横方向,斜め方向など,多様な隣接差分の求め方を適宜選択するようになったのではないかと思われる。具体的には,グラデーション表現などの圧縮効率を向上させているのではなかろうか。
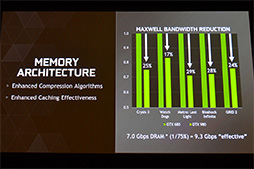
この「増量したL2キャッシュ」「進化したピクセル圧縮法」によって,GM204では,GK104比で,メモリバスの消費量を約25%低減できたとのこと。前述のとおり,GM104で組み合わされるグラフィックスメモリは動作クロック7GHz相当のものだが,「7GHz÷0.75」で,実効のメモリクロックは9.3GHz相当だと,NVIDIAは主張している。256bitメモリインタフェースで7GHz相当だと,メモリバス幅は224.0GB/sだが,9.3GHz相当であれば297.6GB/sであり,GTX 780 Tiの384bitで7GHzの336.0GB/sに迫るというわけだ。
そのほか,GM204では,ディスプレイ出力周りやビデオエンジン周りにもアップデートが入っている。
最大のトピックは,HDMI 2.0の完全対応だろう。これでやっと,4K/60Hz(3840×2160ドット,60fps)出力を,色解像度を落としたりすることなくHDMIで伝送できるようになった。NVIDIAは,Kepler世代のGeForceでも,ドライバソフトウェア「GeForce Driver」の機能として,色解像度を落としたYCbCr=4:2:0フォーマットで4K/60Hz出力を可能にしていたが(関連記事),この方式では,輝度差の少ないドット単位の表現で著しく解像感が低下してしまうため,(実写系映像はともかく)図版や文字主体のデスクトップ表示はつらかった。その意味で,“ごまかしなし”のフルカラー60fpsでHDMIによる4K出力が可能になったことは素直に喜ばしい。NVIDIAは,このHDMI 2.0完全対応を「業界初」だとアピールしている。
DisplayPort規格の対応は,VESAが最近策定した1.3ではなく,1.2のままだが,MST(Multi Stream Transport)によるタイル(Tiled)表示モードを駆使することで,5120×3200ドットの60Hz出力をサポートする。Dellが発表した“5K”ディスプレイUltraSharp 27 Ultra HD 5K Monitor」の5120×2880ドットにも,これで対応できるのではなかろうか。
なお,同時出力画面数は4枚(3枚+1枚)で,これはKeplerから変更ない。
一方のビデオエンジン周りでは,リアルタイムビデオエンコーダ「NVENC」が刷新され,業界で初めてH.265(HEVC:High Efficiency Video Coding)対応エンコーダとなったことが発表されている。Kepler世代のGPUに統合されるNVENCでは,Blu-ray Discなどで採用されるH.264(MPEG4-AVC)エンコーダが統合されていたが,GM204に統合されるものは,それよりも世代が新しくなったわけだ。
H.265はもともと,4K映像や8K映像のために開発されたエンコード方式で,H.264に対して「同一画質で半分のビットレート」「同一ビットレートで画質2倍」の性能を持っている。そんなH.265に対応するNVENCにより,NVIDIA独自のリアルタイム録画システム「ShadowPlay」が,ついに4K/60fpsをサポートするようになるのである。
なお,GM204のNVENCでは,H.264エンコード性能も強化され,Kepler世代のそれに対して約2.5倍のスループット性能を持つに至っているという。この高性能化されたH.264エンコード性能を何に活用するつもりなのか,NVIDIAは明らかにしていないが,複数のビデオストリームを同時にリアルタイム圧縮することなどに応用して,ゲームのストリーミングプレイ機能「GameStream」における同時多視点複数プレイヤー対応などを計るのではなかろうか。
以上,第2世代MaxwellとなるGM204のハードウェア概要をまとめてみた。4Gamerでは同時にレビュー記事も掲載しているので,興味のある人はぜひそちらもチェックしてほしいと思うが,技術説明会ではこのほかにもGM204の新要素がいくつか明らかになっている。
たとえば,ゲーム開発者向けフレームワークであるGameWorksに含まれるリアルタイム大局照明(Global Illumination,大域照明ともいう)ライブラリ「GI Works」の高速化機能がその1つだ。GI Worksは,一部の国でよくない意味があると分かったため,GeForce GTX 900シリーズの発表を機に「VoXel Global Illumination」(VXGI)へと名称が変更されたが,その高速化機能「Multi-Projection Acceleration」「Conservative Raster」が,GM204には搭載されている。
Multi-Projection Accelerationは,近年の影生成技法の主流方式である「Cascaded Shadow Maps」技法のアクセラレーションにも応用できるというもの。Conservative Rasterは「保守的なラスタライゼーション」と和訳されるラスタライズ手法。ボクセル化処理には必須のものだが,これも加速化できるようになるわけだ。
また,これまでNVIDIAが力を入れてきた時間方向のアンチエイリアシング手法「TXAA」とは別の,より軽量な手法として,「MFAA」(Multi Frame Anti-Aliasing)の採用もアナウンスされた。GeForce GTX 900シリーズの発売には間に合わないため,追ってGeForce Driverのアップデートで有効化される本機能。その実現には,GM204に搭載された「Multi-Pixel Programmable Sampling」機能を利用しているとのことだ。
やや高度な機能になるが,ピクセルシェーダの拡張機能である「Raster Ordered View」(ROV)もGM204の新要素として紹介されている。
Raster Ordered Viewとは,具体的には,「画面座標系の同一X,Yに対して複数のピクセル描画が行われたとき,その書き出し順序に対してルールを規定できる」もの。実際の応用先としては,半透明オブジェクトの順不同描画や高度なプログラマブルブレンディングなどが挙げられるだろう。
GM204技術説明会には,MicrosoftでDirectX(Direct3D)の実質的な開発リーダーを務めるMax McMullen氏も登壇し,DirectX 11.3の登場を予告したのだが,そこで氏の口からは,GM204のConserveative RasterとRaster Ordered ViewがDirectX 11.3に採用されることも明らかになっている。
将来的にはKepler世代コアのGeForceにもサポートが拡張されるかもしれないが,当面はGM204独自の機能となる「Dynamic Super Resolution」(DSR)も,なかなか面白い。これは,いったん高解像度でレンダリングして,その後で低解像度にスーパーサンプリングして表示するというものだ。10年以上昔,3Dfxが「FSAA」(フルスクリーンアンチエイリアシング)として訴求していた高画質化レンダリング技法と,概念はよく似たものになっている。
いま概要だけ紹介したGM204の関連要素は,稿をあらためて詳しく解説したいと思う。
Maxwellアーキテクチャでは,「GM107」コアベースのGeForce GTX 750シリーズが2月に登場しているが,今回のGTX 980とGTX 970は,第2世代Maxwell世代の「GM204」コアベースとなっている。
 |
 |
本稿では,発表に先立って米国モントレー市で開催された技術説明会の内容を中心にレポートしたいと思う。
 |
 |
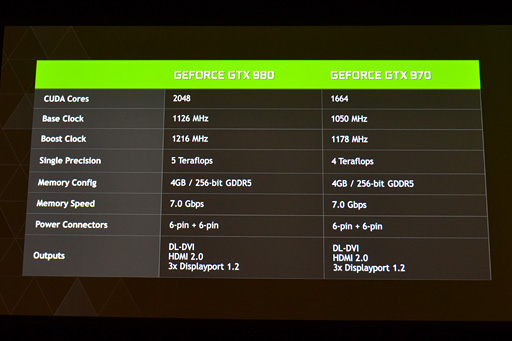
GeForce GTX 900のスペック概要
 |
「GeForce GTX 680」(以下,GTX 680)や「GeForce GTX 770」で採用されたKepler世代の「GK104」コアだと,28nm HPプロセスで35.4億トランジスタを集積し,ダイサイズは294mm2。「GeForce GTX 780 Ti」(以下,GTX 780 Ti)や「GeForce GTX TITAN」などで採用された「GK110」は,28nm HPプロセスで71億トランジスタを集積しており,公式には未公開のダイサイズは実測で約550mm2となっていた。GPUコアの型番的にはGK104の後継ということになるGM204だが,そのプロセッサ規模は,GK104比で約35%大きく,GK110と比べると約70%に留まるわけである。
 |
 |
 |
 |
 |
GPUコアのベースクロックとブーストクロックは,GTX 980が1126MHzと1216MHzで,GTX 970が1050MHzと1178MHz。1006MHzと1058MHzのGTX 680と比べると,動作クロックはかなり引き上げられたことになる。
ちなみに,公称の単精度浮動小数点演算性能値はGTX 980が5TFLOPS,GTX 470が4TFLOPSだ。
 |
こうして見てくると,GTX 980は,GK110ベースのGeForce GTX 780シリーズやGeForce GTX TITANシリーズに対して圧倒的な性能差を見せつけるような製品ではないと,何となく分かってくるのではなかろうか。
実のところGTX 980(とGTX 970)は,Maxwellアーキテクチャの利点を活かし,性能対消費電力比(Performance per Watts)の向上を目指した製品であり,GK110ベースのGeForce GTX 700&TITANシリーズではなく,GK104ベースのGeForce GTX 600シリーズもしくはそれ以前の製品を使っている人へ向けたGPUなのである。
PCI Express補助電源コネクタが6ピン×2となり,TDP(Thermal Design Power,熱設計消費電力)が165Wに抑えられているのも,その証左といえそうだ。
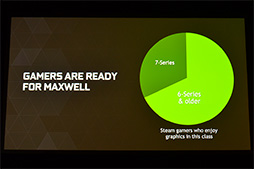 Valveのゲーム配信システム「Steam」で集計されたデータより,Steamユーザーが使っているGeForceの世代分布。GeForce GTX 900シリーズは,GeForce GTX 600シリーズや,それ以前のGeForceを使っている,大多数のゲーマーに向けて訴求されることになる |
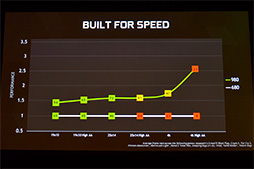 GTX 980とGTX 680の性能比較。最近の3Dゲームタイトルにおける平均フレームレートと解像度とアンチエイリアンシグ設定でプロットした結果で,おおむね1.5倍の性能向上率が得られている。シェーダプロセッサ数と動作クロック数の違いを踏まえるに,ほぼ妥当な結果だ |
ちなみに165Wというのは,GeForce 600&700系でいうと,「GeForce GTX 760」や「GeForce GTX 670」の170Wに近いスペックである。「165WというTDP値でGK110搭載のGeForce GTX 700シリーズと同等以上の性能が得られる」というのが,GTX 980における大きなアピールポイントになっている。
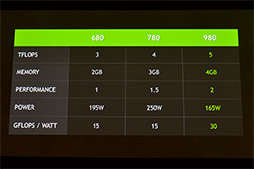 NVIDIAがかつて出したGPUとで性能を相対比較した表 |
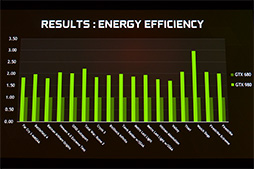 GTX 980とGTX 680の消費電力効率。おおむね2倍に向上しているとされる |
組み合わせられるグラフィックスメモリは,GTX 980,GTX 970とも,容量4GBのGDDR5。動作クロックは7GHz相当(実クロック1750MHz)なので,データレート的にはGTX 780 Tiと同じということになる。
ただし,グラフィックスメモリインタフェースは256bitで,ここはGTX 680から変わらず。GeForce GTX 780&TITANシリーズの384bitと比べて非常に見劣りする部分だと思う人が多いだろうが,この点にNVIDIAは対策を講じている。詳細は後段で述べたい。
強化されたジオメトリエンジン
というわけで,ここからはGM204のアーキテクチャを細かく見ていくことにしよう。
下に示したのが,フルスペック版GM204(=GTX 980)のブロック図である。
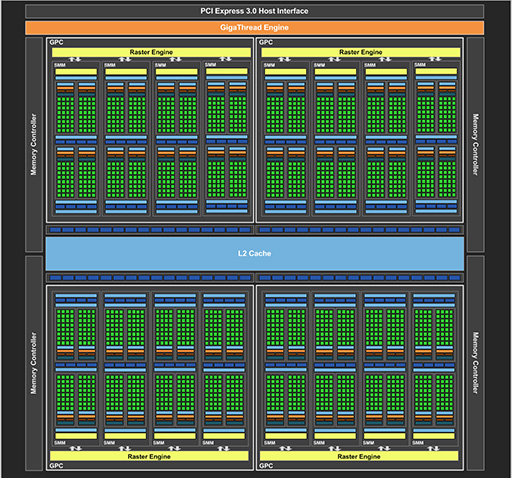 |
複数個のシェーダプロセッサに,スケジューラやロード/ストアユニット,超越関数ユニット(以下,SFU),L1キャッシュ,テクスチャユニット,そしてジオメトリエンジン「PolyMoprh Engine」を組み合わせて「Streaming Multiprocessor」(以下,SM)を構成。さらにこのSMを複数個集約させて,そこにラスタライザたる「Raster Engine」を与えて1つのミニGPUコア「Graphics Processing Cluster」(以下,GPC)として構成するアーキテクチャ自体は,NVIDIAがCUDA(Compute Unified Device Architecture)を推進するようになったTesla世代から継承するものだ。
ただ,GPCとSMの構成はTesla,Fermi,Keplerと世代ごとにマイナーチェンジされており,たとえばSMあたりのシェーダプロセッサ数は,Keplerの「SM eXtreme」(以下,SMX)だと192基だったのが,Maxwellの「Maxwell SM」(以下,SMM)では,32基のシェーダプロセッサごとにスケジューラやロード/ストアユニット,SFUとセットになったパーティションを構成し,それが4基まとまったような構成になった。
SMあたりのテクスチャユニット数がKepler世代比で半分の8基となっているのも目を引くが,このあたりはMaxwellアーキテクチャベースのGM107とGM204で共通の仕様だ。
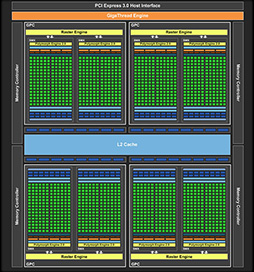 GK104のブロック図(参考) |
 GM107のブロック図(参考) |
ミニGPUたるGPCを構成するSMの数は,GK104が2基だったのに対し,GM204では4基となった。なのでGK104と比べた場合,GM204でSMあたりのシェーダプロセッサ数は約67%となったが,GPCあたりのシェーダプロセッサ数は約133%になったわけである。
その意図は,一言でまとめるなら,ジオメトリ性能の向上にある。
NVIDIAのGPUがCUDAベースになってから,SMにはジオメトリエンジンたるPolyMorph Engineが統合されるようになったという話は上で軽くしたが,GPCあたりのシェーダプロセッサ数が増えたということは,ジオメトリエンジンの数が増えたということとイコールでもある。
実際,その数はGK104が8基なのに対し,GM204では16基と,2倍だ。
ジオメトリエンジンの強化した理由についてNVIDIAは「新世代のゲームグラフィックスにおける,多ポリゴン化とテッセレーションステージ活用の積極化に対応するため」と述べている。
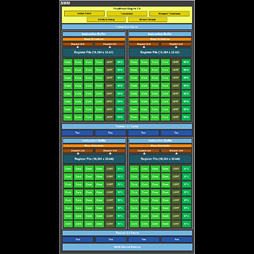 |
実のところ,PolyMorph Engine 3.0自体に,PolyMorph Engine 2.0と比べて大きく変わったような部分はない。
一方のShared Memory増量は,テッセレーションステージの活用時,ポリゴン分割によって増えた頂点の一時保存場所が増えることとイコールになるため,より分割数の多いテッセレーションが行われた場合に高い性能を期待できるようになる。
MaxwellではなぜSMの構成が変更されたのか
続いて,Warp処理周りの実行効率についてチェックしてみよう。
軽く復習しておくと,NVIDIA製GPUには,処理スレッド実行単位の概念として「Warp」が存在する。詳細は筆者による「GeForce GTX 480」の解説記事を参照してほしいが,簡単にいうと,「1 Warp」はひとかたまりの32スレッドだ。
GPUでは,「複数のデータに対して1つのプログラムを同時実行する」のが基本である。分かりやすくグラフィックスレンダリングのピクセルシェーディングステージに喩えて説明するなら,「1 Warp」はピクセル32個のことで,ピクセルシェーダプログラム1命令は,このピクセル32個に対して並列に実行されるイメージになる。
そして,Kepler世代のSMXには,Warpに対して実際に命令を発行する「Instruction Dispatch Unit」(以下,命令発行ユニット)が8基,その発行管理を行う「Warp Scheduler」(以下,Warpスケジューラ)が4基用意されていた。4つのWarpに対して,個別の命令実行を2つずつ仕掛けられるようになっていたわけである。
ではMaxwellならどうかというと,Maxwell世代のSMMでも命令発行ユニットとWarpスケジューラの総数は変わらず,4つのWarpに対して,個別の命令実行を2つずつ仕掛けられる構成は同じ。ただ,1命令実行に動員できるシェーダプロセッサの数が変わっている点に注目したい。Kepler世代だと,192基のシェーダプロセッサに対して8命令実行を振り分けられたので,1命令に割り振れるシェーダプロセッサ数は単位時間あたり24基(=192÷8)だったのが,Maxwell世代では,32基のシェーダプロセッサに対して2命令実行に振り分けられるので,1命令に割り振れるシェーダプロセッサ数は単位時間あたり16基(=32÷2)となる。
実のところ,Maxwell世代における「1命令に割り振れるシェーダプロセッサ数が単位時間あたり16基」というのはFermi世代と同じだ。なので,一見するとMaxwellではKepler比で性能が下がっているようにも思えるのだが,話はそれほど単純ではない。
SM内では複数のWarp実行を同時に仕掛けており,あるWarpの命令実行においてメモリアクセスに遭遇した場合,当該メモリアクセスが完了するまでの待ち時間がもったいないため,別Warpの処理に切り換えることになる。これを「メモリアクセス時間の隠蔽」という。
なので,SM内で処理しているWarpがメモリアクセスに遭遇するたび,処理対象Warpを切り換えていけばメモリアクセスをどんどん隠蔽できるが,各Warpの実行にあたっては,データの一時保存などでレジスタファイルを消費する。ただし,当然のことながらこのレジスタファイル数は有限であり,メモリアクセス時間を次から次へと隠蔽していった結果,レジスタファイルが不足すると,当該SM内で切り替えられるWarpの数はそれ以上増やすことができなくなる。
Keplerコアでは65536個のレジスタファイルを192基のシェーダプロセッサで共有していたため,理論上は,シェーダプロセッサあたり341個(≒65536÷192)のレジスタファイルが自由になっていた。それが,Maxwellではシェーダプロセッサあたり512個(=16384÷32)のレジスタファイルが自由になるので,シェーダプロセッサあたりの「切り替えられるWarpの数」はKeplerコアよりも増える。切り替えられるWarpの数が増えれば,メモリアクセス隠蔽効率はよりよくなるので,性能は上がるという理屈である。
第1世代MaxwellベースのGeForce GTX 750シリーズが世に出たとき,NVIDIAはとくに語っていなかったのだが,Maxwellコアにはこうした設計意図が隠されていたのだ。
理論性能値の比較〜変更された理論性能値の計算方法
ここで,理論性能値を計算してみよう。
CUDAベースのNVIDIA製GPUにおいて,シェーダプロセッサは1基あたり2つ(2 OPs)の積和演算をこなせる。またSFUは1基で4つの浮動小数点乗算(4 OPs)をこなせる。そのため,GPUのベースクロック1126MHzで計算すると,GTX 980の単精度浮動小数点演算演算能力は以下のとおりとなる。計算式中の「SP」はシェーダプロセッサだ。
1126MHz×(2048 SP×2 OPs+512 SFU×4 OPs)≒6918GFLOPS
本稿の序盤で,GTX 980のNVIDIA公称値は5TFLOPSとしたが,それよりもずいぶんと大きな値が出てしまった。ちなみに,NVIDIAはこの計算式で求められる約4TFLOPSをGTX 680の公称理論性能値としていたのだが,GTX 980の発表にあたって,約3TFLOPSへと下方修正していたりする。
では,5TFLOPSという値は,どのように計算されているのか。「新しい計算方法ではSFUの演算能力を含めない」とのことなので,この計算式に当てはめてみると,
1126MHz×(2048 SP ×2 OP)≒4612 GFLOPS
で,今度は公称の5TFLOPSよりも低くなってしまった。そこで,ベースクロックではなく,ブーストクロックの1216MHzを当てはめてみると,
1216MHz×(2048 SP ×2 OP)≒4980 GFLOPS
となって,無事,公称値と一致した。
GPUメーカーは,新製品の優位性を際立たせるため,こうした「性能値の計算方法の変更」をしれっとやってくることがある。“出された数字”をただ鵜呑みにすると混乱のもとになるので,くれぐれもご注意を。
テクスチャユニットとメモリサブシステム
GM204におけるSMMあたりのテクスチャユニット数は,前述のとおり8基。GK104は16基なので半減した計算になるというのも前述のとおりだ。
ただし,GM204ではGPCあたりのSMM数が4基,GK104ではGPCあたりのSMX数が2基なので,GPCあたりのテクスチャユニット数は32基で変わらない。GPC数は4基なので,総数は128基となる。
一方で,大きく強化されているのが,メモリサブシステム側である。
まず,レンダリング結果をメモリに書き出したり読み込みを行ったりするROP(Rendering Output Pipeline)は,GPCあたりのユニット数がGK104比で2倍の16基に強化されている。GM204は4 GPC構成なので,全体では64基という計算になるが,これはGK110の48基をも上回る値だ。
また,L2キャッシュ容量も,GK104比で4倍となる2048KBになった。GK110は1536KBなので,ここでもGM204のスペックは際立っている。
GM204においてはさらに,レンダリング結果をメモリに書き出すための可逆(ロスレス)データ圧縮エンジンが強化されたのが大きな特徴となる。
NVIDIAは,Fermi世代で,レンダリング結果を可逆圧縮してシームレスにメモリに書き出すエンジンを搭載していた(関連記事)が,GM204ではそれがさらに進化したのだ。
NVIDIAのピクセルデータ可逆圧縮エンジンは8×8ピクセルを1単位としたブロックに対する圧縮を行うが,その圧縮アルゴリズムは,圧縮対象となる8×8ピクセルブロックを解析する,いわゆる適応型になっている。
 |
一方,これらが使えない場合は,8×8ピクセルで全ピクセルの色が異なるとことになるので,手法を切り換えて「Delta Color Compression」(差分カラー圧縮)を行うことになる。
差分カラー圧縮とは,隣接しているピクセル同士の差分(Delta)を計算して,より少ないビット数で差分値を圧縮するというもの。たとえば,あるピクセル値が200で隣のピクセル値が198だとすれば,差分は2だ。200は2進数で11001000となるため,記録するには8bitが必要だが,2(10)を記録するには2bitで済む(※この例だと圧縮率は4分の1という計算だが,実際には差分以外のデータも入れ込むことになるため,圧縮率は2分の1になる)。
GM204では,この差分カラー圧縮法を改良し,「差分を求めるときの隣接ピクセル選択アルゴリズム」を拡張したとのこと。詳細は企業秘密とのことだが,縦方向や横方向,斜め方向など,多様な隣接差分の求め方を適宜選択するようになったのではないかと思われる。具体的には,グラデーション表現などの圧縮効率を向上させているのではなかろうか。
 |
 |
 |
4Kへの本格対応に乗りだしたNVIDIA
HDMI 2.0完全対応!
そのほか,GM204では,ディスプレイ出力周りやビデオエンジン周りにもアップデートが入っている。
最大のトピックは,HDMI 2.0の完全対応だろう。これでやっと,4K/60Hz(3840×2160ドット,60fps)出力を,色解像度を落としたりすることなくHDMIで伝送できるようになった。NVIDIAは,Kepler世代のGeForceでも,ドライバソフトウェア「GeForce Driver」の機能として,色解像度を落としたYCbCr=4:2:0フォーマットで4K/60Hz出力を可能にしていたが(関連記事),この方式では,輝度差の少ないドット単位の表現で著しく解像感が低下してしまうため,(実写系映像はともかく)図版や文字主体のデスクトップ表示はつらかった。その意味で,“ごまかしなし”のフルカラー60fpsでHDMIによる4K出力が可能になったことは素直に喜ばしい。NVIDIAは,このHDMI 2.0完全対応を「業界初」だとアピールしている。
DisplayPort規格の対応は,VESAが最近策定した1.3ではなく,1.2のままだが,MST(Multi Stream Transport)によるタイル(Tiled)表示モードを駆使することで,5120×3200ドットの60Hz出力をサポートする。Dellが発表した“5K”ディスプレイUltraSharp 27 Ultra HD 5K Monitor」の5120×2880ドットにも,これで対応できるのではなかろうか。
なお,同時出力画面数は4枚(3枚+1枚)で,これはKeplerから変更ない。
一方のビデオエンジン周りでは,リアルタイムビデオエンコーダ「NVENC」が刷新され,業界で初めてH.265(HEVC:High Efficiency Video Coding)対応エンコーダとなったことが発表されている。Kepler世代のGPUに統合されるNVENCでは,Blu-ray Discなどで採用されるH.264(MPEG4-AVC)エンコーダが統合されていたが,GM204に統合されるものは,それよりも世代が新しくなったわけだ。
H.265はもともと,4K映像や8K映像のために開発されたエンコード方式で,H.264に対して「同一画質で半分のビットレート」「同一ビットレートで画質2倍」の性能を持っている。そんなH.265に対応するNVENCにより,NVIDIA独自のリアルタイム録画システム「ShadowPlay」が,ついに4K/60fpsをサポートするようになるのである。
なお,GM204のNVENCでは,H.264エンコード性能も強化され,Kepler世代のそれに対して約2.5倍のスループット性能を持つに至っているという。この高性能化されたH.264エンコード性能を何に活用するつもりなのか,NVIDIAは明らかにしていないが,複数のビデオストリームを同時にリアルタイム圧縮することなどに応用して,ゲームのストリーミングプレイ機能「GameStream」における同時多視点複数プレイヤー対応などを計るのではなかろうか。
まだまだある第2世代Maxwell関連トピック
以上,第2世代MaxwellとなるGM204のハードウェア概要をまとめてみた。4Gamerでは同時にレビュー記事も掲載しているので,興味のある人はぜひそちらもチェックしてほしいと思うが,技術説明会ではこのほかにもGM204の新要素がいくつか明らかになっている。
 |
 |
 |
 |
 |
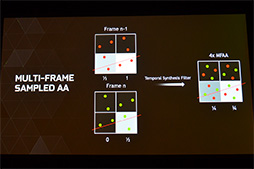
また,これまでNVIDIAが力を入れてきた時間方向のアンチエイリアシング手法「TXAA」とは別の,より軽量な手法として,「MFAA」(Multi Frame Anti-Aliasing)の採用もアナウンスされた。GeForce GTX 900シリーズの発売には間に合わないため,追ってGeForce Driverのアップデートで有効化される本機能。その実現には,GM204に搭載された「Multi-Pixel Programmable Sampling」機能を利用しているとのことだ。
 |
 |
 |
Raster Ordered Viewとは,具体的には,「画面座標系の同一X,Yに対して複数のピクセル描画が行われたとき,その書き出し順序に対してルールを規定できる」もの。実際の応用先としては,半透明オブジェクトの順不同描画や高度なプログラマブルブレンディングなどが挙げられるだろう。
 Max McMullen氏(Direct3D, Develpment Lead, Microsoft) |
 DSRは,高解像度でレンダリングし,これからスーパーサンプリングして表示解像度を得る方式 |
将来的にはKepler世代コアのGeForceにもサポートが拡張されるかもしれないが,当面はGM204独自の機能となる「Dynamic Super Resolution」(DSR)も,なかなか面白い。これは,いったん高解像度でレンダリングして,その後で低解像度にスーパーサンプリングして表示するというものだ。10年以上昔,3Dfxが「FSAA」(フルスクリーンアンチエイリアシング)として訴求していた高画質化レンダリング技法と,概念はよく似たものになっている。
いま概要だけ紹介したGM204の関連要素は,稿をあらためて詳しく解説したいと思う。
 |
4GamerのGeForce GTX 980&970レビュー記事
NVIDIAのGeForce製品情報ページ
- 関連タイトル:
 GeForce GTX 900
GeForce GTX 900 - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー