













ニュース
「Fermi」で,NVIDIAはどこへ向かうのか?
 |
GTC初日に開催された,NVIDIAの社長兼CEO,Jen-Hsun Huang(ジェンスン・フアン)氏の基調講演と,その後開かれた記者会見から,NVIDIAが目指す未来像を探っていこう。
グラフィックスの進化とともに
歩んできたNVIDIAが,次に目指すもの
 |
2001年にプログラマブルシェーダを実装したGeForce 3がリリースされると,それまでキューブマッピングの対応だけでも「ビジュアル的な大きな飛躍」とされてきた3Dグラフィックスは,描画品質を一気に向上させた。
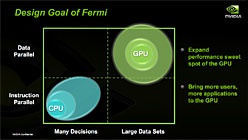
そして,2006年に登場したGeForce 8で「CUDA」(Compute Unified Device Architecture)による汎用コンピューティングの時代に突入。Huang氏は,Fermiの登場により,2010年には,第2ステージ「Computational GPU」(演算能力を持ったGPU)の時代に入ると見ている。
 2300万トランジスタを集積する「GeForce 256」でサポートされた「キューブマッピング」を活用する消防車のデモ。当時はそのクオリティの高さで評判になった |
 こちらは,6000万トランジスタを集積するGeForce 3のタイミングで作られた「Time Machine」デモ。新車が,時を経て錆びていく姿を,プログラマブルシェーダーを使って再現した |
 |
Huang氏は,Co-Processingのあり方として,「最高のCPUと最高のGPUの組み合わせが,最高のパフォーマンスを生む」として,シーケンシャル処理主体のプログラムと,パラレル処理主体のプログラムとでパフォーマンスを比較し,「Co-Processing時代には,処理ごとに最適なプロセッサを使い分けるべきだ」と主張した。
 |
 |
このメッセージが意図するものは明確だ。最速のグラフィックスチップを出し続ければ,NVIDIAはこのCo-Processing時代でも,業界をリードできる地位を譲らずに済む,というわけである。
NVIDIAにとって,Fermiは(CPUとGPUが異種混合していく時代ではなく)処理ごとに最適なプロセッサを使い分ける,Co-Processing時代をリードするコアとなるものだ。核分裂反応の研究などで知られ,原子炉の父とも言われるEnrico Fermi(エンリコ・フェルミ)氏から,次世代アーキテクチャの名前を拝借したのも,NVIDIAの姿勢の顕れといえるかもしれない。……余談だが,「Tesla」も,発明家Nikola Tesla(ニコラ・テスラ)氏の名から取られている。
 |
Huang氏は基調講演で,CUDAアプリケーションが,より身近になりつつある例として,2009年10月2日の記事で紹介した「ライブのビデオストリームに対するリアルタイムのCG合成&レイトレーシング処理」のデモとは別に,「ストリーミングによる,オフィス内装のレイトレーシング配信」というデモも披露した。これらの技術がゲームサーバーに応用されれば,MMOなどのオンラインゲームにおいて,(リアルタイムレイトレーシング,とまでは言わなくても)グラフィックス品質を大幅に引き上げることも不可能ではない。
 |
 |
そしてそのカギを握るのは,GTCのタイミングにおいて,NVIDIAが固く口を閉ざす,Fermiのグラフィックス機能,そしてDirectX 11対応だ。
明らかになるFermiの仕様。
グラフィックス製品は,「そう遠くない将来」に
 |
さらに,GT200までの世代では,すべてのSMが一つの「Global Instruction Cache」(グローバル命令キャッシュ)を使っていたのに対し,FermiではSMごとに独立した命令キャッシュとして設置されているのも特徴だ。
 |
 |
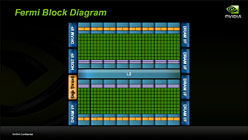 |
DirectX 11では,テッセレーション機能の実装により,バーテックスデータやジオメトリデータの使い回しが増える。そのときに,各SMがこれらのデータを素早く取り出せるキャッシュ構造を実装することは,DirectX 11のパフォーマンスアップにもつながるだろう。また,一度描画されたテクスチャに加工を加えるレンダーポストプロセシングのパフォーマンスを引き上げるうえでも,大容量のキャッシュ搭載は効果があるはずだ。
 |
NVIDIAは,GT200やG80アーキテクチャでも同様のアプローチを取り,シェーダークラスタ数を変更するなどして,ミドルクラス以下市場に向けて,コンパクトなサイズのGPUを生み出しているが,Fermiのダイ写真を見ると,これまでの製品以上に,各ブロックが整然と配置されていることが分かる。
このことは,L2キャッシュ容量の変更や,メモリコントローラ数の増減,そして,そのメモリコントローラに付随する形になっているであろう,ROPやテクスチャユニットの組み替えたり,数を増減させたりすることによって,よりグラフィックス性能を発揮しやすいチップを作ることが容易である可能性を感じさせる。
NVIDIAは,GTC初日の基調講演後に行われた報道関係者向けの会見でも,“Fermiベースのプロセッサ”や,派生するグラフィックス製品となるGeForce,Quadro両ファミリーの投入時期については明言を避けており,果たしてFermi世代が,具体的にいつ立ち上がるのかはまだ分からない。だがその一方,Huang氏は,「NVIDIAはグラフィックスビジネスを捨てて,ハイパフォーマンスコンピューティング製品に注力するのではないか」という噂に対しては,明確に否定。「グラフィックス関連製品は,今後もNVIDIAにとって重要なビジネスである」(Huang氏)として,GeForceなどの継続的な強化を約束していた。
その方向性の例として挙げられたのが,NVIDIA PhysXや3D Visionで,サポートしたゲームタイトルが増え続けており,最新ゲームタイトル「Batman: Arkham Asylum」は,その両機能をサポートするなど,ゲームやグラフィックスも常に進化しているとアピールした。Huang氏は,「HDテレビの次に来るのは,間違いなく3D立体視技術だ」と断言。3D立体視技術などを実現するソリューションとして,今後も,高性能なGPUの需要は伸び続けると見る。

 |
また,同社が開発中の次期IONプラットフォーム「ION2」は,IntelやVIAだけでなく,AMD製CPUなどにも,広く対応していく姿勢を見せるなど,PCプラットフォームの強化にも余念はない。
NVIDIAは,2009年末までには,Fermiアーキテクチャのグラフィックス環境について,さらなる情報公開を行う予定を持っているとのこと。次期GeForceシリーズの全貌が明らかになる日は,そう遠くはなさそうだ。
- 関連タイトル:
 GeForce GTX 400
GeForce GTX 400 - この記事のURL:
Copyright(C)2010 NVIDIA Corporation

4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー