















イベント
機械学習の分野で「Xeon Phi 7200番台」を武器にNVIDIAと対抗するIntel,その戦略を語る
 |
この数行の説明だけでも,ゲームとは何ら関係のないことが想像できると思うが,よく知られているとおり,機械学習はNVIDIAが総力を上げて取り組んでいる分野だ。そこで,業界の巨人となるIntelは何をしようとしているのか。今回はセッションのスピーカーである,IntelのHugo Saleh(ヒューゴ・サレー)氏による話を簡潔にまとめてみたいと思う。
第2世代Xeon Phiの性能やスケーラビリティはどれほどのものか
Intelは,2016年6月のスーパーコンピュータ関連国際会議「International Supercomputing Conference 2016」(ISC16)に合わせて,開発コードネーム「Knights Landing」(ナイツランディング)と呼ばれていた第2世代のHPC(High Performance Computing)向けプロセッサ「Xeon Phi 7200番台」を発表している。
Intelの機械学習に対する取り組みの中核をなすのは,このXeon Phi 7200番台だ。
ニューラルネットワークは,古典的な逐次実行型のCoreプロセッサやXeonプロセッサよりも,並列実行に特化したプロセッサのほうが実装しやすく,かつ性能が出る。そして,Intelのラインアップの中で並列実行に特化したプロセッサはXeon Phiシリーズしかないため,必然的にXeon Phiが主役になるのである。
なので,報道関係者向けセッションでSaleh氏はまずXeon Phi 7200番台の特徴をアピールし,その後,機械学習への取り組みを説明するといった流れでインテルの取り組みを語っていった。
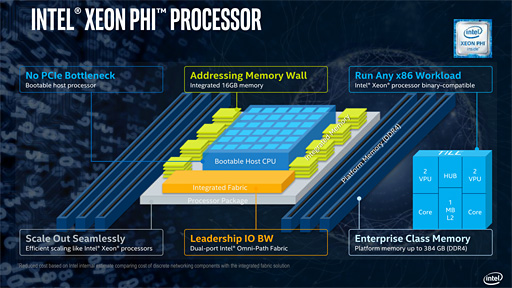
Xeon Phi 7200番台については2015年12月11日掲載の記事も参照してほしいが,Saleh氏はまず,「Xeon Phi(7200番台)はコプロセッサはない」という点から話を始めている。
 |
「Knights Corner」という開発コードネームで知られる第1世代Xeon Phiは,GPUと同じように,動作にはホストCPUが必要なコプロセッサだった。それに対してXeon Phi 7200番台はスタンドアロンで動作する。最小でも64基,最大72基という,圧倒的な数のプロセッサコアを集積した「CPU」として利用できるのである。
 |
Xeon Phi 7200番台の4製品はいずれも,初採用となるIntel独自のインターコネクト「Omni-Path Fabric」を統合したラインナップがあるので,合計では8モデル展開ということになる。
 |
 |
Xeon Phi 7200は,容量16GBの統合型メモリをオンパッケージで備えるのも大きな特徴だ。Saleh氏は「Micron TechnologyとIntelが共同で開発したもので,(この統合型メモリに)HBMの技術は使っていない」と述べている。DDR4メモリを積層したうえで,広帯域のバスでプロセッサコアと接続したものだそうだ。
 |
Saleh氏はこのXeon Phi 7200番台について「『SPECfp_rate2006』で世界記録を打ち立てたことをとくに強調しておきたい」とその性能をアピール。続けて,「Xeon Phi 7200番台は,発表時の6月の時点で(アーリーアクセスのユーザーに対して)3万ユニットを出荷した。2016年中には10万ユニットを出荷する計画だ」と,実数を上げながら順調な滑り出しを強調した。
 |
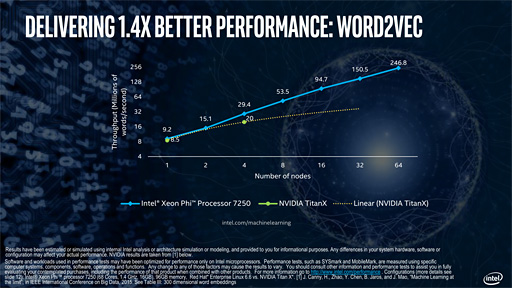
NVIDIAに挑戦する立場ということもあり,Saleh氏はライバルとなるGPUとの性能比較も示している。主にスケーラビリティに関する比較だが,いろいろと突っ込みどころは多い印象だ。
たとえば,下のスライドは文字認識を行う2層ニューラルネットワーク「Word2Vec」において,Xeon Phi 7250と「GeForce GTX TITAN X」を比較したものだが,いくらTITANシリーズといえども,コンシューマ向け製品を比較対象にするのはどうかという気がする。
 |
また,下はK近似法(KNN)という,画像認識などで使われているアルゴリズムにおけるスケーラビリティの比較だが,こちらでも比較対象としてデュアルGPUカード「GeForce GTX TITAN Z」を使っていたりする。こちらはDPフルスピードモードにも対応する,かなり数値演算プロセッサに近い製品なので,GeForce GTX TITAN Xとの比較よりはまだ納得できるが……。
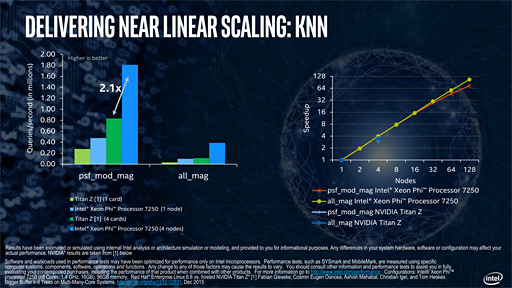 |
なぜGeForceとの比較になったかというと,NVIDIAが公開しているデータを引用したためとのことだった。つまり,実機ベースでの比較ではないとうわけだ。その妥当性はともかく,NVIDIAはPascalアーキテクチャを採用する「Tesla P100」を発表,発売済みなので,性能比較はあらためてなされるべきではなかろうかと思う。
むしろここで重要なのは,グラフに出ている数字よりも,グラフの説明にあたってSaleh氏が,Xeon Phi 7200番台では,GPUを利用することに伴う複雑さを解消できると繰り返していたことだろう。
Xeon Phi 7200番台はx86命令完全互換で,なおかつスタンドアロンで動作するため,特別なプログラミング言語,それこそCUDAのようなものは必要ない。そこがXeon Phi 7200番台の持つ最大の優位性というわけである。
オープンさとFPGAを推すIntelの機械学習戦略
さて,本題である。
Xeon Phi 7200番台を武器に,Intelは機械学習の分野でどのような戦略を描いているのか。その点でSaleh氏がまず強調したのが,オープンソースをベースにしたHPCに対するIntelの取り組みである。
Linux Foundationが中心となって立ち上げた,オープンなHPC向けのフレームワークの構築プロジェクトとして「OpenHPC」があるが,IntelはこれをXeon Phi 7200番台搭載システムへ容易にインストールできるよう拡張した開発フレームワーク「Intel HPC Orchestrator」を2016年第4四半期にリリースする計画だという。
 |
Intelの機械学習に対する取り組みも,この例と同じようなものになり,オープンソースコミュニティとの共同で,Xeon Phi 7200番台への最適化を進めていくとのことである。すでにディープラーニングのフレームワークである「Caffe」のXeon Phi向け最適化が完了しており,現在はGoogle製機械学習ライブラリ「TensorFlow」の最適化に取り組んでいる最中だそうだ。
現時点ですでにIntelは,機械学習に対して数千万ドルの投資を行っているが,これからも継続的に,積極的に投資を行っていくと,Saleh氏は述べている。
 |
もう1つ興味深いのは,機械学習に対するFPGA(Field-Programmable Gate Array,プログラム可能なロジックLSI)の応用にSaleh氏が触れていた点だ。「FPGAを使った機械学習に関しては,2016年11月の『SC16※』で具体的な発表を行う予定だ」という。
※スーパーコンピュータに関する国際会議の1つ
Intelは2015年に,FPGAの大手である米Alteraを買収しており,FPGAを自社製品戦略の1つとして加えつつある。「機械学習にFPGAを利用する」こと自体は,すでにいろいろなところでいろいろな取り組みがあるのだが,傘下にAlteraを抱えるIntelがここに乗り出してくるというのは,注目していいのではないかと思う。
ちなみにNVIDIAは,ARMベースのプロセッサである「Tegra X」1を使って,機械学習に基づく自動運転やロボットの自律行動への応用例を示したり,第2世代Maxwellベースの数値演算プロセッサであるTesla Mシリーズを使った認識の高速化を行ったりして,学習から認識までトータルにNVIDIA製品でサポートできることをアピールしている。
一方のIntelには,認識の部分をサポートできる製品がないように思えるが,その点をSaleh氏に聞いてみたところ「(Intelの)IoT製品を使った自動運転といったことにも取り組んでいく」という回答が得られた。
将来的には,IoT製品だけでなく,FPGAによる認識のハードウェアアクセラレーションを,ロボットや自動運転といった分野に持ち込んでくる可能性もあるだろう。FPGA vs. GPUといった図式になるといろいろと面白そうだが,機械学習の分野でもNVIDIAとIntelの間では熾烈な戦いが繰り広げられることになりそうだ。
IntelのXeon Phi製品情報ページ(英語)
- 関連タイトル:
 Xeon Phi
Xeon Phi - この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー