














イベント
SCEEのPhyreEngine開発者が注目するDirectX 11レベルのグラフィックス技術。ボリューム空間におけるプロシージャル形状処理の考察
 |
さて,講演タイトルからは「SCEなのにDirectX?」というあたりが気にかかるのだが,今回の講演は,現行のPlayStation 3やPlayStation VitaといったSCE製品とは,直接の関係はない話だ。最新世代のリアルタイムグラフィックス技術を研究しようとすると,現時点ではDirectX 11かOpenGL 4.0のどちらかにスポットを当てざるを得ない。R&D部門なら次世代技術を把握しておくことは当然であり,実際の製品に反映されることがあるかどうかは別の話だ(とくに今回は“デモ用”と断ったうえで講演を開始している)。とはいえ,SCEのゲームエンジン開発のトップがどのような研究を行っているかというのは,注目されてしかるべき情報だろう。
 |
 |
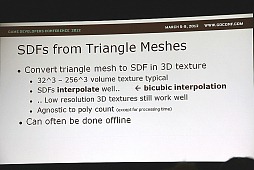
SDFとは,ボリューム表現法の一つで,3次元配列に物体の内部と外部で符号を変えたデータを格納したものとなる。この形式でデータを作成しておき,0の等値面を追うと表面形状が生成できる。界面の推定で補間が行われる分,単純なボクセルより精度は高いという見方もできる。スヴォボダ氏は「SDFは加工がしやすく,プロシージャルなオブジェクト生成に使いやすい形式」だとしている。
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
また,複数のオブジェクトを扱う場合は,それぞれ独立したオブジェクトを「3Dテクスチャ」として定義しておいて,空間に貼り込んでいくような感じの運用となりそうだ。
 |
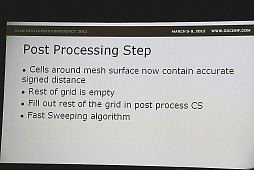
SDFは空間における物体の内側/外側を示しただけのデータなので,普通のポリゴンデータやパーティクルなどからも変換できるのだが,単純にやると処理に時間がかかり,かといってボクセルに落としてから均(なら)すような作業では精度が大きく落ちる。そこで……と,以下のスライドのように,ある程度の精度を保って変換する手法が紹介されていた。
 |
 |
 |
 |
 |
 |
次にパーティクルの場合。
パーティクルにもいろいろあるが,ここではポテンシャル(電荷のようなもの)を持った密度球として表現されるものが想定されている。この場合は,一定の密度値を界面とみなしてメタボールのような立体を定義し,内側と外側を決めていけばいい。
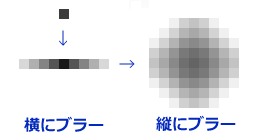 |
この方法は「完全に正確」というわけではないが,多くの場合で問題は出ないようだ。適切に処理すれば,GeForce GTX 570で200ms以上かかっていた処理が,この方法だと2msで済むという。
 |
 |
 |
 |
物体のSDF化の次は,表示法の解説が行われた。
ボリュームで定義されたオブジェクトを3D表示する場合,レイキャスティングなどが使われることが多いのだが,講演ではSDFで表現されたデータをレイトレーシング(の簡略版的なレイキャスティング)で表示する方法と,ポリゴン化する方法の2種類が示されていた。
レイキャスティングは,視点から表示するスクリーン上のピクセルに向かって1次レイを飛ばし,それがどこかの界面のあるグリッドに到達したら,そのグリッド周辺の界面情報からピクセルの内容を計算していくような流れとなる。ボリュームの表面に到達したと判断されたら,その点から複数の2次レイを飛ばして遮蔽状況を調べて明度を決定する。この手法では,1次レイの部分である程度の精度が必要なので,高速化は難しいとしている。
 |
 |
一方のポリゴン化にはマーチングキューブ法が適用されていた。マーチングキューブ法は,「ボリュームの可視化」において多用される手法である。隣接するボクセルの状態に応じたパターンのポリゴンを割り当てることで,高速に近似ポリゴンを生成しようというアルゴリズムだ。
マーチングキューブ法は一般的なアルゴリズムではあるが,問題点として「すべてのグリッドに対して行うと処理時間がかかる」ことなどが挙げられ,通常はCPUで処理されるマーチングキューブ法をジオメトリシェーダで処理した実験について報告された。結果はまずまずで,氏曰く「遅すぎるということはない」という,10ms〜200msでの実行時間になるとのこと。
 |
 |
 |
 |
 |
そこで,データのある部分だけ詰めて処理する方法がいくつか示された。その中にあった,HistoPyramidなどは解像度を落とした配列に要素の合計値を入れていく手法で,効率よくポテンシャルの低い部分をスキップできそうである。
 |
 |
処理を行う際,グリッドごとにすべてのパーティクルが入っているかどうかテストする部分は負荷が高い。グリッドが有限個であれば,バケットソートでパーティクルを並べ直して調べるのが効率が良いのだが,前述のとおり,パーティクルは均一なポテンシャルのものとみなしているので,どこにどのパーティクルが入っているかは重要ではなく,単にどこに何個入っているかが分かればいい。そこで使われるのがカウンティングソートだ。グリッドごとにパーティクルの個数だけを記録していくというわけである。
 |
 |
そんなこんなの下準備を行って,ポリゴン分割を実装した出力例が示された。16回反復(16パス)したものは非常に滑らかになっていることが分かる。パフォーマンスについては,ジオメトリシェーダの力技で組んだプログラムの場合,GeForce GTX 570では1パスごとに11ms,16パスでは176msとなる。これをコンピュートシェーダで実装した場合,「2ms+パスごとに0.4ms」で済んだとのこと。つまり16パスなら8.4msとなる。
 |
 |
 |
 |
これを実装したパーティクルに物理演算を加えたものがアニメーションで示された。これは流体力学そのものであるという。
 |
 |
 |
 |
 |
 |
 |
曰く,次世代の照明システムでは,1次レイについてはラスタライズ,2次レイについてはトレースが使われるだろうとの見解を示していた。
現在のゲームでもアンビエントオクルージョンによる遮蔽の陰影などは,レイトレース(的なもの)を使って高品質な結果を得られるようになってきているが,そういった路線の延長上で,進んでいくというのが氏の読みだ。まあ,どちらかというと「将来のレンダリングシステム」ではなく,「PCにおける現状の最先端レンダリングシステム」ではないかという気もしなくはないのだが。
 |
 |
いずれにしても大体の形状はポリゴンで表現し,陰影はレイトレースで行うことで,リアルな陰影処理を高速に実現できるのは確かだ。とはいえ,レイトレースも,むやみに行っているとリアルタイム描画ができなくなるということで,スヴォボダ氏はどの程度のバランスで行えばよいかについての実験を行っている。実験から,以下のような4レイから256レイまでのレンダリング例が示された。
 |
 |
 |
ランダムに4方向にレイを飛ばして陰影をつけた場合,高速だが画像は粗い。64レイ以上を飛ばすと品質も安定してくるが,もちろんそれだけ重くなる。
ここで品質を上げるために持ち出されたのがTemporal Reprojectionという技術である。すでに「Gears of War 2」などで実用化されている技術だが,要は,前のフレームでの結果をできるだけ流用しようというものだ。
 |
 |
 |
大雑把に言うと,前のフレームと位置や向きなどが大きく変わっていない場合は,飛ばすのは1レイだけにして前の結果に加え,大きく違っていた場合は前の結果は流用しない。そうすると,前と違っていた場合に穴が開くことになるので,流用しないときには16レイを飛ばすようにする。これがとりあえず示された解決策だ。
しかし,それで発生する問題もある。前のデータを流用できないときの負荷が高くなって,マルチスレッド処理がスムーズに流れなくなることである。
ここで持ち出されたのが,バランスレイという考え方だ。16×16ピクセルのブロック単位で処理を行い,穴が空いた部分に適用するレイについては,ブロック単位で16レイに留めることで効率化を図るというもののようだ。
 |
 |
 |
 |
そんなこんなで,SDFベースのジオメトリを追加し,さまざまな処理を加えることで,ゲーム世界はもっともっとダイナミックなものにできるというのがスヴォボダ氏の見解である。次世代レンダリングシステムについては,まだ決定的なものが現れていないというのが実情だが,SDFベースのボリュームレンダリングがどんな可能性を持つのかは,今回の講演から窺えるのではないだろうか。
 |
 |
- この記事のURL:
4Gamer.net最新情報
プラットフォーム別新着記事
総合新着記事
企画記事
新着連載
新着レビュー
新着インタビュー